前言
- CTDB cluster中存在多个节点时,各个节点如何发现对方,和对方建立连接,
- 当某个节点关闭CTDB 服务的时候,正常节点如何探测到该节点CTDB服务已经退出
- 当某个节点crash,CTDB猝死,来不及说goodbye,正常节点的CTDB如何探测到该节点已经死亡
- 当死去的CTDB节点重启服务,正常节点如何重建连接,时效性如何,本文解决这些问题。
谁是我们的伙伴
毛主席说,谁是我们的朋友,谁是我们的敌人,这是首先要解决的问题。同样道理,CTDB中,集群里面有几个节点,这是首先要解决的问题。
对于CTDB集群而言,这个配置文件位于:
root@node1:~# cat /etc/ctdb/nodes
10.10.10.3
10.10.10.2
10.10.10.1
ctdbd daemon 在启动的早期,就会调用下面函数来获得所有的CTDB node的IP。
/* tell ctdb what nodes are available */
ctdb_load_nodes_file(ctdb);
下面我们看下该函数的实现:
void ctdb_load_nodes_file(struct ctdb_context *ctdb)
{
int ret;
ret = ctdb_set_nlist(ctdb, options.nlist);
if (ret == -1) {
DEBUG(DEBUG_ALERT,("ctdb_set_nlist failed - %s\n", ctdb_errstr(ctdb)));
exit(1);
}
}
int ctdb_set_nlist(struct ctdb_context *ctdb, const char *nlist)
{
char **lines;
int nlines;
int i, j, num_present;
talloc_free(ctdb->nodes);
ctdb->nodes = NULL;
ctdb->num_nodes = 0;
lines = file_lines_load(nlist, &nlines, ctdb);
if (lines == NULL) {
ctdb_set_error(ctdb, "Failed to load nlist '%s'\n", nlist);
return -1;
}
while (nlines > 0 && strcmp(lines[nlines-1], "") == 0) {
nlines--;
}
num_present = 0;
for (i=0; i < nlines; i++) {
char *node;
node = lines[i];
/* strip leading spaces */
while((*node == ' ') || (*node == '\t')) {
node++;
}
if (*node == '#') {
/*一般来讲删除一个节点,最好使用#注释掉,
* 好处时,大部分其他的节点对应的PNN号不变*/
if (ctdb_add_deleted_node(ctdb) != 0) {
talloc_free(lines);
return -1;
}
continue;
}
/*空行忽略*/
if (strcmp(node, "") == 0) {
continue;
}
/*正常的节点,是CTDB cluster的成员*/
if (ctdb_add_node(ctdb, node) != 0) {
talloc_free(lines);
return -1;
}
/*删除的节点就不计入num_present*/
num_present++;
}
/* initialize the vnn mapping table now that we have the nodes list,
skipping any deleted nodes
*/
ctdb->vnn_map = talloc(ctdb, struct ctdb_vnn_map);
CTDB_NO_MEMORY(ctdb, ctdb->vnn_map);
ctdb->vnn_map->generation = INVALID_GENERATION;
ctdb->vnn_map->size = num_present;
ctdb->vnn_map->map = talloc_array(ctdb->vnn_map, uint32_t, ctdb->vnn_map->size);
CTDB_NO_MEMORY(ctdb, ctdb->vnn_map->map);
for(i=0, j=0; i < ctdb->vnn_map->size; i++) {
if (ctdb->nodes[i]->flags & NODE_FLAGS_DELETED) {
continue;
}
ctdb->vnn_map->map[j] = i;
j++;
}
talloc_free(lines);
return 0;
}
上述的代码其实可以分成三部分,
- 用# 注释掉的node,调用 ctdb_add_deleted_node函数
static int ctdb_add_deleted_node(struct ctdb_context *ctdb)
{
struct ctdb_node *node, **nodep;
nodep = talloc_realloc(ctdb, ctdb->nodes, struct ctdb_node *, ctdb->num_nodes+1);
CTDB_NO_MEMORY(ctdb, nodep);
ctdb->nodes = nodep;
nodep = &ctdb->nodes[ctdb->num_nodes];
(*nodep) = talloc_zero(ctdb->nodes, struct ctdb_node);
CTDB_NO_MEMORY(ctdb, *nodep);
node = *nodep;
/*该节点是删除掉的节点,因此,用0.0.0.0这种没有意义的IP指代它*/
if (ctdb_parse_address(ctdb, node, "0.0.0.0", &node->address) != 0) {
DEBUG(DEBUG_ERR,("Failed to setup deleted node %d\n", ctdb->num_nodes));
return -1;
}
node->ctdb = ctdb;
/*node的name也设置成0.0.0.0:0这种无意义的值*/
node->name = talloc_strdup(node, "0.0.0.0:0");
/* this assumes that the nodes are kept in sorted order, and no gaps */
node->pnn = ctdb->num_nodes;
/* 设置上NODE_FLAGS_DELETED标志位,表示该node已被删除 */
node->flags = NODE_FLAGS_DELETED|NODE_FLAGS_DISCONNECTED;
ctdb->num_nodes++;
node->dead_count = 0;
return 0;
}
注意上面的delete node 的处理方式和下面正常node的处理方式的比较
- 正常node, 调用ctdb_add_node
static int ctdb_add_node(struct ctdb_context *ctdb, char *nstr)
{
struct ctdb_node *node, **nodep;
nodep = talloc_realloc(ctdb, ctdb->nodes, struct ctdb_node *, ctdb->num_nodes+1);
CTDB_NO_MEMORY(ctdb, nodep);
ctdb->nodes = nodep;
nodep = &ctdb->nodes[ctdb->num_nodes];
(*nodep) = talloc_zero(ctdb->nodes, struct ctdb_node);
CTDB_NO_MEMORY(ctdb, *nodep);
node = *nodep;
if (ctdb_parse_address(ctdb, node, nstr, &node->address) != 0) {
return -1;
}
node->ctdb = ctdb;
node->name = talloc_asprintf(node, "%s:%u",
node->address.address,
node->address.port);
/* this assumes that the nodes are kept in sorted order, and no gaps */
node->pnn = ctdb->num_nodes;
/* nodes start out disconnected and unhealthy */
node->flags = (NODE_FLAGS_DISCONNECTED | NODE_FLAGS_UNHEALTHY);
if (ctdb->address.address &&
ctdb_same_address(&ctdb->address, &node->address)) {
/* for automatic binding to interfaces, see tcp_connect.c */
ctdb->pnn = node->pnn;
node->flags &= ~NODE_FLAGS_DISCONNECTED;
/* do we start out in DISABLED mode? */
if (ctdb->start_as_disabled != 0) {
DEBUG(DEBUG_INFO, ("This node is configured to start in DISABLED state\n"));
node->flags |= NODE_FLAGS_DISABLED;
}
/* do we start out in STOPPED mode? */
if (ctdb->start_as_stopped != 0) {
DEBUG(DEBUG_INFO, ("This node is configured to start in STOPPED state\n"));
node->flags |= NODE_FLAGS_STOPPED;
}
}
ctdb->num_nodes++;
node->dead_count = 0;
return 0;
}
我们比较一下添加删除节点和添加正常节点的代码,发现无论是已删除节点还是正常节点,都会记录再ctdb->nodes数组中,每个节点都有一个PNN号,这个号码的值即对应节点在 /etc/ctdb/nodes中的行号。
但是对于正常节点,我们会解析得到其IP和port, IP:port作为该节点的名字node->name 。 另外一个不同点在于,已经删除的节点,其标志位flags中 NODE_FLAGS_DELETED置位,而正常节点并无该标志位。
- 创建vnn_map
已经删除的节点并不会计入vnnmap,因此下面会有continue跳过那些已经被删除的节点。
ctdb->vnn_map = talloc(ctdb, struct ctdb_vnn_map);
CTDB_NO_MEMORY(ctdb, ctdb->vnn_map);
ctdb->vnn_map->generation = INVALID_GENERATION;
/*注意,已经删除的节点是不会计入其中的,size为num_present*/
ctdb->vnn_map->size = num_present;
ctdb->vnn_map->map = talloc_array(ctdb->vnn_map, uint32_t, ctdb->vnn_map->size);
CTDB_NO_MEMORY(ctdb, ctdb->vnn_map->map);
for(i=0, j=0; i < ctdb->vnn_map->size; i++) {
if (ctdb->nodes[i]->flags & NODE_FLAGS_DELETED) {
continue;
}
ctdb->vnn_map->map[j] = i;
j++;
}
注意,我们删除一个节点的时候,使用注释有另一层好处,即热更新,退出的节点自然魂归大地,但是只需要加入一个#号,然后调用ctdb reloadnodes 去通知其他正常节点重新加载node配置。这种方式下,各个node的PNN号并无变化。
做好准备,等待其他节点来连
定义好了谁是我们的伙伴之后,后面就可以做准备工作等待别人来连了。那么准备工作有哪些,什么时机做的呢?
一图胜千言,请看下面的图:
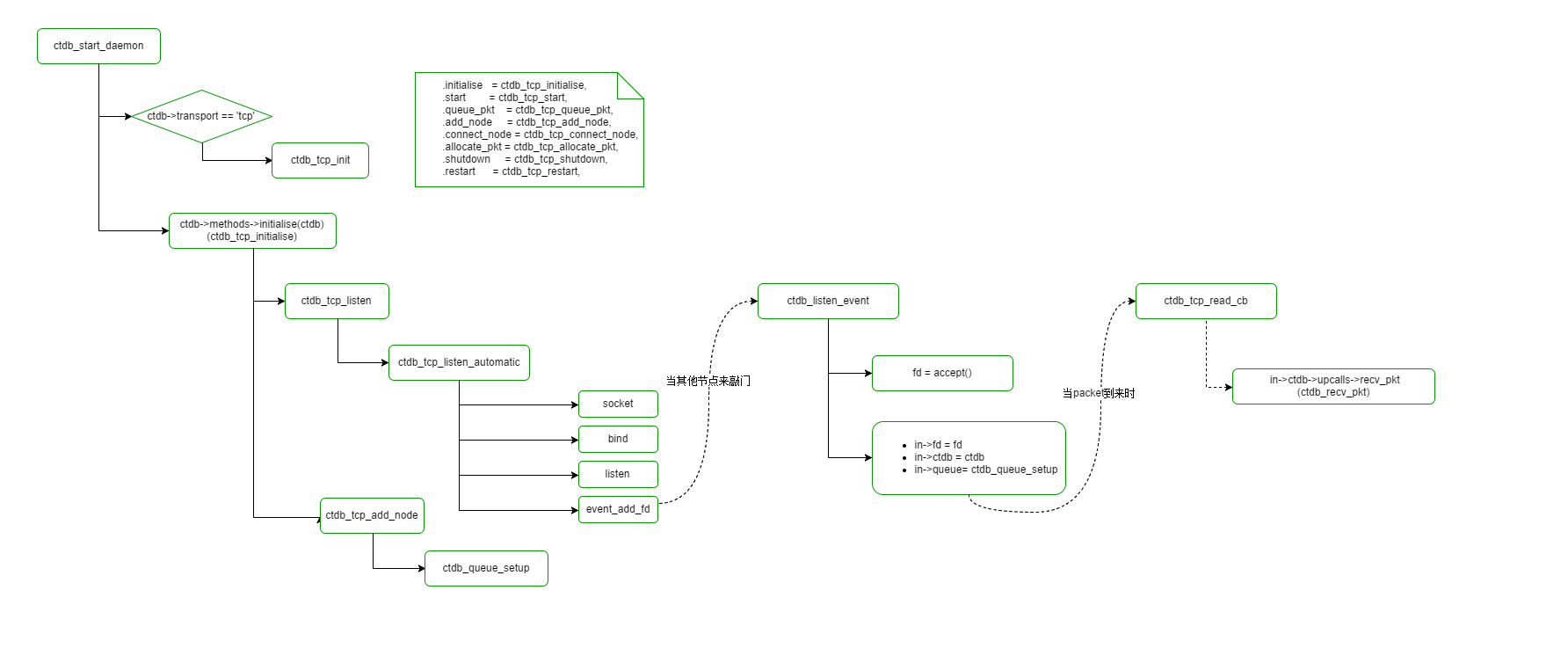
因为大部分情况下,我们transport 为tcp,因此,网络层的实作为tcp,因此initialize调用的是:
static const struct ctdb_methods ctdb_tcp_methods = {
.initialise = ctdb_tcp_initialise,
.start = ctdb_tcp_start,
.queue_pkt = ctdb_tcp_queue_pkt,
.add_node = ctdb_tcp_add_node,
.connect_node = ctdb_tcp_connect_node,
.allocate_pkt = ctdb_tcp_allocate_pkt,
.shutdown = ctdb_tcp_shutdown,
.restart = ctdb_tcp_restart,
};
调用的是ctdb_tcp_initialise:
static int ctdb_tcp_initialise(struct ctdb_context *ctdb)
{
int i;
/* listen on our own address */
if (ctdb_tcp_listen(ctdb) != 0) {
DEBUG(DEBUG_CRIT, (__location__ " Failed to start listening on the CTDB socket\n"));
exit(1);
}
for (i=0; i < ctdb->num_nodes; i++) {
if (ctdb->nodes[i]->flags & NODE_FLAGS_DELETED) {
continue;
}
if (ctdb_tcp_add_node(ctdb->nodes[i]) != 0) {
DEBUG(DEBUG_CRIT, ("methods->add_node failed at %d\n", i));
return -1;
}
}
return 0;
}
注意上面的代码分成 两个部分
- ctdb_tcp_listen 其实可以顾名思义了,就是说准备好网络,等待其他节点主动来连。
- ctdb_tcp_add_node 此处只是一个准备工作,其实这一部分是为了连其他节点做准备的。
很有意思的是地方时第一步 是被动的,张好网,等别人来连我,第二步是主动的,我要主动连其他节点,此后面的详细分析中可以看出来。
ctdb_tcp_listen
int ctdb_tcp_listen(struct ctdb_context *ctdb)
{
struct ctdb_tcp *ctcp = talloc_get_type(ctdb->private_data,
struct ctdb_tcp);
ctdb_sock_addr sock;
int sock_size;
int one = 1;
struct tevent_fd *fde;
/* we can either auto-bind to the first available address, or we can
use a specified address */
if (!ctdb->address.address) {
return ctdb_tcp_listen_automatic(ctdb);
}
...
}
注意,ctdb刚开始启动的时候,虽然有了所有节点的信息 (通过ctdb->nodes数组),但是其实并没有设置自己的address,即ctdb->address.adress 是为空,这时候,走的是ctdb_tcp_listen_automatic。
static int ctdb_tcp_listen_automatic(struct ctdb_context *ctdb)
{
struct ctdb_tcp *ctcp = talloc_get_type(ctdb->private_data,
struct ctdb_tcp);
ctdb_sock_addr sock;
int lock_fd, i;
const char *lock_path = "/tmp/.ctdb_socket_lock";
struct flock lock;
int one = 1;
int sock_size;
struct tevent_fd *fde;
/* in order to ensure that we don't get two nodes with the
same adddress, we must make the bind() and listen() calls
atomic. The SO_REUSEADDR setsockopt only prevents double
binds if the first socket is in LISTEN state */
lock_fd = open(lock_path, O_RDWR|O_CREAT, 0666);
if (lock_fd == -1) {
DEBUG(DEBUG_CRIT,("Unable to open %s\n", lock_path));
return -1;
}
lock.l_type = F_WRLCK;
lock.l_whence = SEEK_SET;
lock.l_start = 0;
lock.l_len = 1;
lock.l_pid = 0;
/*排它锁,防止竞争*/
if (fcntl(lock_fd, F_SETLKW, &lock) != 0) {
DEBUG(DEBUG_CRIT,("Unable to lock %s\n", lock_path));
close(lock_fd);
return -1;
}
上面这一段没啥好说的,加一个锁,防止竞争。
/*此处是一个for循环,也就是说,ctdb->nodes中记录了所有的node IP,for循环会挨个尝试,
* 它会尝试bind这些IP,对于如果这个IP不属于这个节点,那么bind就会失败,没关系尝试下一个
* 知道bind成功之后,break*/
for (i=0; i < ctdb->num_nodes; i++) {
if (ctdb->nodes[i]->flags & NODE_FLAGS_DELETED) {
continue;
}
/* if node_ip is specified we will only try to bind to that
ip.
*/
if (ctdb->node_ip != NULL) {
if (strcmp(ctdb->node_ip, ctdb->nodes[i]->address.address)) {
continue;
}
}
ZERO_STRUCT(sock);
if (ctdb_tcp_get_address(ctdb,
ctdb->nodes[i]->address.address,
&sock) != 0) {
continue;
}
switch (sock.sa.sa_family) {
case AF_INET:
sock.ip.sin_port = htons(ctdb->nodes[i]->address.port);
sock_size = sizeof(sock.ip);
break;
case AF_INET6:
sock.ip6.sin6_port = htons(ctdb->nodes[i]->address.port);
sock_size = sizeof(sock.ip6);
break;
default:
DEBUG(DEBUG_ERR, (__location__ " unknown family %u\n",
sock.sa.sa_family));
continue;
}
#ifdef HAVE_SOCK_SIN_LEN
sock.ip.sin_len = sock_size;
#endif
ctcp->listen_fd = socket(sock.sa.sa_family, SOCK_STREAM, IPPROTO_TCP);
if (ctcp->listen_fd == -1) {
ctdb_set_error(ctdb, "socket failed\n");
continue;
}
set_close_on_exec(ctcp->listen_fd);
setsockopt(ctcp->listen_fd,SOL_SOCKET,SO_REUSEADDR,(char *)&one,sizeof(one));
if (bind(ctcp->listen_fd, (struct sockaddr * )&sock, sock_size) == 0) {
break;
}
if (errno == EADDRNOTAVAIL) {
DEBUG(DEBUG_DEBUG,(__location__ " Failed to bind() to socket. %s(%d)\n",
strerror(errno), errno));
} else {
DEBUG(DEBUG_ERR,(__location__ " Failed to bind() to socket. %s(%d)\n",
strerror(errno), errno));
}
}
注意,如果打开DEBUG开关 (ctdb setdebug DEBUG), 在启动过程中会开到如下log
2017/05/22 11:19:09.172119 [461730]: tcp/tcp_connect.c:362 Failed to bind() to socket. Cannot assign requested address(99)
2017/05/22 11:19:09.172155 [461730]: ctdb chose network address 10.11.12.2:4379 pnn 1
这是因为bind采用了神农尝百草的思路,ctdb->nodes中的IP挨个尝试bind,如果bind不成功,就试试下一个IP。当IP试对了,就break。
然后我们看这个函数的后续部分:
if (i == ctdb->num_nodes) {
DEBUG(DEBUG_CRIT,("Unable to bind to any of the node addresses - giving up\n"));
goto failed;
}
/*注意,直到此时,ctdb->address.address 才不是NULL,
*回想ctdb_tcp_listen函数你开头,一上来就判断这个值是不是NULL*/
ctdb->address.address = talloc_strdup(ctdb, ctdb->nodes[i]->address.address);
ctdb->address.port = ctdb->nodes[i]->address.port;
/*ctdb->name 一般是这样的 10.11.12.2:4379*/
ctdb->name = talloc_asprintf(ctdb, "%s:%u",
ctdb->address.address,
ctdb->address.port);
ctdb->pnn = ctdb->nodes[i]->pnn;
ctdb->nodes[i]->flags &= ~NODE_FLAGS_DISCONNECTED;
DEBUG(DEBUG_INFO,("ctdb chose network address %s:%u pnn %u\n",
ctdb->address.address,
ctdb->address.port,
ctdb->pnn));
/* do we start out in DISABLED mode? */
if (ctdb->start_as_disabled != 0) {
DEBUG(DEBUG_INFO, ("This node is configured to start in DISABLED state\n"));
ctdb->nodes[i]->flags |= NODE_FLAGS_DISABLED;
}
/* do we start out in STOPPED mode? */
if (ctdb->start_as_stopped != 0) {
DEBUG(DEBUG_INFO, ("This node is configured to start in STOPPED state\n"));
ctdb->nodes[i]->flags |= NODE_FLAGS_STOPPED;
}
/*listen很重要,表示我开始开大门等待生意上门了。*/
if (listen(ctcp->listen_fd, 10) == -1) {
goto failed;
}
/*CTDB使用epoll,同时了事件源,无论你是定时任务timer,还是文件描述符,还是信号,
*统统用epoll来管理,这里面有注册收到事件后的函数,
*即非常重要的ctdb_listen_event函数*/
fde = event_add_fd(ctdb->ev, ctcp, ctcp->listen_fd, EVENT_FD_READ,
ctdb_listen_event, ctdb);
tevent_fd_set_auto_close(fde);
close(lock_fd);
return 0;
failed:
close(lock_fd);
close(ctcp->listen_fd);
ctcp->listen_fd = -1;
return -1;
}
此时,socket也建了,bind也成功了,listen也开始了,就是打开大门做生意了,但是生意不知道何时才上门,所以用了epoll,监控其他node是否发connect,如果其他node发了connect,就会调用ctdb_listen_event处理之。
下面看下ctdb_listen_event函数你实现:
static void ctdb_listen_event(struct event_context *ev, struct fd_event *fde,
uint16_t flags, void *private_data)
{
struct ctdb_context *ctdb = talloc_get_type(private_data, struct ctdb_context);
struct ctdb_tcp *ctcp = talloc_get_type(ctdb->private_data, struct ctdb_tcp);
ctdb_sock_addr addr;
socklen_t len;
int fd, nodeid;
/*ctdb_incoming 这个名字非常有意思,很明确表明,这是其他节点主动连我们,是incoming
*后面我们主动连其他节点是outqueue,名字也很有意思*/
struct ctdb_incoming *in;
int one = 1;
const char *incoming_node;
memset(&addr, 0, sizeof(addr));
len = sizeof(addr);
/*来者都是客,我们accept*/
fd = accept(ctcp->listen_fd, (struct sockaddr *)&addr, &len);
if (fd == -1) return;
/*从addr中获取IP,然后从ctdb->nodes中找,是不是我们的伙伴,如果不是,拒绝之*/
incoming_node = ctdb_addr_to_str(&addr);
nodeid = ctdb_ip_to_nodeid(ctdb, incoming_node);
if (nodeid == -1) {
DEBUG(DEBUG_ERR, ("Refused connection from unknown node %s\n", incoming_node));
close(fd);
return;
}
in = talloc_zero(ctcp, struct ctdb_incoming);
in->fd = fd;
in->ctdb = ctdb;
set_nonblocking(in->fd);
set_close_on_exec(in->fd);
DEBUG(DEBUG_DEBUG, (__location__ " Created SOCKET FD:%d to incoming ctdb connection - %s\n", fd, incoming_node));
setsockopt(in->fd,SOL_SOCKET,SO_KEEPALIVE,(char *)&one,sizeof(one));
in->queue = ctdb_queue_setup(ctdb, in, in->fd, CTDB_TCP_ALIGNMENT,
ctdb_tcp_read_cb, in, "ctdbd-%s", incoming_node);
}
注意,连接进来的node,需要先辨识身份,获得其IP,然后根据ctdb->nodes数组,判断是不是我们的伙伴,如果不是,拒绝之。
相关的log如下:
2017/05/22 11:54:08.002867 [995627]: tcp/tcp_connect.c:261 Created SOCKET FD:24 to incoming ctdb connection - 10.11.12.3
(注意,源码中并未没有打印对端的IP,但是我修改了代码,添加了IP信息,读者不要困扰)
如果是的话,分配ctdb_incoming, 然后设置fd,设置ctdb。最重要的是queue。 连接建立之后,用于通信,因此会调用ctdb_tcp_read_cb,此处我们就不展开了。
注意,这一大片是做好准备,等其他节点来连, 下面介绍如何主动连接其他节点。相当于介绍完阴面,介绍阳面。
连接其他伙伴
对于CTDB,我们会发现,一下问题,如果某个节点执行service ctdb stop,其他节点几乎立刻能感知到:
2017/05/22 14:30:11.180802 [995627]: 10.11.12.2:4379: node 10.11.12.3:4379 is dead: 1 connected
2017/05/22 14:30:11.180869 [995627]: Tearing down connection to dead node :0
而死掉的节点,重启ctdb服务之后,本节点几乎立刻就能建立和该节点的连接。这是为何。
我们先来介绍介绍正常情况下,如何主动出击,连接其他节点,然后介绍两种异常情况下(CTDB正常退出和异常死亡),当对端节点回来,本地节点如何快速发现并建立连接。
正常主动出击,建立连接
下面先看流程图:
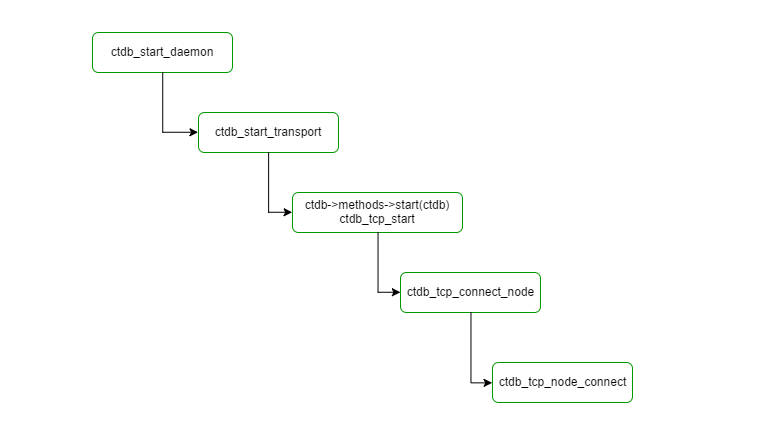
我们的起始点就是ctdb_tcp_start函数:
static int ctdb_tcp_start(struct ctdb_context *ctdb)
{
int i;
for (i=0; i < ctdb->num_nodes; i++) {
if (ctdb->nodes[i]->flags & NODE_FLAGS_DELETED) {
continue;
}
ctdb_tcp_connect_node(ctdb->nodes[i]);
}
return 0;
}
可以看出来,对于任何节点,只要还没有被删除,就要调用ctdb_tcp_connect_node,这里面就有一个问题了,自己会连自己么?
不会,这个是做在ctdb_tcp_connect_node里面。
static int ctdb_tcp_connect_node(struct ctdb_node *node)
{
struct ctdb_context *ctdb = node->ctdb;
struct ctdb_tcp_node *tnode = talloc_get_type(
node->private_data, struct ctdb_tcp_node);
/* startup connection to the other server - will happen on
next event loop */
/*注意,自己不会连自己,是要连CTDB cluster内的其他节点*/
if (!ctdb_same_address(&ctdb->address, &node->address)) {
tnode->connect_te = event_add_timed(ctdb->ev, tnode,
timeval_zero(),
ctdb_tcp_node_connect, node);
}
return 0;
}
设置了定时任务,在下一个loop中会即时触发,调用ctdb_tcp_node_connect。
这个ctdb_tcp_node_connect非常重要,无论是初次连接,还是其他节点的CTDB死而复活,都靠这个函数去建立连接。
void ctdb_tcp_node_connect(struct event_context *ev, struct timed_event *te,
struct timeval t, void *private_data)
{
struct ctdb_node *node = talloc_get_type(private_data,
struct ctdb_node);
struct ctdb_tcp_node *tnode = talloc_get_type(node->private_data,
struct ctdb_tcp_node);
struct ctdb_context *ctdb = node->ctdb;
ctdb_sock_addr sock_in;
int sockin_size;
int sockout_size;
ctdb_sock_addr sock_out;
/*断掉连接*/
ctdb_tcp_stop_connection(node);
ZERO_STRUCT(sock_out);
#ifdef HAVE_SOCK_SIN_LEN
sock_out.ip.sin_len = sizeof(sock_out);
#endif
if (ctdb_tcp_get_address(ctdb, node->address.address, &sock_out) != 0) {
return;
}
switch (sock_out.sa.sa_family) {
case AF_INET:
sock_out.ip.sin_port = htons(node->address.port);
break;
case AF_INET6:
sock_out.ip6.sin6_port = htons(node->address.port);
break;
default:
DEBUG(DEBUG_ERR, (__location__ " unknown family %u\n",
sock_out.sa.sa_family));
return;
}
/*创建socket*/
tnode->fd = socket(sock_out.sa.sa_family, SOCK_STREAM, IPPROTO_TCP);
set_nonblocking(tnode->fd);
set_close_on_exec(tnode->fd);
DEBUG(DEBUG_DEBUG, (__location__ " Created TCP SOCKET FD:%d\n", tnode->fd));
/* Bind our side of the socketpair to the same address we use to listen
* on incoming CTDB traffic.
* We must specify this address to make sure that the address we expose to
* the remote side is actually routable in case CTDB traffic will run on
* a dedicated non-routeable network.
*/
ZERO_STRUCT(sock_in);
if (ctdb_tcp_get_address(ctdb, ctdb->address.address, &sock_in) != 0) {
DEBUG(DEBUG_ERR, (__location__ " Failed to find our address. Failing bind.\n"));
close(tnode->fd);
return;
}
/* AIX libs check to see if the socket address and length
arguments are consistent with each other on calls like
connect(). Can not get by with just sizeof(sock_in),
need sizeof(sock_in.ip).
*/
switch (sock_in.sa.sa_family) {
case AF_INET:
sockin_size = sizeof(sock_in.ip);
sockout_size = sizeof(sock_out.ip);
break;
case AF_INET6:
sockin_size = sizeof(sock_in.ip6);
sockout_size = sizeof(sock_out.ip6);
break;
default:
DEBUG(DEBUG_ERR, (__location__ " unknown family %u\n",
sock_in.sa.sa_family));
close(tnode->fd);
return;
}
#ifdef HAVE_SOCK_SIN_LEN
sock_in.ip.sin_len = sockin_size;
sock_out.ip.sin_len = sockout_size;
#endif
/*bind 到自己的地址*/
bind(tnode->fd, (struct sockaddr *)&sock_in, sockin_size);
/*主动出击,连接对端*/
if (connect(tnode->fd, (struct sockaddr *)&sock_out, sockout_size) != 0 &&
errno != EINPROGRESS) {
/*如果对端压根就没准备好,比如CTDB进程不在,或者还没有完成listen,就无法建立连接
*此时合理的做法是,稍后再战,设置定时任务,1秒钟后重连*/
ctdb_tcp_stop_connection(node);
tnode->connect_te = event_add_timed(ctdb->ev, tnode,
timeval_current_ofs(1, 0),
ctdb_tcp_node_connect, node);
return;
}
/* non-blocking connect - wait for write event */
tnode->connect_fde = event_add_fd(node->ctdb->ev, tnode, tnode->fd,
EVENT_FD_WRITE|EVENT_FD_READ,
ctdb_node_connect_write, node);
/* don't give it long to connect - retry in one second. This ensures
that we find a node is up quickly (tcp normally backs off a syn reply
delay by quite a lot) */
tnode->connect_te = event_add_timed(ctdb->ev, tnode, timeval_current_ofs(1, 0), ctdb_tcp_node_connect, node);
}
注意,仅仅本函数就有多次设置定时任务,稍后再展的场景,如果连接顺利建立的话:
static void ctdb_node_connect_write(struct event_context *ev, struct fd_event *fde,uint16_t flags, void *private_data)
{
struct ctdb_node *node = talloc_get_type(private_data,
struct ctdb_node);
struct ctdb_tcp_node *tnode = talloc_get_type(node->private_data,
struct ctdb_tcp_node);
struct ctdb_context *ctdb = node->ctdb;
int error = 0;
socklen_t len = sizeof(error);
int one = 1;
talloc_free(tnode->connect_te);
tnode->connect_te = NULL;
if (getsockopt(tnode->fd, SOL_SOCKET, SO_ERROR, &error, &len) != 0 ||
error != 0) {
ctdb_tcp_stop_connection(node);
tnode->connect_te = event_add_timed(ctdb->ev, tnode,
timeval_current_ofs(1, 0),
ctdb_tcp_node_connect, node);
return;
}
talloc_free(tnode->connect_fde);
tnode->connect_fde = NULL;
setsockopt(tnode->fd,IPPROTO_TCP,TCP_NODELAY,(char *)&one,sizeof(one));
setsockopt(tnode->fd,SOL_SOCKET,SO_KEEPALIVE,(char *)&one,sizeof(one));
ctdb_queue_set_fd(tnode->out_queue, tnode->fd);
/* the queue subsystem now owns this fd */
tnode->fd = -1;
}
注意函数中的talloc_free,如果连接已经成功建立的话, 这些对应的定时任务就会砍掉,正常运行中,不会不断地建立连接,正相反,这些连接是稳定的。
当远端的CTDB服务停止
如果CTDB集群的另一个节点的CTDB 服务停掉了,那么本地CTDB要多久才能探测到远端节点已经死掉了。
答案是立刻马上。
2017/05/22 11:22:01.146844 [501881]: 10.11.12.2:4379: node 10.11.12.3:4379 is dead: 1 connected
2017/05/22 11:22:01.146894 [501881]: Tearing down connection to dead node :0
为什么立刻就可以?
在主动出击,连接其他节点的时候:
static int ctdb_tcp_add_node(struct ctdb_node *node)
{
struct ctdb_tcp_node *tnode;
tnode = talloc_zero(node, struct ctdb_tcp_node);
CTDB_NO_MEMORY(node->ctdb, tnode);
tnode->fd = -1;
node->private_data = tnode;
talloc_set_destructor(tnode, tnode_destructor);
tnode->out_queue = ctdb_queue_setup(node->ctdb, node, tnode->fd, CTDB_TCP_ALIGNMENT,
ctdb_tcp_tnode_cb, node, "to-node-%s", node->name);
return 0;
}
这里面有一个重要的回调函数:
/*
called when a complete packet has come in - should not happen on this socket
unless the other side closes the connection with RST or FIN
*/
void ctdb_tcp_tnode_cb(uint8_t *data, size_t cnt, void *private_data)
{
struct ctdb_node *node = talloc_get_type(private_data, struct ctdb_node);
struct ctdb_tcp_node *tnode = talloc_get_type(
node->private_data, struct ctdb_tcp_node);
if (data == NULL) {
node->ctdb->upcalls->node_dead(node);
}
ctdb_tcp_stop_connection(node);
tnode->connect_te = event_add_timed(node->ctdb->ev, tnode,
timeval_current_ofs(3, 0),
ctdb_tcp_node_connect, node);
}
void ctdb_node_dead(struct ctdb_node *node)
{
if (node->flags & NODE_FLAGS_DISCONNECTED) {
/*此处就是我们看到的DEBUG LOG*/
DEBUG(DEBUG_INFO,("%s: node %s is already marked disconnected: %u connected\n",
node->ctdb->name, node->name,
node->ctdb->num_connected));
return;
}
node->ctdb->num_connected--;
node->flags |= NODE_FLAGS_DISCONNECTED | NODE_FLAGS_UNHEALTHY;
node->rx_cnt = 0;
node->dead_count = 0;
DEBUG(DEBUG_NOTICE,("%s: node %s is dead: %u connected\n",
node->ctdb->name, node->name, node->ctdb->num_connected));
ctdb_daemon_cancel_controls(node->ctdb, node);
if (node->ctdb->methods == NULL) {
DEBUG(DEBUG_ERR,(__location__ " Can not restart transport while shutting down daemon.\n"));
return;
}
node->ctdb->methods->restart(node);
}
注释说的比较清除了,当RST或者FIN到来的时候,会调用ctdb_tcp_tnode_cb函数,这时候会执行ctdb_tcp_stop_connection和注册定时时间三秒后会尝试调用ctdb_tcp_node_connect重连。
当远端CTDB 异常崩溃
注意,上面的例子是CTDB正常退出,远端的CTDB来不及说goodbye,比如说该节点异常断电,或者操作系统crash,这种情况下,本地节点多久才能发现远端节点退出了,
取决于keepalive 如下两个参数:
root@BEAN-3:~# ctdb listvars |grep -i keepalive
KeepaliveInterval = 5
KeepaliveLimit = 5
注意,每5秒会向其他node发送依次心跳信息,或者叫做keepalive信息,如果过去5秒内没有收到node X任何消息,那么dead_count ++,如果连续dead_count == KeepaliveLimit,即5次,仍然没有收到任何消息,那么判定死亡。
注意5*5 = 25秒内收到任何一个消息,不一定心跳信息,也可能是普通消息,那么dead_count = 0 ,从头计数。
void ctdb_start_keepalive(struct ctdb_context *ctdb)
{
struct timed_event *te;
ctdb->keepalive_ctx = talloc_new(ctdb);
CTDB_NO_MEMORY_FATAL(ctdb, ctdb->keepalive_ctx);
te = event_add_timed(ctdb->ev, ctdb->keepalive_ctx,
timeval_current_ofs(ctdb->tunable.keepalive_interval, 0),
ctdb_check_for_dead_nodes, ctdb);
CTDB_NO_MEMORY_FATAL(ctdb, te);
DEBUG(DEBUG_NOTICE,("Keepalive monitoring has been started\n"));
}
下面看ctdb_check_for_dead_nodes函数:
static void ctdb_check_for_dead_nodes(struct event_context *ev, struct timed_event *te, struct timeval t, void *private_data)
{
struct ctdb_context *ctdb = talloc_get_type(private_data, struct ctdb_context);
int i;
/* send a keepalive to all other nodes, unless */
for (i=0;i<ctdb->num_nodes;i++) {
struct ctdb_node *node = ctdb->nodes[i];
if (node->flags & NODE_FLAGS_DELETED) {
continue;
}
if (node->pnn == ctdb->pnn) {
continue;
}
if (node->flags & NODE_FLAGS_DISCONNECTED) {
/* it might have come alive again */
if (node->rx_cnt != 0) {
ctdb_node_connected(node);
}
continue;
}
/*注意node->rx_cnt, 这个*/
if (node->rx_cnt == 0) {
node->dead_count++;
} else {
node->dead_count = 0;
}
node->rx_cnt = 0;
/*dead_count大于等于5,表示在5*5 25秒内没有收到任何消息
*这种情况下,判定该节点死亡*/
if (node->dead_count >= ctdb->tunable.keepalive_limit) {
DEBUG(DEBUG_NOTICE,("dead count reached for node %u\n", node->pnn));
/*注意调用了ctdb_node_dead,这个在上一小节已经介绍过了*/
ctdb_node_dead(node);
ctdb_send_keepalive(ctdb, node->pnn);
/* maybe tell the transport layer to kill the
sockets as well?
*/
continue;
}
DEBUG(DEBUG_DEBUG,("sending keepalive to %u\n", node->pnn));
ctdb_send_keepalive(ctdb, node->pnn);
node->tx_cnt = 0;
}
/*预约下一次发送心跳和检查对端存活*/
event_add_timed(ctdb->ev, ctdb->keepalive_ctx,
timeval_current_ofs(c
tdb->tunable.keepalive_interval, 0),
ctdb_check_for_dead_nodes, ctdb);
}
注意这个node->rx_cnt统计,收到任何消息都会++ :
static void ctdb_recv_pkt(struct ctdb_context *ctdb, uint8_t *data, uint32_t length)
{
struct ctdb_req_header *hdr = (struct ctdb_req_header *)data;
CTDB_INCREMENT_STAT(ctdb, node_packets_recv);
/* up the counter for this source node, so we know its alive */
if (ctdb_validate_pnn(ctdb, hdr->srcnode)) {
/* as a special case, redirected calls don't increment the rx_cnt */
if (hdr->operation != CTDB_REQ_CALL ||
((struct ctdb_req_call *)hdr)->hopcount == 0) {
ctdb->nodes[hdr->srcnode]->rx_cnt++;
}
}
ctdb_input_pkt(ctdb, hdr);
}
每一轮keepalive之后,这个值会清零。如果连续5轮次的检查,每一次rx_cnt都是0,这就表明,我们已经很久没有收到该对端节点发来的消息了,包括keepalive消息。
下面是模拟异常断电时候场景:
2017:05:15 16:37:38.367 FINISH ONE FRAME
2017:05:15 16:37:38.425 FINISH ONE FRAME
断电时间为16:37:38.367,我们看剩余两个节点检测到该节点死亡的时间:
node-1
---------------
2017/05/15 16:38:04.140307 [11898]: dead count reached for node 0
2017/05/15 16:38:04.140347 [11898]: 10.10.10.1:4379: node 10.10.10.3:4379 is dead: 1 connected
2017/05/15 16:38:04.140379 [11898]: Tearing down connection to dead node :0
node-2
------------
2017/05/15 16:38:05.180325 [ 9492]: dead count reached for node 0
2017/05/15 16:38:05.180364 [ 9492]: 10.10.10.2:4379: node 10.10.10.3:4379 is dead: 1 connected
2017/05/15 16:38:05.180397 [ 9492]: Tearing down connection to dead node :0
这种情况下,就会延时25后发现对端死掉,然后采取行动,所谓采取行动,就是不停地尝试重连。
如果检测到异常死亡,会调用ctdb_node_dead,这个函数中会调用tcp的restart方法,如下所示,就是注册定时器,反复尝试重连。
void ctdb_node_dead(struct ctdb_node *node)
{
if (node->flags & NODE_FLAGS_DISCONNECTED) {
DEBUG(DEBUG_INFO,("%s: node %s is already marked disconnected: %u connected\n",
node->ctdb->name, node->name,
node->ctdb->num_connected));
return;
}
node->ctdb->num_connected--;
node->flags |= NODE_FLAGS_DISCONNECTED | NODE_FLAGS_UNHEALTHY;
node->rx_cnt = 0;
node->dead_count = 0;
DEBUG(DEBUG_NOTICE,("%s: node %s is dead: %u connected\n",
node->ctdb->name, node->name, node->ctdb->num_connected));
ctdb_daemon_cancel_controls(node->ctdb, node);
if (node->ctdb->methods == NULL) {
DEBUG(DEBUG_ERR,(__location__ " Can not restart transport while shutting down daemon.\n"));
return;
}
node->ctdb->methods->restart(node);
}
static void ctdb_tcp_restart(struct ctdb_node *node)
{
struct ctdb_tcp_node *tnode = talloc_get_type(
node->private_data, struct ctdb_tcp_node);
DEBUG(DEBUG_NOTICE,("Tearing down connection to dead node :%d\n", node->pnn));
ctdb_tcp_stop_connection(node);
tnode->connect_te = event_add_timed(node->ctdb->ev, tnode, timeval_zero(),
ctdb_tcp_node_connect, node);
}
我们从如下log中也可以看到,如果对端死亡,本地端会不断地发起重连:
2017/05/22 11:53:53.477582 [995627]: Added timed event "ctdb_tcp_node_connect": 0x116db50
2017/05/22 11:53:53.477604 [995627]: Destroying timer event 0x116db50 "ctdb_tcp_node_connect"
2017/05/22 11:53:53.477624 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1161990
2017/05/22 11:53:56.478328 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1150ad0
2017/05/22 11:53:56.478353 [995627]: Ending timer event 0x1161990 "ctdb_tcp_node_connect"
2017/05/22 11:53:56.478490 [995627]: Destroying timer event 0x1150ad0 "ctdb_tcp_node_connect"
2017/05/22 11:53:56.478534 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1166a10
2017/05/22 11:53:57.479341 [995627]: Added timed event "ctdb_tcp_node_connect": 0x11567a0
2017/05/22 11:53:57.479365 [995627]: Ending timer event 0x1166a10 "ctdb_tcp_node_connect"
2017/05/22 11:53:57.480302 [995627]: Destroying timer event 0x11567a0 "ctdb_tcp_node_connect"
2017/05/22 11:53:57.480354 [995627]: Added timed event "ctdb_tcp_node_connect": 0x113eb70
2017/05/22 11:53:58.480948 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115e960
2017/05/22 11:53:58.480963 [995627]: Ending timer event 0x113eb70 "ctdb_tcp_node_connect"
2017/05/22 11:53:58.481123 [995627]: Destroying timer event 0x115e960 "ctdb_tcp_node_connect"
2017/05/22 11:53:58.481160 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115e960
2017/05/22 11:53:59.490461 [995627]: Added timed event "ctdb_tcp_node_connect": 0x113eda0
2017/05/22 11:53:59.490484 [995627]: Ending timer event 0x115e960 "ctdb_tcp_node_connect"
2017/05/22 11:53:59.498245 [995627]: Destroying timer event 0x113eda0 "ctdb_tcp_node_connect"
2017/05/22 11:53:59.527112 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1145430
2017/05/22 11:54:00.528222 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115ce40
2017/05/22 11:54:00.528236 [995627]: Ending timer event 0x1145430 "ctdb_tcp_node_connect"
2017/05/22 11:54:00.528404 [995627]: Destroying timer event 0x115ce40 "ctdb_tcp_node_connect"
2017/05/22 11:54:00.528436 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115cd90
2017/05/22 11:54:01.529274 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1156030
2017/05/22 11:54:01.529289 [995627]: Ending timer event 0x115cd90 "ctdb_tcp_node_connect"
2017/05/22 11:54:01.529484 [995627]: Destroying timer event 0x1156030 "ctdb_tcp_node_connect"
2017/05/22 11:54:01.529514 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1156030
2017/05/22 11:54:02.530539 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115aa70
2017/05/22 11:54:02.530554 [995627]: Ending timer event 0x1156030 "ctdb_tcp_node_connect"
2017/05/22 11:54:02.536729 [995627]: Destroying timer event 0x115aa70 "ctdb_tcp_node_connect"
2017/05/22 11:54:02.536784 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1151190
2017/05/22 11:54:03.537043 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1145430
2017/05/22 11:54:03.537058 [995627]: Ending timer event 0x1151190 "ctdb_tcp_node_connect"
2017/05/22 11:54:03.542502 [995627]: Destroying timer event 0x1145430 "ctdb_tcp_node_connect"
2017/05/22 11:54:03.542541 [995627]: Added timed event "ctdb_tcp_node_connect": 0x113eb70
2017/05/22 11:54:04.543121 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1162860
2017/05/22 11:54:04.543137 [995627]: Ending timer event 0x113eb70 "ctdb_tcp_node_connect"
2017/05/22 11:54:04.544105 [995627]: Destroying timer event 0x1162860 "ctdb_tcp_node_connect"
2017/05/22 11:54:04.544142 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115aa70
2017/05/22 11:54:05.544290 [995627]: Added timed event "ctdb_tcp_node_connect": 0x116dbb0
2017/05/22 11:54:05.544306 [995627]: Ending timer event 0x115aa70 "ctdb_tcp_node_connect"
2017/05/22 11:54:05.544581 [995627]: Destroying timer event 0x116dbb0 "ctdb_tcp_node_connect"
2017/05/22 11:54:05.544613 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1156730
2017/05/22 11:54:06.544825 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1145af0
2017/05/22 11:54:06.544840 [995627]: Ending timer event 0x1156730 "ctdb_tcp_node_connect"
2017/05/22 11:54:06.545130 [995627]: Destroying timer event 0x1145af0 "ctdb_tcp_node_connect"
2017/05/22 11:54:06.545163 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1144cf0
2017/05/22 11:54:07.546060 [995627]: Added timed event "ctdb_tcp_node_connect": 0x114f070
2017/05/22 11:54:07.546086 [995627]: Ending timer event 0x1144cf0 "ctdb_tcp_node_connect"
2017/05/22 11:54:07.562138 [995627]: Destroying timer event 0x114f070 "ctdb_tcp_node_connect"
2017/05/22 11:54:07.562233 [995627]: Added timed event "ctdb_tcp_node_connect": 0x115b2d0
2017/05/22 11:54:08.562968 [995627]: Added timed event "ctdb_tcp_node_connect": 0x1156030
2017/05/22 11:54:08.562990 [995627]: Ending timer event 0x115b2d0 "ctdb_tcp_node_connect"