前言
最近一直在看ceph filestore中底层对象相关的部分,即ceph 对象最终如何存储在本地文件系统里。牵扯的东西有点多,同时工作太忙,所以进度不尽人意。
数据结构
我们用递进的方式描述底层对象的数据结构。
object_t
首先是object_t 结构体:
struct object_t {
string name;
...
}
该结构体和后面的sobject_t结构体定义在src/include/object.h中。object_t对应的就是底层文件系统中的一个文件的名字。这个非常容易理解,就不赘述。
sobject_t
接下来一个数据结构是sobject_t,s是snap的含义,就是添加了snapshot相关信息的object_t,其定义如下:
struct sobject_t {
object_t oid;
snapid_t snap;
sobject_t() : snap(0) {}
sobject_t(object_t o, snapid_t s) : oid(o), snap(s) {}
void swap(sobject_t& o) {
oid.swap(o.oid);
snapid_t t = snap;
snap = o.snap;
o.snap = t;
}
void encode(bufferlist& bl) const {
::encode(oid, bl);
::encode(snap, bl);
}
void decode(bufferlist::iterator& bl) {
::decode(oid, bl);
::decode(snap, bl);
}
};
snapid_t到底是个什么类型呢,其实就是个uinit_64_t类型。
struct snapid_t {
uint64_t val;
// cppcheck-suppress noExplicitConstructor
snapid_t(uint64_t v=0) : val(v) {}
snapid_t operator+=(snapid_t o) { val += o.val; return *this; }
snapid_t operator++() { ++val; return *this; }
operator uint64_t() const { return val; }
};
我们可以给rbd image创建snapshot,这时候,底层对象就有snapshot相关的信息。
hobject_t
h应该是hash的意思,该结构体定义如下:
struct hobject_t {
object_t oid;
snapid_t snap;
private:
uint32_t hash;
bool max;
uint32_t nibblewise_key_cache;
uint32_t hash_reverse_bits;
static const int64_t POOL_META = -1;
static const int64_t POOL_TEMP_START = -2; // and then negative
friend class spg_t; // for POOL_TEMP_START
public:
int64_t pool;
string nspace;
private:
string key;
oid 和snap 就不赘述了,这个结构体新增了 hash 和key 以及pool的字段。
- int64_t pool: 对象所属的pool
- string key :
- uint32_t hash:
key 和 hash不能同时指定,而更常见的是hash。
对于底层文件而言,它在本地文件系统存放的位置,是根据其hash值决定的。
/data/osd.7/current/2.1a4_head/DIR_4/DIR_A/DIR_D/100000052f4.00000023__head_38D9DDA4__2
如下图所示 :
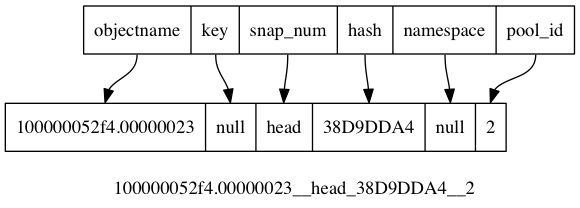
这里面38D9DDA4即是 对象的hash值,该值是一个uint32_t类型的值,该值是通过objectname 计算hash获得的。
unsigned ceph_str_hash_rjenkins(const char *str, unsigned length)
{
const unsigned char *k = (const unsigned char *)str;
__u32 a, b, c; /* the internal state */
__u32 len; /* how many key bytes still need mixing */
/* Set up the internal state */
len = length;
a = 0x9e3779b9; /* the golden ratio; an arbitrary value */
b = a;
c = 0; /* variable initialization of internal state */
/* handle most of the key */
while (len >= 12) {
a = a + (k[0] + ((__u32)k[1] << 8) + ((__u32)k[2] << 16) +
((__u32)k[3] << 24));
b = b + (k[4] + ((__u32)k[5] << 8) + ((__u32)k[6] << 16) +
((__u32)k[7] << 24));
c = c + (k[8] + ((__u32)k[9] << 8) + ((__u32)k[10] << 16) +
((__u32)k[11] << 24));
mix(a, b, c);
k = k + 12;
len = len - 12;
}
/* handle the last 11 bytes */
c = c + length;
switch (len) { /* all the case statements fall through */
case 11:
c = c + ((__u32)k[10] << 24);
case 10:
c = c + ((__u32)k[9] << 16);
case 9:
c = c + ((__u32)k[8] << 8);
/* the first byte of c is reserved for the length */
case 8:
b = b + ((__u32)k[7] << 24);
case 7:
b = b + ((__u32)k[6] << 16);
case 6:
b = b + ((__u32)k[5] << 8);
case 5:
b = b + k[4];
case 4:
a = a + ((__u32)k[3] << 24);
case 3:
a = a + ((__u32)k[2] << 16);
case 2:
a = a + ((__u32)k[1] << 8);
case 1:
a = a + k[0];
/* case 0: nothing left to add */
}
mix(a, b, c);
return c;
}
/*
* linux dcache hash
*/
unsigned ceph_str_hash_linux(const char *str, unsigned length)
{
unsigned long hash = 0;
while (length--) {
unsigned char c = *str++;
hash = (hash + (c << 4) + (c >> 4)) * 11;
}
return hash;
}
unsigned ceph_str_hash(int type, const char *s, unsigned len)
{
switch (type) {
case CEPH_STR_HASH_LINUX:
return ceph_str_hash_linux(s, len);
case CEPH_STR_HASH_RJENKINS:
return ceph_str_hash_rjenkins(s, len);
default:
return -1;
}
}
ceph实现了两种了字符串hash,一种是Linux dcache采用的hash算法,比较简洁,另一种是RJenkins hash 算法。根据object name计算hash 采用的Rjenkins hash 算法。
OPTION(mds_default_dir_hash, OPT_INT, CEPH_STR_HASH_RJENKINS)
#define CEPH_STR_HASH_LINUX 0x1 /* linux dcache hash */
#define CEPH_STR_HASH_RJENKINS 0x2 /* robert jenkins' */
root@host186:~# ceph daemon mds.waotp config show |grep dir_hash
"mds_default_dir_hash": "2",
对于一个对象而言,pool是不能选择的,因为,无论是NAS还是rbd,首先都要指定建立在which pool上,因为pool的副本个数和下辖的OSD是确定的,因此,一旦指定NAS文件夹建立在which pool上,那么,写入该文件夹的数据,副本的个数和可能落在which OSDs上就确定了。
但是对象位于pool的which PG上呢? 这就完全取决对象的hash值。 还是考虑如下的对象:
/data/osd.7/current/2.1a4_head/DIR_4/DIR_A/DIR_D/100000052f4.00000023__head_38D9DDA4__2
我们以拥有1024个PG的pool为例,上述对象的hash是 38D9DDA4,我们可以很轻易的将该值map到对应的pg上
pg_index = hash % pg_num
上述计算可以得到,1A4,因此,该对象属于 pool 2下属的 1A4 这个PG,因此,我们看对象所在的路径,它的确落在2.1a4_head这个路径。
/data/osd.7/current/2.1a4_head
问题是为什么2.1a4这个PG落在 OSD.7上呢? 这是 CRUSH算法决定,在此不赘述。
上图中还有一个很有意思的问题,即,明明有个字段是 snap_num,为什么该字段是head这个字符串呢。我们不妨看看从底层文件系统上对象的名字到gobject_t 数据结构映射的这个过程,在src/os/filestore/LFNIndex.cc中的
int LFNIndex::lfn_parse_object_name(const string &long_name, ghobject_t *out)
{
string name;
string key;
string ns;
uint32_t hash;
snapid_t snap;
uint64_t pool;
gen_t generation = ghobject_t::NO_GEN;
shard_id_t shard_id = shard_id_t::NO_SHARD;
if (index_version == HASH_INDEX_TAG)
return lfn_parse_object_name_keyless(long_name, out);
if (index_version == HASH_INDEX_TAG_2)
return lfn_parse_object_name_poolless(long_name, out);
string::const_iterator current = long_name.begin();
if (*current == '\\') {
++current;
if (current == long_name.end()) {
return -EINVAL;
} else if (*current == 'd') {
name.append("DIR_");
++current;
} else if (*current == '.') {
name.append(".");
++current;
} else {
--current;
}
}
string::const_iterator end = current;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end == long_name.end())
return -EINVAL;
if (!append_unescaped(current, end, &name))
return -EINVAL;
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end == long_name.end())
return -EINVAL;
if (!append_unescaped(current, end, &key))
return -EINVAL;
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end == long_name.end())
return -EINVAL;
string snap_str(current, end);
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end == long_name.end())
return -EINVAL;
string hash_str(current, end);
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end == long_name.end())
return -EINVAL;
if (!append_unescaped(current, end, &ns))
return -EINVAL;
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
string pstring(current, end);
// Optional generation/shard_id
string genstring, shardstring;
if (end != long_name.end()) {
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end == long_name.end())
return -EINVAL;
genstring = string(current, end);
generation = (gen_t)strtoull(genstring.c_str(), NULL, 16);
current = ++end;
for ( ; end != long_name.end() && *end != '_'; ++end) ;
if (end != long_name.end())
return -EINVAL;
shardstring = string(current, end);
shard_id = (shard_id_t)strtoul(shardstring.c_str(), NULL, 16);
}
if (snap_str == "head")
snap = CEPH_NOSNAP;
else if (snap_str == "snapdir")
snap = CEPH_SNAPDIR;
else
snap = strtoull(snap_str.c_str(), NULL, 16);
sscanf(hash_str.c_str(), "%X", &hash);
if (pstring == "none")
pool = (uint64_t)-1;
else
pool = strtoull(pstring.c_str(), NULL, 16);
(*out) = ghobject_t(hobject_t(name, key, snap, hash, (int64_t)pool, ns), generation, shard_id);
return 0;
}
注意,我很无耻地整个函数拷贝于此,并不是为了骗稿费,呵呵事实上也没人给我稿费。我只是想说该函数大部分的内容,都是通过上面图片所示的对应关系解析出gobject_t对象的各个字段的值。关于snap这个字段,有如下内容:
if (snap_str == "head")
snap = CEPH_NOSNAP;
else if (snap_str == "snapdir")
snap = CEPH_SNAPDIR;
else
snap = strtoull(snap_str.c_str(), NULL, 16);
如果底层对象对应的文件名中,对应snap的字段是head,那么snap赋值为CEPH_NOSNAP ,如果该字段的值为snapdir,那么snap字段赋值为 CEPH_SNAPDIR,否则,该值就是snap的值。
在hash的后面一个字段是namespace,大部分情况下,key和namespace并不会出现,因此,对象对应的文件名字中,__会出现两次,一次是因为key不存在,第二次是因为namespace 不存在。
有了 name key snap hash pool ns 这些信息,gobject 需要的信息就齐备了。因此,我们总是可以从对象在底层文件系统对应的文件的文件名中解析出上述字段的值。
我们也看到了这行代码:
(*out) = ghobject_t(hobject_t(name, key, snap, hash, (int64_t)pool, ns), generation, shard_id);
这行代码完美地提示了hobjcet_t和ghobject_t的区别。
ghobject_t
ghobject_t比hobject_t多了一些字段,主要是 generate 和shard_id字段
struct ghobject_t {
hobject_t hobj;
gen_t generation;
shard_id_t shard_id;
bool max;
...
这两个字段是用于纠删码 rollback用的,如果采用的是副本方式,那么 shard_id = NO_SHARD。 当PG为纠删码迟的PG时,写操作需要区分前后两个版本的object,写操作保存对象的上一个版本(generation)的对象,当EC写失败时,可以恢复到上一个版本。
在上一小节的 lfn_parse_object_name 函数,可以从文件名推导出 ghobject_t的相关信息,同样从ghobject_t也能反向推导出对象对应的文件名。这个工作是 lfn_generate_object_name 完成的。
/// Generate object name
string lfn_generate_object_name(
const ghobject_t &oid ///< [in] Object for which to generate.
) {
if (index_version == HASH_INDEX_TAG)
return lfn_generate_object_name_keyless(oid);
if (index_version == HASH_INDEX_TAG_2)
return lfn_generate_object_name_poolless(oid);
else
return lfn_generate_object_name_current(oid);
} ///< @return Generated object name.
string LFNIndex::lfn_generate_object_name_current(const ghobject_t &oid)
{
string full_name;
string::const_iterator i = oid.hobj.oid.name.begin();
if (oid.hobj.oid.name.substr(0, 4) == "DIR_") {
full_name.append("\\d");
i += 4;
} else if (oid.hobj.oid.name[0] == '.') {
full_name.append("\\.");
++i;
}
append_escaped(i, oid.hobj.oid.name.end(), &full_name);
full_name.append("_");
append_escaped(oid.hobj.get_key().begin(), oid.hobj.get_key().end(), &full_name);
full_name.append("_");
char buf[PATH_MAX];
char *t = buf;
char *end = t + sizeof(buf);
if (oid.hobj.snap == CEPH_NOSNAP)
t += snprintf(t, end - t, "head");
else if (oid.hobj.snap == CEPH_SNAPDIR)
t += snprintf(t, end - t, "snapdir");
else
t += snprintf(t, end - t, "%llx", (long long unsigned)oid.hobj.snap);
snprintf(t, end - t, "_%.*X", (int)(sizeof(oid.hobj.get_hash())*2), oid.hobj.get_hash());
full_name += string(buf);
full_name.append("_");
append_escaped(oid.hobj.nspace.begin(), oid.hobj.nspace.end(), &full_name);
full_name.append("_");
t = buf;
end = t + sizeof(buf);
if (oid.hobj.pool == -1)
t += snprintf(t, end - t, "none");
else
t += snprintf(t, end - t, "%llx", (long long unsigned)oid.hobj.pool);
full_name += string(buf);
if (oid.generation != ghobject_t::NO_GEN ||
oid.shard_id != shard_id_t::NO_SHARD) {
full_name.append("_");
t = buf;
end = t + sizeof(buf);
t += snprintf(t, end - t, "%llx", (long long unsigned)oid.generation);
full_name += string(buf);
full_name.append("_");
t = buf;
end = t + sizeof(buf);
t += snprintf(t, end - t, "%x", (int)oid.shard_id);
full_name += string(buf);
}
return full_name;
}
根据上面的图片,不难看出该函数的意思,在此就不赘述了,
结束语
对象是如何在底层文件系统分布的。同一个PG下的对象可能千千万万,Ceph如何将这些对象高效地组织起来? 这是后面的内容。 而且还有一点,本文并没有解释long file name 时候的处理方式。这也留待后面解说。