前言
前面花了两篇博客的篇幅介绍了读流程。写流程和读流程相比,有大量的流程走向是公用的,我将这些公共的流程总结如下:
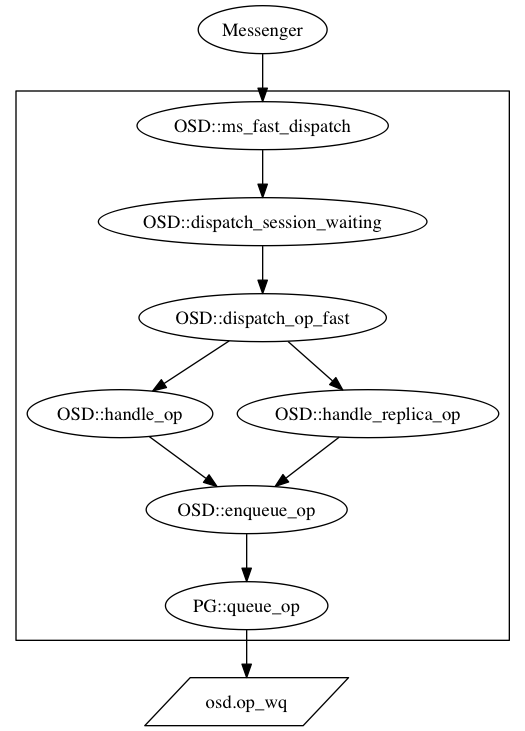
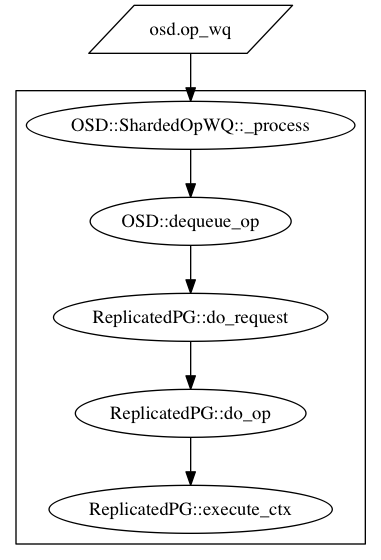
对于读流程而言,相对比较简单,这也是我们先介绍读流程的原因。先设置一个小目标,达成之后,对总体的大目标也有好处,相当于将大任务分解成了几个小任务。
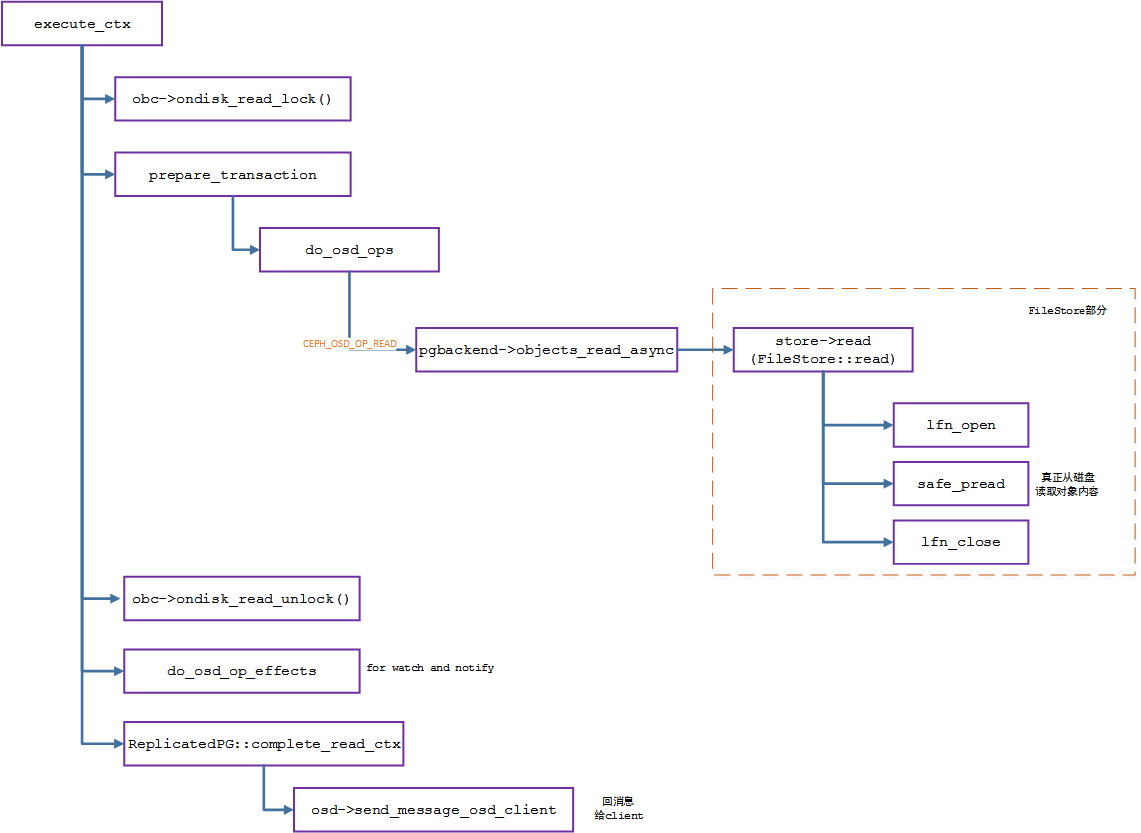
从 execute_ctx 开始,读写流程开始严重的分叉,下图是读流程的流程图
写流程的三个侧面
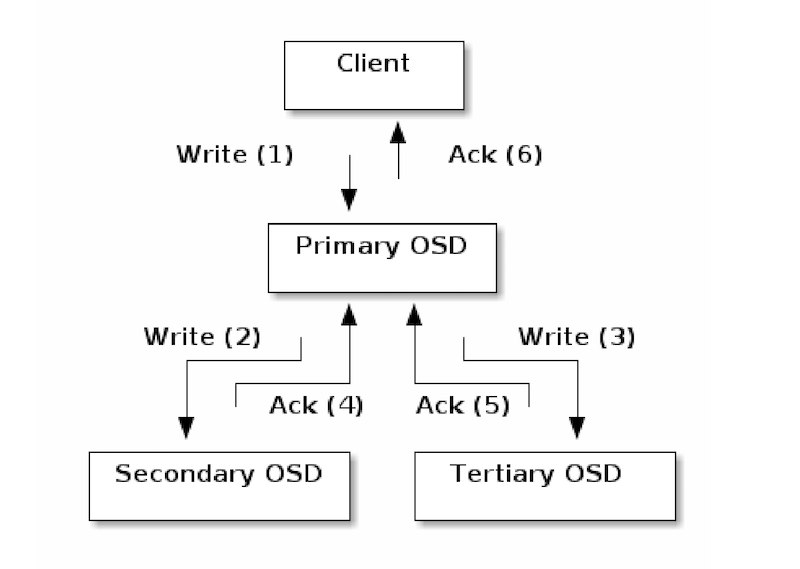
写流程之所以比读流程复杂,原因在于读流程只需要去Primary OSD读取响应的Object即可,而写流程牵扯到多个OSD。下图来自Ceph的官方文档:
写流程之所以比读流程复杂源于多个方面,
- 牵扯多个OSD的写入,如何确保多副本之间一致性 (PGLog)
- 对于单个OSD的写入,如何确保最终的一致性 (Journal and FileStore)
- 多个副本所在的OSD,如果状态不是active + clean
多种因素造成了写流程的异常复杂。本人功力有限,所以先从主干流程介绍起。这个写流程,打算至少从三个侧重点分别介绍:
-
第一个篇侧重在Primary OSD和Secondary OSD的交互流程,即Primary 如何将写相关的任务发送给Secondary OSD,Secondary OSD又如何发送自己的完成进度给Primary OSD, Primary OSD收到相关的进度,又采取了什么样的行动,以及Primary如何给Client发送响应
-
第二篇文章侧重于数据部分,即各个OSD 收到写入的请求之后,从filestore层面做了哪些的事情,在不同的完成阶段,会做哪些事情
-
第三篇文章会侧重于PGLog,为了确保各个副本的一致性,出了写入数据,事务操作也会纪录PGLog,一旦某个出现异常,可以根据PGLog的信息,确定哪个OSD的数据是最可靠的,从发起数据的同步。
因为写入的流程异常的复杂,因此,介绍A侧面的时候,尽量不涉及B和C侧面,否则所有细节纠缠在一起,就会将设计思想淹没在无数的细节之中,这并不利于我们理解写入流程。
准备事务(prepare_transaction)
ceph的读和写显著的不同在于读基本上只需要从Primary OSD中读取(offset,length)指定部分的内容即可,不牵扯到多个OSD之间的交互,而且读并没有对存储作出改变。 而写则不然,首先,ceph支持多副本,也支持纠删码(本系列暂不考虑纠删码),写入本身就牵扯到多个OSD之间的互动。其次,正常情况自不必说,但是多个副本之间的写入可能会在某个副本出现问题,副本之间需要能够确定哪个副本的数据已经正确写入,哪个副本的数据还未写入完毕,这就加剧了ceph写入的复杂程度。
本文只介绍Primary 和Secondary之间的消息交互,作为整个写入过程的整体框架。
对于写入而言,execute_ctx函数中第一个比较重要的函数是 prepare_transaction。这个函数顾名思义,就是用来准备transaction事务的。但是我们前面一起研读过read 的代码,prepare_transaction有点言不由衷,事实上,prepare_transaction有点挂羊头卖狗肉,该函数中的do_osd_ops函数直接将完成了读操作的核心步骤,并非做什么准备工作。
但是对于写入而言,该函数不再挂羊头卖狗肉,正而八经地做准备工作。我们开始学习该函数了哪些事情.
和之前一样,execute_ctx调用了prepare_tranasction,而prepare_transaction调用了do_osd_ops。我们来看do_osd_ops做了哪些事情:
瞿天善绘制了一张图,详细介绍了对于write流程,do_osd_ops做的事情:
{kind=link}
其核心代码在此:
case CEPH_OSD_OP_WRITE:
++ctx->num_write;
{
....
if (seq && (seq > op.extent.truncate_seq) &&
(op.extent.offset + op.extent.length > oi.size)) {
// old write, arrived after trimtrunc
op.extent.length = (op.extent.offset > oi.size ? 0 : oi.size - op.extent.offset);
dout(10) << " old truncate_seq " << op.extent.truncate_seq << " < current " << seq
<< ", adjusting write length to " << op.extent.length << dendl;
bufferlist t;
t.substr_of(osd_op.indata, 0, op.extent.length);
osd_op.indata.swap(t);
}
if (op.extent.truncate_seq > seq) {
// write arrives before trimtrunc
if (obs.exists && !oi.is_whiteout()) {
dout(10) << " truncate_seq " << op.extent.truncate_seq << " > current " << seq
<< ", truncating to " << op.extent.truncate_size << dendl;
t->truncate(soid, op.extent.truncate_size);
oi.truncate_seq = op.extent.truncate_seq;
oi.truncate_size = op.extent.truncate_size;
if (op.extent.truncate_size != oi.size) {
ctx->delta_stats.num_bytes -= oi.size;
ctx->delta_stats.num_bytes += op.extent.truncate_size;
oi.size = op.extent.truncate_size;
}
} else {
dout(10) << " truncate_seq " << op.extent.truncate_seq << " > current " << seq
<< ", but object is new" << dendl;
oi.truncate_seq = op.extent.truncate_seq;
oi.truncate_size = op.extent.truncate_size;
}
}
result = check_offset_and_length(op.extent.offset, op.extent.length, cct->_conf->osd_max_object_size);
if (result < 0)
break;
if (pool.info.require_rollback()) {
t->append(soid, op.extent.offset, op.extent.length, osd_op.indata, op.flags);
} else {
t->write(soid, op.extent.offset, op.extent.length, osd_op.indata, op.flags);
}
maybe_create_new_object(ctx);
if (op.extent.offset == 0 && op.extent.length >= oi.size)
obs.oi.set_data_digest(osd_op.indata.crc32c(-1));
else if (op.extent.offset == oi.size && obs.oi.is_data_digest())
obs.oi.set_data_digest(osd_op.indata.crc32c(obs.oi.data_digest));
else
obs.oi.clear_data_digest();
write_update_size_and_usage(ctx->delta_stats, oi, ctx->modified_ranges,
op.extent.offset, op.extent.length, true);
}
break;
对于多副本的写入,该函数的眼在:
t->write(soid, op.extent.offset, op.extent.length, osd_op.indata, op.flags);
是的,do_osd_ops的核心功能就是瞿天善那张非常详细图的中心位置的子图,产生出ObjectStore::Transaction
![]()
我们一起阅读os/ObjectStore.h中的写操作:
/**
* Write data to an offset within an object. If the object is too
* small, it is expanded as needed. It is possible to specify an
* offset beyond the current end of an object and it will be
* expanded as needed. Simple implementations of ObjectStore will
* just zero the data between the old end of the object and the
* newly provided data. More sophisticated implementations of
* ObjectStore will omit the untouched data and store it as a
* "hole" in the file.
*/
void write(const coll_t& cid, const ghobject_t& oid, uint64_t off, uint64_t len,
const bufferlist& write_data, uint32_t flags = 0) {
uint32_t orig_len = data_bl.length();
Op* _op = _get_next_op();
_op->op = OP_WRITE;
_op->cid = _get_coll_id(cid);
_op->oid = _get_object_id(oid);
_op->off = off;
_op->len = len;
::encode(write_data, data_bl);
assert(len == write_data.length());
data.fadvise_flags = data.fadvise_flags | flags;
if (write_data.length() > data.largest_data_len) {
data.largest_data_len = write_data.length();
data.largest_data_off = off;
data.largest_data_off_in_data_bl = orig_len + sizeof(__u32); // we are about to
}
data.ops++;
}
这一部分是很容易理解的,就是说把操作码设置为OP_WRITE,记录好要写入的object和coll,将offset 和length设置正确,同时将要写入的data纪录下来,后续ObjectStore部分(更具体地说是filestore),就可以根据上述信息,完成写入底层对象存储的动作。
上述内容仅仅是一个部分,之前也提过,除了data,还有PGLog,这部分内容是为了纪录各个副本之间的写入情况,预防异常发生。prepare_transaction函数的最后,会调用finish_ctx函数,finish_ctx函数里就会调用ctx->log.push_back就会构造pg_log_entry_t插入到vector log里。
PGLog后续会有专门文章介绍,我们按下不表,包括ReplicatedBackend::submit_transaction里调用parent->log_operation将PGLog序列化到transaction里,这些内容我们都不会在本文介绍。
消息流动
有这么一张图,可以粗略地介绍Primary OSD和Replica OSD之间的消息流动,本文的重点也是介绍这个:
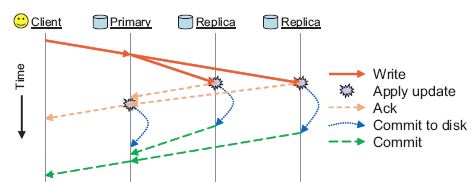
从上图可以看出,client只会和Primary OSD之间有消息交互,至于其它副本的数据写入,要靠Primary OSD发送请求通知它们,当然当Replica OSD写完之后,需要发送消息告知Primary OSD, Primary OSD汇总各个OSD的写入情况,在合适的时机给Client发送响应信息。
注意,无论是Primary OSD还是 Replica OSD,写入都分成2个阶段,第一阶段是写入Journal,写入Journal成功,第一阶段的任务就算完成了,当Replica OSD如果完成了第一阶段的任务,写入了Journal,就会给Primary OSD发送第一个消息,表示第一阶段的任务完成了。如果Primary同时收到了所有的OSD的消息,确认所有OSD上的第一阶段任务完成,就会给Client回复第一个消息,表示写入已经完成。
注意,第一阶段是写入Journal,因此,Journal如果是SSD这种比较快速的设备,会极大地改善写入请求的处理速度。
我们从上图中也可以看出每一个Replica OSD给Primary OSD发送了2个消息,其中第二个消息,对应的是第二阶段任务的完成。当Journal中的数据向OSD的data partition写入成功后,第二阶段任务就算完成了,Replica OSD就会给Primary OSD发送第二个消息。当Primary OSD搜集齐了所有OSD都完成了的消息之后,就会确认整体第二阶段的任务完成,就会给Client消息,通知数据可读。
很粗略,基本是简单地介绍了消息流动图,但是,我们是研究ceph internal的,这么粗略是不能原谅的。很多细节都隐藏在这些笼统的描述中。比如,Primary在什么时机将写入的消息发送给Replica OSD,消息类型是什么;又比如,完成第一阶段和第二阶段过程之后,Replica OSD分别给Primary OSD发送了什么消息,而Primary OSD又是如何处理这些消息的;再比如Primary OSD 如何判断 所有的OSD是否都完成了第一阶段的任务?
注意,上面笼统的描述中,介绍了当Primary OSD发现所有的OSD都完成了第一阶段任务,则发送消息给client,告知client写入完成,第二阶段的任务亦然,这表明,Primary OSD必须有数据结构能够纪录下各个OSD的完成情况,这个数据结构是什么呢?
这个数据结构就是in_progress_ops !
在issue_repop函数中,会调用
Context *on_all_commit = new C_OSD_RepopCommit(this, repop);
Context *on_all_applied = new C_OSD_RepopApplied(this, repop);
Context *onapplied_sync = new C_OSD_OndiskWriteUnlock(
ctx->obc,
ctx->clone_obc,
unlock_snapset_obc ? ctx->snapset_obc : ObjectContextRef());
pgbackend->submit_transaction(
soid,
ctx->at_version,
std::move(ctx->op_t),
pg_trim_to,
min_last_complete_ondisk,
ctx->log,
ctx->updated_hset_history,
onapplied_sync,
on_all_applied,
on_all_commit,
repop->rep_tid,
ctx->reqid,
ctx->op);
其中submit_transaction函数中,会将与该PG操作对应的OSD都纪录在册:
void ReplicatedBackend::submit_transaction(
const hobject_t &soid,
const eversion_t &at_version,
PGTransactionUPtr &&_t,
const eversion_t &trim_to,
const eversion_t &trim_rollback_to,
const vector<pg_log_entry_t> &log_entries,
boost::optional<pg_hit_set_history_t> &hset_history,
Context *on_local_applied_sync,
Context *on_all_acked,
Context *on_all_commit,
ceph_tid_t tid,
osd_reqid_t reqid,
OpRequestRef orig_op)
{
...
InProgressOp &op = in_progress_ops.insert(
make_pair(
tid,
InProgressOp(
tid, on_all_commit, on_all_acked,
orig_op, at_version)
)
).first->second;
op.waiting_for_applied.insert(
parent->get_actingbackfill_shards().begin(),
parent->get_actingbackfill_shards().end());
op.waiting_for_commit.insert(
parent->get_actingbackfill_shards().begin(),
parent->get_actingbackfill_shards().end());
...
}
注意,InProgressOP维护有两个集合,waiting_for_commit这个集合存放的是尚未完成第一阶段任务(即写入Journal)的所有OSD,waiting_for_applied这个集合存放的是尚未完成第二阶段任务(即从Journal写入OSD的data partition或Disk)的所有OSD。
struct InProgressOp {
ceph_tid_t tid;
set<pg_shard_t> waiting_for_commit; /*尚未完成第一阶段任务的OSD的集合*/
set<pg_shard_t> waiting_for_applied; /*尚未完成第二阶段任务的OSD的集合*/
Context *on_commit;
Context *on_applied;
OpRequestRef op;
eversion_t v;
InProgressOp(
ceph_tid_t tid, Context *on_commit, Context *on_applied,
OpRequestRef op, eversion_t v)
: tid(tid), on_commit(on_commit), on_applied(on_applied),
op(op), v(v) {}
bool done() const {
return waiting_for_commit.empty() &&
waiting_for_applied.empty();
}
};
很明显,当Replica OSD或者Primary OSD完成第一阶段或者第二阶段任务的时候,都必然会通知到Primary OSD,更新这两个集合中的元素: 如何更新? 这就牵扯到了很重要的回调机制。
写操作有三个贯穿始终的回调,这个回调函数会层层传递,当何时的时机到达的时候,就会执行相关的回调函数。回调在ceph中非常普遍,这个东西就有点像诸葛亮给赵云的三个锦囊,到了合适的时间点,就立刻启动回调函数。
我们介绍回调函数之前,我们先把Primary OSD 和Replica OSD之间的消息交互捋顺。
在ReplicatedBackend::submit_transaction中,准备好了InProgressOP之后,紧接着就会通过调用issue_op函数,在该函数里,会向Replica OSD发送消息:
issue_op(
soid,
at_version,
tid,
reqid,
trim_to,
trim_rollback_to,
t->get_temp_added().empty() ? hobject_t() : *(t->get_temp_added().begin()),
t->get_temp_cleared().empty() ?
hobject_t() : *(t->get_temp_cleared().begin()),
log_entries,
hset_history,
&op,
op_t);
void ReplicatedBackend::issue_op(
const hobject_t &soid,
const eversion_t &at_version,
ceph_tid_t tid,
osd_reqid_t reqid,
eversion_t pg_trim_to,
eversion_t pg_trim_rollback_to,
hobject_t new_temp_oid,
hobject_t discard_temp_oid,
const vector<pg_log_entry_t> &log_entries,
boost::optional<pg_hit_set_history_t> &hset_hist,
InProgressOp *op,
ObjectStore::Transaction &op_t)
{
if (parent->get_actingbackfill_shards().size() > 1) {
ostringstream ss;
set<pg_shard_t> replicas = parent->get_actingbackfill_shards();
replicas.erase(parent->whoami_shard());
ss << "waiting for subops from " << replicas;
if (op->op)
op->op->mark_sub_op_sent(ss.str());
}
for (set<pg_shard_t>::const_iterator i =
parent->get_actingbackfill_shards().begin();
i != parent->get_actingbackfill_shards().end();
++i) {
if (*i == parent->whoami_shard()) continue;
pg_shard_t peer = *i;
const pg_info_t &pinfo = parent->get_shard_info().find(peer)->second;
Message *wr;
wr = generate_subop(
soid,
at_version,
tid,
reqid,
pg_trim_to,
pg_trim_rollback_to,
new_temp_oid,
discard_temp_oid,
log_entries,
hset_hist,
op_t,
peer,
pinfo);
get_parent()->send_message_osd_cluster(
peer.osd, wr, get_osdmap()->get_epoch());
}
}
我们看到了,在循环体中,会遍历所有的Replica OSD,向对应的OSD发送消息,而消息体的组装,是在generate_subop函数中,我们进入该函数,看下发送的到底是哪种类型的消息:
Message * ReplicatedBackend::generate_subop(
const hobject_t &soid,
const eversion_t &at_version,
ceph_tid_t tid,
osd_reqid_t reqid,
eversion_t pg_trim_to,
eversion_t pg_trim_rollback_to,
hobject_t new_temp_oid,
hobject_t discard_temp_oid,
const vector<pg_log_entry_t> &log_entries,
boost::optional<pg_hit_set_history_t> &hset_hist,
ObjectStore::Transaction &op_t,
pg_shard_t peer,
const pg_info_t &pinfo)
{
int acks_wanted = CEPH_OSD_FLAG_ACK | CEPH_OSD_FLAG_ONDISK;
// forward the write/update/whatever
MOSDRepOp *wr = new MOSDRepOp(
reqid, parent->whoami_shard(),
spg_t(get_info().pgid.pgid, peer.shard),
soid, acks_wanted,
get_osdmap()->get_epoch(),
tid, at_version);
// ship resulting transaction, log entries, and pg_stats
if (!parent->should_send_op(peer, soid)) {
dout(10) << "issue_repop shipping empty opt to osd." << peer
<<", object " << soid
<< " beyond MAX(last_backfill_started "
<< ", pinfo.last_backfill "
<< pinfo.last_backfill << ")" << dendl;
ObjectStore::Transaction t;
::encode(t, wr->get_data());
} else {
::encode(op_t, wr->get_data());
wr->get_header().data_off = op_t.get_data_alignment();
}
::encode(log_entries, wr->logbl);
if (pinfo.is_incomplete())
wr->pg_stats = pinfo.stats; // reflects backfill progress
else
wr->pg_stats = get_info().stats;
wr->pg_trim_to = pg_trim_to;
wr->pg_trim_rollback_to = pg_trim_rollback_to;
wr->new_temp_oid = new_temp_oid;
wr->discard_temp_oid = discard_temp_oid;
wr->updated_hit_set_history = hset_hist;
return wr;
}
注意发送的消息MOSDRepOp,其中Message的type字段为 MSG_OSD_REPOP。
MOSDRepOp(osd_reqid_t r, pg_shard_t from,
spg_t p, const hobject_t& po, int aw,
epoch_t mape, ceph_tid_t rtid, eversion_t v)
: Message(MSG_OSD_REPOP, HEAD_VERSION, COMPAT_VERSION),
map_epoch(mape),
reqid(r),
pgid(p),
final_decode_needed(false),
from(from),
poid(po),
acks_wanted(aw),
version(v) {
set_tid(rtid);
}
| 值得注意的是acks_wanted字段为CEPH_OSD_FLAG_ACK | CEPH_OSD_FLAG_ONDISK,这就意味着消息接收方的Replica OSD需要给发送方的Primary OSD回复2个消息。先不扯这么远,先看Replica OSD 收到消息之后,如何处理。 |
Primary发送了这种消息之后,Replica OSD会和本文的前两张图一样,进入到队列,然后从osd.op_wq中取出消息进行处理。当走到do_request函数之后,并没有机会执行do_op,或者do_sub_op之类的函数,而是被handle_message函数拦截了:
if (pgbackend->handle_message(op))
return;
bool ReplicatedBackend::handle_message(
OpRequestRef op
)
{
dout(10) << __func__ << ": " << op << dendl;
switch (op->get_req()->get_type()) {
...
case MSG_OSD_REPOP: {
sub_op_modify(op);
return true;
}
}
下面我们看下,Replica OSD收到信息之后,在sub_op_modify函数执行了什么操作:
// sub op modify
void ReplicatedBackend::sub_op_modify(OpRequestRef op)
{
MOSDRepOp *m = static_cast<MOSDRepOp *>(op->get_req());
m->finish_decode();
int msg_type = m->get_type();
assert(MSG_OSD_REPOP == msg_type);
const hobject_t& soid = m->poid;
dout(10) << "sub_op_modify trans"
<< " " << soid
<< " v " << m->version
<< (m->logbl.length() ? " (transaction)" : " (parallel exec")
<< " " << m->logbl.length()
<< dendl;
// sanity checks
assert(m->map_epoch >= get_info().history.same_interval_since);
// we better not be missing this.
assert(!parent->get_log().get_missing().is_missing(soid));
int ackerosd = m->get_source().num();
op->mark_started();
RepModifyRef rm(std::make_shared<RepModify>());
rm->op = op;
rm->ackerosd = ackerosd;
rm->last_complete = get_info().last_complete;
rm->epoch_started = get_osdmap()->get_epoch();
assert(m->logbl.length());
// shipped transaction and log entries
vector<pg_log_entry_t> log;
bufferlist::iterator p = m->get_data().begin();
::decode(rm->opt, p);
if (m->new_temp_oid != hobject_t()) {
dout(20) << __func__ << " start tracking temp " << m->new_temp_oid << dendl;
add_temp_obj(m->new_temp_oid);
}
if (m->discard_temp_oid != hobject_t()) {
dout(20) << __func__ << " stop tracking temp " << m->discard_temp_oid << dendl;
if (rm->opt.empty()) {
dout(10) << __func__ << ": removing object " << m->discard_temp_oid
<< " since we won't get the transaction" << dendl;
rm->localt.remove(coll, ghobject_t(m->discard_temp_oid));
}
clear_temp_obj(m->discard_temp_oid);
}
p = m->logbl.begin();
::decode(log, p);
rm->opt.set_fadvise_flag(CEPH_OSD_OP_FLAG_FADVISE_DONTNEED);
bool update_snaps = false;
if (!rm->opt.empty()) {
// If the opt is non-empty, we infer we are before
// last_backfill (according to the primary, not our
// not-quite-accurate value), and should update the
// collections now. Otherwise, we do it later on push.
update_snaps = true;
}
parent->update_stats(m->pg_stats);
parent->log_operation(
log,
m->updated_hit_set_history,
m->pg_trim_to,
m->pg_trim_rollback_to,
update_snaps,
rm->localt);
rm->opt.register_on_commit(
parent->bless_context(
new C_OSD_RepModifyCommit(this, rm)));
rm->localt.register_on_applied(
parent->bless_context(
new C_OSD_RepModifyApply(this, rm)));
vector<ObjectStore::Transaction> tls;
tls.reserve(2);
tls.push_back(std::move(rm->localt));
tls.push_back(std::move(rm->opt));
parent->queue_transactions(tls, op);
// op is cleaned up by oncommit/onapply when both are executed
}
这段代码非常有意思,如果有心的同志,可以注意到Primary OSD 和这一段代码对应的部分:即
void ReplicatedBackend::submit_transaction(
const hobject_t &soid,
const eversion_t &at_version,
PGTransactionUPtr &&_t,
const eversion_t &trim_to,
const eversion_t &trim_rollback_to,
const vector<pg_log_entry_t> &log_entries,
boost::optional<pg_hit_set_history_t> &hset_history,
Context *on_local_applied_sync,
Context *on_all_acked,
Context *on_all_commit,
ceph_tid_t tid,
osd_reqid_t reqid,
OpRequestRef orig_op)
{
...
if (!(t->get_temp_added().empty())) {
add_temp_objs(t->get_temp_added());
}
clear_temp_objs(t->get_temp_cleared());
parent->log_operation(
log_entries,
hset_history,
trim_to,
trim_rollback_to,
true,
op_t);
op_t.register_on_applied_sync(on_local_applied_sync);
op_t.register_on_applied(
parent->bless_context(
new C_OSD_OnOpApplied(this, &op)));
op_t.register_on_commit(
parent->bless_context(
new C_OSD_OnOpCommit(this, &op)));
vector<ObjectStore::Transaction> tls;
tls.push_back(std::move(op_t));
parent->queue_transactions(tls, op.op);
}
代码非常的像对不对,原因是很简单的,即Primary OSD 和Replica OSD 本身要执行的操作,原本是一样的,只不过存在Primary OSD肩负着和Client通信的责任,而Replica 并没有这种责任,但是Replica需要及时向Primary OSD汇报进度。
如何上报进度?
注意Primary执行的ReplicatedBackend::submit_transaction函数和Replica OSD执行的ReplicatedBackend::sub_op_modify 函数都有一段很有意思的回调注册部分:
Primary OSD在submit_transaction函数中:
-----------------------
op_t.register_on_applied(
parent->bless_context(
new C_OSD_OnOpApplied(this, &op)));
op_t.register_on_commit(
parent->bless_context(
new C_OSD_OnOpCommit(this, &op)));
Replica OSD 在 sub_op_modify函数中:
-------------------------
rm->opt.register_on_commit(
parent->bless_context(
new C_OSD_RepModifyCommit(this, rm)));
rm->localt.register_on_applied(
parent->bless_context(
new C_OSD_RepModifyApply(this, rm)));
ceph的代码中,存在大量的回调函数,回调机制是一个非常重要的机制。事先注册,待到何时的时间点,触发执行回调函数,就如同诸葛亮给赵云的三个锦囊。对于写入来讲,每个OSD无论是Primary还是Replica,都有两个关键的milestone
- commit
- apply
对于第一个milestone表示已经写入到了osd的journal,此时表示已经完成commit,第二个milestone曾为applied,表示已经写入OSD的data partition。完成任何一个milestone,都要执行相关的回调。
我们本文不会介绍写入Journal和写入disk 部分的代码流程,因为这是下一篇博客的使命,我们只介绍,当Replica OSD完成了每一个milestone,会做哪些事情:
struct ReplicatedBackend::C_OSD_RepModifyApply : public Context {
ReplicatedBackend *pg;
RepModifyRef rm;
C_OSD_RepModifyApply(ReplicatedBackend *pg, RepModifyRef r)
: pg(pg), rm(r) {}
void finish(int r) {
pg->sub_op_modify_applied(rm);
}
};
struct ReplicatedBackend::C_OSD_RepModifyCommit : public Context {
ReplicatedBackend *pg;
RepModifyRef rm;
C_OSD_RepModifyCommit(ReplicatedBackend *pg, RepModifyRef r)
: pg(pg), rm(r) {}
void finish(int r) {
pg->sub_op_modify_commit(rm);
}
};
这两个回调,其实很明显,就是给Primary OSD发送消息,通知Primary OSD 对应的milestone已经完成。
void ReplicatedBackend::sub_op_modify_commit(RepModifyRef rm)
{
rm->op->mark_commit_sent();
rm->committed = true;
// send commit.
dout(10) << "sub_op_modify_commit on op " << *rm->op->get_req()
<< ", sending commit to osd." << rm->ackerosd
<< dendl;
assert(get_osdmap()->is_up(rm->ackerosd));
get_parent()->update_last_complete_ondisk(rm->last_complete);
Message *m = rm->op->get_req();
Message *commit = NULL;
if (m->get_type() == MSG_OSD_SUBOP) {
...
} else if (m->get_type() == MSG_OSD_REPOP) {
//给Primary OSD回消息
MOSDRepOpReply *reply = new MOSDRepOpReply(
static_cast<MOSDRepOp*>(m),
get_parent()->whoami_shard(),
0, get_osdmap()->get_epoch(), CEPH_OSD_FLAG_ONDISK);
reply->set_last_complete_ondisk(rm->last_complete);
commit = reply;
}
else {
assert(0);
}
commit->set_priority(CEPH_MSG_PRIO_HIGH); // this better match ack priority!
get_parent()->send_message_osd_cluster(
rm->ackerosd, commit, get_osdmap()->get_epoch());
log_subop_stats(get_parent()->get_logger(), rm->op, l_osd_sop_w);
}
void ReplicatedBackend::sub_op_modify_applied(RepModifyRef rm)
{
rm->op->mark_event("sub_op_applied");
rm->applied = true;
dout(10) << "sub_op_modify_applied on " << rm << " op "
<< *rm->op->get_req() << dendl;
Message *m = rm->op->get_req();
Message *ack = NULL;
eversion_t version;
if (m->get_type() == MSG_OSD_SUBOP) {
...
} else if (m->get_type() == MSG_OSD_REPOP) {
MOSDRepOp *req = static_cast<MOSDRepOp*>(m);
version = req->version;
if (!rm->committed)
ack = new MOSDRepOpReply(
static_cast<MOSDRepOp*>(m), parent->whoami_shard(),
0, get_osdmap()->get_epoch(), CEPH_OSD_FLAG_ACK);
} else {
assert(0);
}
// send ack to acker only if we haven't sent a commit already
if (ack) {
ack->set_priority(CEPH_MSG_PRIO_HIGH); // this better match commit priority!
get_parent()->send_message_osd_cluster(
rm->ackerosd, ack, get_osdmap()->get_epoch());
}
parent->op_applied(version);
}
Replica OSD在每个MileStone给Primary OSD发送的消息类型都是一样的,都是MSG_OSD_REPOPREPLY
MOSDRepOpReply(
MOSDRepOp *req, pg_shard_t from, int result_, epoch_t e, int at) :
Message(MSG_OSD_REPOPREPLY, HEAD_VERSION, COMPAT_VERSION),
map_epoch(e),
reqid(req->reqid),
from(from),
pgid(req->pgid.pgid, req->from.shard),
ack_type(at),
result(result_),
final_decode_needed(false) {
set_tid(req->get_tid());
}
区别在于ack_type不同,一种是CEPH_OSD_FLAG_ONDISK,另一种是CEPH_OSD_FLAG_ACK。
Replica OSD 向Primary OSD发送了 MSG_OSD_REPOPREPLY 消息,处理流程和本文的前两张图一样,不同之处是do_request函数中的hanle_message会处理这种类型的消息:
bool ReplicatedBackend::handle_message(
OpRequestRef op
)
{
case MSG_OSD_REPOPREPLY: {
sub_op_modify_reply(op);
return true;
}
}
void ReplicatedBackend::sub_op_modify_reply(OpRequestRef op)
{
MOSDRepOpReply *r = static_cast<MOSDRepOpReply *>(op->get_req());
r->finish_decode();
assert(r->get_header().type == MSG_OSD_REPOPREPLY);
op->mark_started();
// must be replication.
ceph_tid_t rep_tid = r->get_tid();
pg_shard_t from = r->from;
if (in_progress_ops.count(rep_tid)) {
map<ceph_tid_t, InProgressOp>::iterator iter =
in_progress_ops.find(rep_tid);
InProgressOp &ip_op = iter->second;
MOSDOp *m = NULL;
if (ip_op.op)
m = static_cast<MOSDOp *>(ip_op.op->get_req());
if (m)
dout(7) << __func__ << ": tid " << ip_op.tid << " op " //<< *m
<< " ack_type " << (int)r->ack_type
<< " from " << from
<< dendl;
else
dout(7) << __func__ << ": tid " << ip_op.tid << " (no op) "
<< " ack_type " << (int)r->ack_type
<< " from " << from
<< dendl;
// oh, good.
if (r->ack_type & CEPH_OSD_FLAG_ONDISK) {
assert(ip_op.waiting_for_commit.count(from));
ip_op.waiting_for_commit.erase(from);
if (ip_op.op) {
ostringstream ss;
ss << "sub_op_commit_rec from " << from;
ip_op.op->mark_event(ss.str());
}
} else {
assert(ip_op.waiting_for_applied.count(from));
if (ip_op.op) {
ostringstream ss;
ss << "sub_op_applied_rec from " << from;
ip_op.op->mark_event(ss.str());
}
}
ip_op.waiting_for_applied.erase(from);
parent->update_peer_last_complete_ondisk(
from,
r->get_last_complete_ondisk());
if (ip_op.waiting_for_applied.empty() &&
ip_op.on_applied) {
ip_op.on_applied->complete(0);
ip_op.on_applied = 0;
}
if (ip_op.waiting_for_commit.empty() &&
ip_op.on_commit) {
ip_op.on_commit->complete(0);
ip_op.on_commit= 0;
}
if (ip_op.done()) {
assert(!ip_op.on_commit && !ip_op.on_applied);
in_progress_ops.erase(iter);
}
}
}
关于这个交互,后面介绍完FileStore部分之后,会再次梳理这部分逻辑,可以比较Primary OSD和 Replica OSD在处理上区别。