前言
从flashcache的创建开始,介绍flashcache在SSD上的layout和内存数据结构,简单地说就是数据组织形式。
sprintf(dmsetup_cmd, "echo 0 %lu flashcache %s %s %s %d 2 %lu %lu %d %lu %d %lu"
" | dmsetup create %s",
disk_devsize, disk_devname, ssd_devname, cachedev, cache_mode, block_size,
cache_size, associativity, disk_associativity, write_cache_only, md_block_size,
cachedev);
从flashcache之后的参数算起:
| dmc的成员 | dmsetup create中的参数 | 默认值 | 含义 | |
|---|---|---|---|---|
| disk_dev | disk_devname | 无 | 慢速块设备的名字 | |
| cache_dev | ssd_devname | 无 | SSD设备的名字 | |
| dm_vdevname | flashcache的名字 | 无 | flashcache起的名字 | |
| cache_mode | cache_mode | 无 | 三种合法值:write_back,write_through和write_around | |
| persistence(非dmc的成员变量) | 2 | 2 | 实际flashcache_ctr函数,即为flashcache_create服务,也为flashcache_load服务 | |
| block_size | block_size | 8 | 8个扇区即4K | |
| size | cache_size | 设备扇区总数/block_size, | 注意这个值的含义是block的个数,即总扇区除以block_size. | |
| assoc | associativity | 512 | 合法值为(256,8192)之间的2的整数幂,不包含256和8192 | |
| disk_assoc | ||||
| write_only_cache | write_cache_only | 0 | write_back模式有一个子模式,即write_only | |
| md_block_size | 8 | |||
| num_sets | dmc->size » dmc->assoc_shift | |||
影响flashcache布局的几个参数有:
- block_size: 默认情况下值为8,即8个扇区组成一个block,即block的大小为4KB
- size : block的个数
注意,注意在
//截止到此处,dmc->size是SSD设备的扇区个数,
//后面调用dmc->size /= (dmc->block_size)执行之后,才变成block的个数。
dmc->md_blocks = INDEX_TO_MD_BLOCK(dmc, dmc->size / dmc->block_size) + 1 + 1;
/*总扇区数减去md_block需要的扇区数,得到最多可以用于存放数据的扇区数*/
dmc->size -= dmc->md_blocks * MD_SECTORS_PER_BLOCK(dmc);
/*可以用来存放cache数据的block个数,默认情况下即4K的个数*/
dmc->size /= dmc->block_size;
/*注意,block是要组成set的,因此有assoc的概念,默认512个block组成一个set
*因此block的个数需要向下对齐512的倍数*/
dmc->size = (dmc->size / dmc->assoc) * dmc->assoc;
/*有了准确的block的个数,需要的meta data block重新计算*/
dmc->md_blocks = INDEX_TO_MD_BLOCK(dmc, dmc->size) + 1 + 1;
DMINFO("flashcache_writeback_create: md_blocks = %d, md_sectors = %d\n",
dmc->md_blocks, dmc->md_blocks * MD_SECTORS_PER_BLOCK(dmc));
dev_size = to_sector(dmc->cache_dev->bdev->bd_inode->i_size);
cache_size = dmc->md_blocks * MD_SECTORS_PER_BLOCK(dmc) + (dmc->size * dmc->block_size);
if (cache_size > dev_size) {
DMERR("Requested cache size exceeds the cache device's capacity" \
"(%lu>%lu)",
cache_size, dev_size);
vfree((void *)header);
return 1;
}
这段代码的执行过后,我们基本就能对flashcache的组织形式有一定的了解了。首先是8个扇区做成一个block,然后是512个block组成一个set,这样的话,一个set的大小为2M,将SSD整体空间扣除meta需要的部分之后,组织成这样的结构:
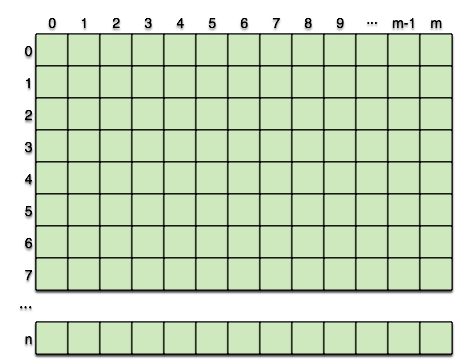
注意,这只是cache block的部分,对于flashcache来说,还有metadata block和superblock。和文件系统一样,flashcache也有superblock,介绍flashcache的组织形式:
header = (struct flash_superblock *)vmalloc(MD_BLOCK_BYTES(dmc));
if (!header) {
DMERR("flashcache_writeback_create: Unable to allocate sector");
return 1;
}
struct flash_superblock {
sector_t size; /* Cache size */
u_int32_t block_size; /* Cache block size */
u_int32_t assoc; /* Cache associativity */
u_int32_t cache_sb_state; /* Clean shutdown ? */
char cache_devname[DEV_PATHLEN]; /* Contains dm_vdev name as of v2 modifications */
sector_t cache_devsize;
char disk_devname[DEV_PATHLEN]; /* underlying block device name (use UUID paths!) */
sector_t disk_devsize;
u_int32_t cache_version;
u_int32_t md_block_size;
u_int32_t disk_assoc;
u_int32_t write_only_cache;
};
尽管flashcache的superblock需要的空间比较小,但是flashcache给superblock预留了一个meta data block的大小,即默认情况下4KB的大小,为将来可能的扩展预留的空间。
flash_superblock这个数据结构存在在SSD这个设备的第一个4K,当机器重启之后,flashcache_load会阅读该设备,确保头部扇区中存放的内容,即superblock的内容:
ssd_devname = argv[optind++];
cache_fd = open(ssd_devname, O_RDONLY);
if (cache_fd < 0) {
fprintf(stderr, "Failed to open %s\n", ssd_devname);
exit(1);
}
lseek(cache_fd, 0, SEEK_SET);
if (read(cache_fd, buf, 512) < 0) {
fprintf(stderr, "Cannot read Flashcache superblock %s\n", ssd_devname);
exit(1);
}
if (!(sb->cache_sb_state == CACHE_MD_STATE_DIRTY ||
sb->cache_sb_state == CACHE_MD_STATE_CLEAN ||
sb->cache_sb_state == CACHE_MD_STATE_FASTCLEAN ||
sb->cache_sb_state == CACHE_MD_STATE_UNSTABLE)) {
fprintf(stderr, "%s: Invalid Flashcache superblock %s\n", pname, ssd_devname);
exit(1);
}
创建flashcache的时候,flashcache_create也会阅读SSD设备的第一个扇区,来确保SSD是不是已经创建了flashcache。
对于上面网格图中的任何一个cache block,都需要数据结构来描述其状态,比如值是否有效,是否DIRTY等,其数据结构如下:
#ifdef FLASHCACHE_DO_CHECKSUMS
struct flash_cacheblock {
sector_t dbn; /* Sector number of the cached block */
u_int64_t checksum;
u_int32_t cache_state; /* INVALID | VALID | DIRTY */
} __attribute__ ((aligned(32)));
#else
struct flash_cacheblock {
sector_t dbn; /* Sector number of the cached block */
u_int32_t cache_state; /* INVALID | VALID | DIRTY */
} __attribute__ ((aligned(16)));
#endif
对于我们而言,flash_cacheblock的大小为16字节,因此,每个cache block都会有16字节的元数据。这16字节描述了一个cache block。每个meta data block 默认有4KB,即每个meta data block可以存放256 个cache block的元数据信息。
综合上述讨论,一个完整的SSD layout如下所示:
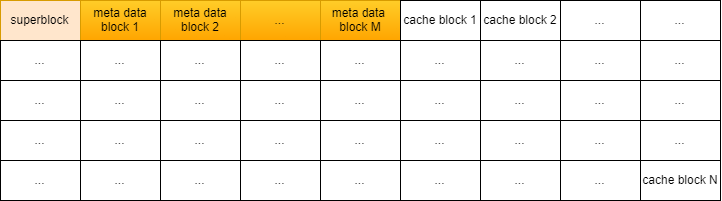
上面的布局,主要是块设备上的布局,除此外,flashcache正常运行期间,需要消耗内存,内存中有数据结构管理这些cache block,如下所示:
order = dmc->size * sizeof(struct cacheblock);
struct cacheblock {
u_int16_t cache_state;
int16_t nr_queued; /* jobs in pending queue */
u_int16_t lru_prev, lru_next;
u_int8_t use_cnt;
u_int8_t lru_state;
sector_t dbn; /* Sector number of the cached block */
u_int16_t hash_prev, hash_next;
#ifdef FLASHCACHE_DO_CHECKSUMS
u_int64_t checksum;
#endif
} __attribute__((packed));
目前来讲,不考虑checksum,内存中18 Byte 描述一个cache block(默认4KB)。
order = dmc->size * sizeof(struct cacheblock);
DMINFO("Allocate %luKB (%luB per) mem for %lu-entry cache" \
"(capacity:%luMB, associativity:%u, block size:%u " \
"sectors(%uKB))",
order >> 10, sizeof(struct cacheblock), dmc->size,
cache_size >> (20-SECTOR_SHIFT), dmc->assoc, dmc->block_size,
dmc->block_size >> (10-SECTOR_SHIFT));
dmc->cache = (struct cacheblock *)vmalloc(order);
if (!dmc->cache) {
vfree((void *)header);
DMERR("flashcache_writeback_create: Unable to allocate cache md");
return 1;
}
memset(dmc->cache, 0, order);
/* Initialize the cache structs */
for (i = 0; i < dmc->size ; i++) {
dmc->cache[i].dbn = 0;
#ifdef FLASHCACHE_DO_CHECKSUMS
dmc->cache[i].checksum = 0;
#endif
dmc->cache[i].cache_state = INVALID;
dmc->cache[i].lru_state = 0;
dmc->cache[i].nr_queued = 0;
}
通过这个18 Byte的内存描述一个flashcache 的cache block,我们可以估算,一个400G 的SSD作为flashcache的SSD部分,消耗的内存约为:
400G/4KB*18 = 1.8GB
cache_set
dmc的assoc 默认是512,表示512个block组成一个set,即512*4K= 2MB:
init:
/*计算整个flashcache set的个数*/
dmc->num_sets = dmc->size >> dmc->assoc_shift;
order = dmc->num_sets * sizeof(struct cache_set);
dmc->cache_sets = (struct cache_set *)vmalloc(order);
if (!dmc->cache_sets) {
ti->error = "Unable to allocate memory";
r = -ENOMEM;
vfree((void *)dmc->cache);
goto bad3;
}
memset(dmc->cache_sets, 0, order);
for (i = 0 ; i < dmc->num_sets ; i++) {
dmc->cache_sets[i].set_fifo_next = i * dmc->assoc;
dmc->cache_sets[i].set_clean_next = i * dmc->assoc;
dmc->cache_sets[i].fallow_tstamp = jiffies;
dmc->cache_sets[i].fallow_next_cleaning = jiffies;
dmc->cache_sets[i].hotlist_lru_tail = FLASHCACHE_NULL;
dmc->cache_sets[i].hotlist_lru_head = FLASHCACHE_NULL;
dmc->cache_sets[i].warmlist_lru_tail = FLASHCACHE_NULL;
dmc->cache_sets[i].warmlist_lru_head = FLASHCACHE_NULL;
spin_lock_init(&dmc->cache_sets[i].set_spin_lock);
}
对于每个set有单独的数据结构描述:
struct cache_set {
spinlock_t set_spin_lock;
u_int32_t set_fifo_next;
u_int32_t set_clean_next;
u_int16_t clean_inprog;
u_int16_t nr_dirty;
u_int16_t dirty_fallow;
unsigned long fallow_tstamp;
unsigned long fallow_next_cleaning;
/*
* 2 LRU queues/cache set.
* 1) A block is faulted into the MRU end of the warm list from disk.
* 2) When the # of accesses hits a threshold, it is promoted to the
* (MRU) end of the hot list. To keep the lists in equilibrium, the
* LRU block from the host list moves to the MRU end of the warm list.
* 3) Within each list, an access will move the block to the MRU end.
* 4) Reclaims happen from the LRU end of the warm list. After reclaim
* we move a block from the LRU end of the hot list to the MRU end of
* the warm list.
*/
u_int16_t hotlist_lru_head, hotlist_lru_tail;
u_int16_t warmlist_lru_head, warmlist_lru_tail;
u_int16_t lru_hot_blocks, lru_warm_blocks;
#define NUM_BLOCK_HASH_BUCKETS 512
u_int16_t hash_buckets[NUM_BLOCK_HASH_BUCKETS];
u_int16_t invalid_head;
};
注意,对于同一个set的cache block而言,根据状态,位于三个不同的链表之中:
- INVALID
- invalid_head为头部的invalid 链表
- VALID
- hot:
- hotlist_lru_head为头部,hotlist_lru_tail为尾部的hot链表
- warm
- warmlist_lru_head为头部,warmlist_lru_tail为尾部的warm链表
- hot:
注意,一个cacheblock只会位于其中的一条链表之中,不会同时属于hot和warm,更不会同时属于invalid和warm。
在64位系统上,指针的长度是8Byte,如果用普通的链表,prev next就要消耗16B的空间,这样是比较浪费的,flashcache使用是的u_int16_t类型的,每一个cacheblock通过一个2字节的short值,记录前一个cacheblock的值和后一个cacheblock的值。注意该值是同一个set的index值,因为默认set只有512,所以,2Byte的short足够记录下。
注意,当cacheblock中没有任何数据的时候,它位于invalid链表中,即这个链表里面都没啥数据。毫无疑问,当新建的flashcache里面,其实并没有任何有用的数据,并不和SATA DISK的数据相关联,因此,都会位于invalid 链表。在flashcache_ctr之中有如下的语句:
for (i = 0 ; i < dmc->size ; i++) {
dmc->cache[i].hash_prev = FLASHCACHE_NULL;
dmc->cache[i].hash_next = FLASHCACHE_NULL;
/*注意,flashcache_ctr并非只有创建flashcache一种情况,
*还有flashcache使用了一段时间之后,重启机器后的flashcache_load
*因此,需要判断对应的cacheblock的cache_state状态值,来初始化到合适的链表*/
/*如果cache_state状态中VALID置位,则插入的flashcache_hash,方便查找*/
if (dmc->cache[i].cache_state & VALID) {
flashcache_hash_insert(dmc, i);
atomic_inc(&dmc->cached_blocks);
}
/*如果dirty,则dirty统计增加*/
if (dmc->cache[i].cache_state & DIRTY) {
dmc->cache_sets[i / dmc->assoc].nr_dirty++;
atomic_inc(&dmc->nr_dirty);
}
/*如果是新创建,或者该cacheblock并无有效数据,则插入Invalid链表
*对应新创建的flashcahce,所有的cacheblock都在invalid链表,
*注意,并不是1条链表,而是每个cacheset都有1条链表*/
if (dmc->cache[i].cache_state & INVALID)
flashcache_invalid_insert(dmc, i);
下面来介绍hotlist和warmlist,flashcache采用的缓存置换算法是LRU算法,它维护着2条链表:hot和warm。当然了,顾名思义,hot链表的数据更热,更不应该被置换出去。每条链表有head和tail,约靠近尾部的cacheblock,越热,越不应该被置换出去。
数据是被访问的,因此,频繁访问的数据,可能会从warm迁到(premote)hot,如果hot链表中最冷的数据(即靠近head的数据),也可能会被降级(demote)到warm中。
除此以外,可能某个cacheblock中存在合法的数据(VALID),但是由于新的io进来,第一反应肯定是会不会我请求的IO对应的地址 dbn恰好在flashcahce的中并且状态为VALID,如果找到皆大欢喜;如果找不到,第二反应是寻找一个无人用的cacheblock,即位于INVALID链表的cacheblock。如果很不幸,没有INVALID的cache block,所有的block都已经用了(VALID),这时候,就必须要寻找牺牲品了,即reclaim策略。
接下来我们以flashcache_read为例,详细介绍寻找cacheblock的方法。
寻找cacheblock
对于读请求,由函数flashcache_read负责处理,注意,对于那些注定不会进入cacheblock的读写,在进入flashcache_read之前都已经过滤掉了:
uncacheable = (unlikely(dmc->bypass_cache) ||
(to_sector(bio->bi_size) != dmc->block_size) ||
/*
* If the op is a READ, we serve it out of cache whenever possible,
* regardless of cacheablity
*/
(bio_data_dir(bio) == WRITE &&
((dmc->cache_mode == FLASHCACHE_WRITE_AROUND) ||
flashcache_uncacheable(dmc, bio))));
spin_unlock_irqrestore(&dmc->ioctl_lock, flags);
if (uncacheable) {
flashcache_setlocks_multiget(dmc, bio);
queued = flashcache_inval_blocks(dmc, bio);
flashcache_setlocks_multidrop(dmc, bio);
if (queued) {
if (unlikely(queued < 0))
flashcache_bio_endio(bio, -EIO, dmc, NULL);
} else {
/* Start uncached IO */
/*绕过flashcache,直接访问慢速设备*/
flashcache_start_uncached_io(dmc, bio);
}
} else {
/*如果io类型可以走flashcache,那么根据类型分别调用
*flashcache_read和flashcache_write*/
if (bio_data_dir(bio) == READ)
flashcache_read(dmc, bio);
else
flashcache_write(dmc, bio);
}
return DM_MAPIO_SUBMITTED;
剩下内容的重点是cacheblock的查找 置换的策略,什么io走flashcache,什么io直接访问慢速设备,并不是我们关心的内容。我们继续以flashcache_read为例,介绍寻找cacheblock的过程。
下面代码是查找cacheblock的方法,主要的寻找过程位于flashcache_lookup函数。
flashcache_setlocks_multiget(dmc, bio);
res = flashcache_lookup(dmc, bio, &index);
/* Cache Read Hit case */
if (res > 0) {
cacheblk = &dmc->cache[index];
if ((cacheblk->cache_state & VALID) &&
(cacheblk->dbn == bio->bi_sector)) {
flashcache_read_hit(dmc, bio, index);
return;
}
}
/*
* In all cases except for a cache hit (and VALID), test for potential
* invalidations that we need to do.
*/
queued = flashcache_inval_blocks(dmc, bio);
if (queued) {
if (unlikely(queued < 0))
flashcache_bio_endio(bio, -EIO, dmc, NULL);
if ((res > 0) &&
(dmc->cache[index].cache_state == INVALID))
/*
* If happened to pick up an INVALID block, put it back on the
* per cache-set invalid list
*/
flashcache_invalid_insert(dmc, index);
flashcache_setlocks_multidrop(dmc, bio);
return;
}
因为数据是流动的,因此整个flashcache N个cacheset,每个cacheset M个cache block,其状态都是流动的,刚才我可能是invalid,可能很快我就位于warmlist了,再有数据访问,我可能就迁移到了hotlist了。因此理解flashcache_lookup,知道当用户某一个请求要访问sector_t dbn = bio->bi_sector 这个扇区的时候,如何查找cacheblock是理解状态流动的非常关键的一步。
static int
flashcache_lookup(struct cache_c *dmc, struct bio *bio, int *index)
{
sector_t dbn = bio->bi_sector;
#if DMC_DEBUG
int io_size = to_sector(bio->bi_size);
#endif
unsigned long set_number = hash_block(dmc, dbn);
int invalid, oldest_clean = -1;
int start_index;
start_index = dmc->assoc * set_number;
DPRINTK("Cache lookup : dbn %llu(%lu), set = %d",
dbn, io_size, set_number);
find_valid_dbn(dmc, dbn, start_index, index);
if (*index >= 0) {
DPRINTK("Cache lookup HIT: Block %llu(%lu): VALID index %d",
dbn, io_size, *index);
/* We found the exact range of blocks we are looking for */
return VALID;
}
invalid = find_invalid_dbn(dmc, set_number);
if (invalid == -1) {
/* We didn't find an invalid entry, search for oldest valid entry */
find_reclaim_dbn(dmc, start_index, &oldest_clean);
}
/*
* Cache miss :
* We can't choose an entry marked INPROG, but choose the oldest
* INVALID or the oldest VALID entry.
*/
*index = start_index + dmc->assoc;
if (invalid != -1) {
DPRINTK("Cache lookup MISS (INVALID): dbn %llu(%lu), set = %d, index = %d, start_index = %d", dbn, io_size, set_number, invalid, start_index);
*index = invalid;
} else if (oldest_clean != -1) {
DPRINTK("Cache lookup MISS (VALID): dbn %llu(%lu), set = %d, index = %d, start_index = %d",
dbn, io_size, set_number, oldest_clean, start_index);
*index = oldest_clean;
} else {
DPRINTK_LITE("Cache read lookup MISS (NOROOM): dbn %llu(%lu), set = %d",
dbn, io_size, set_number);
}
if (*index < (start_index + dmc->assoc))
return INVALID;
else {
dmc->flashcache_stats.noroom++;
return -1;
}
}
注意,这就是寻找cacheblock的算法了。第一步是要寻找合适的set,因为flashcache默认情况下,每个set 512个cache block,首先要定位到那个cacheset,然后再cacheset中确定合适的cache block。通俗点说,就是分两步走:
- 找到合适的cache set
- 从该cache set中找到合适的cache block
第一步比较简单,根据bio的扇区号,计算hash,然后映射到对应的cache set:
unsigned long
hash_block(struct cache_c *dmc, sector_t dbn)
{
unsigned long set_number, value;
int num_cache_sets = dmc->size >> dmc->assoc_shift;
/*
* Starting in Flashcache SSD Version 3 :
* We map a sequential cluster of disk_assoc blocks onto a given set.
* But each disk_assoc cluster can be randomly placed in any set.
* But if we are running on an older on-ssd cache, we preserve old
* behavior.
*/
if (dmc->on_ssd_version < 3 || dmc->disk_assoc == 0) {
value = (unsigned long)
(dbn >> (dmc->block_shift + dmc->assoc_shift));
} else {
/*我们走本分支*/
value = (unsigned long) (dbn >> dmc->disk_assoc_shift);
/* Then place it in a random set */
value = jhash_1word(value, 0xbeef);
}
set_number = value % num_cache_sets;
DPRINTK("Hash: %llu(%lu)->%lu", dbn, value, set_number);
return set_number;
}
我们走else分支,这里面有一个参数,初看flashcache不容易理解,即disk_assoc_shift,这个参数在创建flashcache的时候可以指定disk_associativity :
root@XMT-S02:~# dmsetup table
osd4: 0 70316455903 flashcache conf:
ssd dev (/dev/disk/by-partlabel/osd4-ssd), disk dev (/dev/disk/by-partlabel/osd4-data) cache mode(WRITE_BACK)
capacity(446572M), associativity(512), data block size(4K) metadata block size(4096b)
disk assoc(256K)
skip sequential thresh(32K)
total blocks(114322432), cached blocks(96119380), cache percent(84)
dirty blocks(41155646), dirty percent(35)
nr_queued(0)
我们看到,默认情况下,disk assoc的值是256K,事实上这个控制选项发挥作用也就是在寻找合适的cache set中发挥控制作用,如果没有这个选项,直接拿dbn进行hash,然后map到cacheset,相邻的两个dbn,可能压根就不会位于同一个cache set,那么将来对同一个cache set的io进行merge也就没啥必要了,因为相邻的dbn在同一个set的可能性并不大。
有了这个disk assoc参数就不同了,它hash之前,首先执行:
value = (unsigned long) (dbn >> dmc->disk_assoc_shift);
它确保的是,在同一个256KB块内的扇区,最终会得到同一个value,然后hash会map到同一个cache set,将来就有可能将相邻的请求merge,从而提高性能。
除了此处不太好理解意外,其他基本就是算出hash值,然后对cache set的个数求余,来决定落在那个cache set中。
第一步已经解决了,接下来是第二部,如何在cache set中找到
其算法核心可以分成三部:
- find_valid_dbn
- find_invalid_dbn
- find_reclaim_dbn
find_valid_dbn
static void
find_valid_dbn(struct cache_c *dmc, sector_t dbn,
int start_index, int *index)
{
*index = flashcache_hash_lookup(dmc, start_index / dmc->assoc, dbn);
if (*index == -1)
return;
if (dmc->sysctl_reclaim_policy == FLASHCACHE_LRU &&
((dmc->cache[*index].cache_state & BLOCK_IO_INPROG) == 0))
flashcache_lru_accessed(dmc, *index);
/*
* If the block was DIRTY and earmarked for cleaning because it was old, make
* the block young again.
*/
flashcache_clear_fallow(dmc, *index);
}
int
flashcache_hash_lookup(struct cache_c *dmc,
int set,
sector_t dbn)
{
struct cache_set *cache_set = &dmc->cache_sets[set];
int index;
struct cacheblock *cacheblk;
u_int16_t set_ix;
#if 0
int start_index, end_index, i;
#endif
set_ix = *flashcache_get_hash_bucket(dmc, cache_set, dbn);
while (set_ix != FLASHCACHE_NULL) {
index = set * dmc->assoc + set_ix;
cacheblk = &dmc->cache[index];
/* Only VALID blocks on the hash queue */
VERIFY(cacheblk->cache_state & VALID);
VERIFY((cacheblk->cache_state & INVALID) == 0);
if (dbn == cacheblk->dbn)
return index;
set_ix = cacheblk->hash_next;
}
return -1;
}
static inline u_int16_t *
flashcache_get_hash_bucket(struct cache_c *dmc, struct cache_set *cache_set, sector_t dbn)
{
unsigned int hash = jhash_1word(dbn, 0xfeed);
return &cache_set->hash_buckets[hash % NUM_BLOCK_HASH_BUCKETS];
}
我们已经找到了cache set,默认情况下cache set中有512个cache block,这些cache block中是否有我们需要的扇区呢?
最容易想到的是,逐个cache block比对,看下dbn号是否一致,状态是否是VALID。但是这种方法太蠢,效率太低。正确的方法是hash。
如果cache block中存在有效数据,他会根据对应的扇区号 dbn来计算hash,放入cache set中的合适bucket中。这种hash的做法,加速了cache set内部对某dbn是否存在在某个cacheblock的查找。
对于读来讲最完美的情况是,请求要求的数据块,恰巧位于flashcache的SSD 设备中,这种情况称为读命中。如果命中的话,因为该cacheblock的数据,相当于获得一次有效的访问,那么当空间吃紧的时候,应该降低该block被替换出去的概率,即提升其热度。
if (dmc->sysctl_reclaim_policy == FLASHCACHE_LRU &&
((dmc->cache[*index].cache_state & BLOCK_IO_INPROG) == 0))
flashcache_lru_accessed(dmc, *index);
这个flashcache_lru_accessed函数,即某个cacheblock最近被访问时,需要执行的操作,代码中有一段注释,言简意赅地介绍了这部分的算法:
/*
* Block is accessed.
*
* Algorithm :
if (block is in the warm list) {
block_lru_refcnt++;
if (block_lru_refcnt >= THRESHOLD) {
clear refcnt
Swap this block for the block at LRU end of hot list
} else
move it to MRU end of the warm list
}
if (block is in the hot list)
move it to MRU end of the hot list
*/
- 如果block目前在warm list
- 引用计数++
- 如果引用计数大于等于门限值(sysctl_lru_promote_thresh),一般是2,则从warm list 移入 hot list的LRU端(最左端)
- 如果引用计数低于门限值,则从移入 warm list的MRU端,即最右端
- 引用计数++
- 如果block 目前在hot list
- 将该block移入hot list的MRU端,即最右端。
两个链表host list和warm list,其最左端都是LRU端(Least Recent Used), 其最右端是MRU端(Most Recent Used)。一旦需要置换,将某些cacheblock中的内容踢出出去,选择的顺序如下:
Worm List LRU -------->Worm List MRU--------->Hot List LRU -------------> Hot List MRU
代码部分就不列了,简单的链表操作。
从cache set中寻找cache block的第一步就完成,这种情况是最幸运的一种,即要读取的内容所在的扇区,恰好在flashcache的 SSD部分中,数据有效VALID,可以拿到cache block的index,因为本次访问,将该cache block的热度提升到合适的位置。
但是也许并没有这么幸运,SSD中没有dbn对应扇区的内容,这种情况下,需要选择一个cache block来盛放即将从 慢速设备的扇区中读取上来的内容。这种情况下,第一选择是选择一个并且投入使用的cache block,即INVALID状态的cache block。
Why?
如果不这么做,选择一个VALID状态的cache block,该cache block的内容就会被新的dbn的内容替换,那么该cache block中老的内容,就被逐出SSD了,如果紧接着发来一个访问cache block 中老的dbn扇区的内容的请求,就会造成miss。更恶劣的情况是该cache block的内容是dirty,flashcache 可能不得不先等待dirty内容flush下去之后,方能使用该cache block。
所以当命中已成不可能的时候,选择INVALID状态的cache block是上策:
find_invalid_dbn
static int
find_invalid_dbn(struct cache_c *dmc, int set)
{
int index = flashcache_invalid_get(dmc, set);
if (index != -1) {
if (dmc->sysctl_reclaim_policy == FLASHCACHE_LRU)
flashcache_lru_accessed(dmc, index);
VERIFY((dmc->cache[index].cache_state & FALLOW_DOCLEAN) == 0);
}
return index;
}
寻找INVALID状态的cache block比较简单,因为对于一个cache set而言,所有的invalid都位于invalid_head为头部的链表,只需要摘下头部的cache block就可以了
int
flashcache_invalid_get(struct cache_c *dmc, int set)
{
struct cache_set *cache_set;
int index;
struct cacheblock *cacheblk;
cache_set = &dmc->cache_sets[set];
index = cache_set->invalid_head;
if (index == FLASHCACHE_NULL)
return -1;
index += (set * dmc->assoc);
cacheblk = &dmc->cache[index];
VERIFY(cacheblk->cache_state == INVALID);
flashcache_invalid_remove(dmc, index);
return index;
}
同样的道理,因为该cache block从INVALID迁移到了warm list的MRU端。
其实这种情况还不错,因为还能找到闲置的cache block。随着flashcahe的使用,很可能这种情况也不可得。很可能该cache set下的所有的cache block都投入了战局,在该cache set已经找不到一块闲置的cache block了。
find_reclaim_dbn
这种情况下,就需要从投入使用的cacheblock中寻找一个牺牲品了,也就是cache block要回收了。优于SSD Dev和DIsk Dev大小的关系,不可能所有数据都存入SSD,所有的缓存算法都需要缓存替换算法,高效的缓存替换算法,能够获得更大的性能提升。
当选择牺牲品的时候,长期以来,我们维护hot list 和warm list的操作,就有了价值,这些信息给了我们选择牺牲品的依据。
static void
find_reclaim_dbn(struct cache_c *dmc, int start_index, int *index)
{
if (dmc->sysctl_reclaim_policy == FLASHCACHE_FIFO)
flashcache_reclaim_fifo_get_old_block(dmc, start_index, index);
else /* flashcache_reclaim_policy == FLASHCACHE_LRU */
flashcache_reclaim_lru_get_old_block(dmc, start_index, index);
}
Flashcache目前支持两种策略,FIFO和LRU。我们此处讨论LRU,这种算法就是将最近最不常使用的cache block替换出去。
代码给了注释:
/*
* Get least recently used LRU block
*
* Algorithm :
* Always pick block from the LRU end of the warm list.
* And move it to the MRU end of the warm list.
* If we don't find a suitable block in the "warm" list,
* pick the block from the hot list, demote it to the warm
* list and move a block from the warm list to the hot list.
*/
总是从worm list的LRU端找,然后把它移到MRU端。如果在warm list找不到合适的,那么从hot list的LRU端找,如果找到,执行demote操作,即将hot list的LRU和worm list MRU互换位置。
都是一些简单的链表操作,就不在此处贴代码了。