前言
上一篇介绍了MemTable Dump成SSTable的过程。包括Compaction的整体流程。但是Compaction并未介绍完毕。此处不得不横插一杠子,先介绍Version和VersionEdit以及VersionSet。原因是Compaction和Version相关的部分交织在一起,不搞明白Version很难理解Compaction。其实这句话反过来说也是对的,如果不理解Compaction也很难理解VersionSet。
VersionEdit
Version相关的数据结构有3个,Version VersionEdit and VersionSet。其中VersionEdit顾名思义,是编辑或修改Version,它记录的是两个Version之间的差异。简单的说
Version0 + VersionEdit = Version1
对于VersionEdit,有如下成员变量:
private:
friend class VersionSet;
typedef std::set< std::pair<int, uint64_t> > DeletedFileSet;
std::string comparator_;
uint64_t log_number_;
uint64_t prev_log_number_;
uint64_t next_file_number_;
SequenceNumber last_sequence_;
bool has_comparator_;
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
std::vector< std::pair<int, InternalKey> > compact_pointers_;
DeletedFileSet deleted_files_;
std::vector< std::pair<int, FileMetaData> > new_files_;
LevelDB中的文件主要的文件有 数据文件即sstable 文件, log文件,manifest文件,current文件(指向当前的manifest),LOG文件和lock文件,而VersionEdit中,最重要的3个成员变量是:
std::vector< std::pair<int, InternalKey> > compact_pointers_;
DeletedFileSet deleted_files_;
std::vector< std::pair<int, FileMetaData> > new_files_;
第一个compact_pointers按下不表,第二个和第三个顾名思义,就是相对于上一个Version,新的Version新增了那些文件以及删除了那些文件。 注意,从一个版本到到另一个版本的过渡,是由Compaction引起的。
Compaction分成两种:Minor Compaction和Major Compaction。
Minor Compaction是说,用户输入的key-value足够多了,需要讲memtable转成immutable memtable,然后讲immutable memtable dump成 sstable,而这种情况下,sstable文件多了一个,而能属于level0,也能属于level1或者level2。这种情况下,我们成为version发生了变化,需要升级版本。这种情况比较简单,基本上是新增一个文件。
Major Compaction 要复杂一些,它牵扯到两个Level的文件。它会计算出重叠部分的文件,然后归并排序,merge成新的sstable文件,一旦新的文件merge完毕,老的文件也就没啥用了。因此对于这种Compaction除了new_files_还有deleted_files_(当然还有compaction_pointers_)。
为了更深入地理解version以及后面的Compaction,我们需要介绍下FileMetaData这个数据结构,这个数据结构非常的重要,正是因为存在这个数据结构,才能很方面的选择which文件需要Compaction。
struct FileMetaData {
int refs;
int allowed_seeks; // Seeks allowed until compaction
uint64_t number;
uint64_t file_size; // File size in bytes
InternalKey smallest; // Smallest internal key served by table
InternalKey largest; // Largest internal key served by table
FileMetaData() : refs(0), allowed_seeks(1 << 30), file_size(0) { }
};
注意sstable文件的名字是 number.sst 如11423.sst这种格式,只要一个number就可以表示该SSTable文件的名字,除此外还存放着该SSTable文件的长度。因为SSTable文件里面的键值是有序的,因此,最大的key和最小的key就足矣描述key的范围。
Version and VersionSet and MVCC
对于同一笔记录,如果读和写同一时间发生,reader可能读到不一致的数据或者是修改了一半的数据。对于这种情况,有三种常见的解决方法:
悲观锁 最简单的处理方式,就是加锁保护,写的时候不许读,读的时候不许写。效率低。
乐观锁 它假设多用户并发的事物在处理时不会彼此互相影响,各食物能够在不产生锁的的情况下处理各自影响的那部分数据。
在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。
如果其他事务有更新的话,正在提交的事务会进行回滚;这样做不会有锁竞争更不会产生死锁,
但如果数据竞争的概率较高,效率也会受影响 。
MVCC MVCC是一个数据库常用的概念。Multiversion concurrency control多版本并发控制。每一个执行操作的用户,
看到的都是数据库特定时刻的的快照(snapshot), writer的任何未完成的修改都不会被其他的用户所看到;
当对数据进行更新的时候并是不直接覆盖,而是先进行标记, 然后在其他地方添加新的数据,从而形成一个新版本,
此时再来读取的reader看到的就是最新的版本了。所以这种处理策略是维护了多个版本的数据的,但只有一个是最新的。
sstable级别的MVCC就是利用Version实现的。
- 只有一个current version,持有最新的sstable集合。
- VersionEdit 代表一次更新,新增了哪些sstable file,以及删除了哪些sstable file
那么我们来看Version类的定义:
class Version {
public:
void AddIterators(const ReadOptions&, std::vector<Iterator*>* iters);
struct GetStats {
FileMetaData* seek_file;
int seek_file_level;
};
Status Get(const ReadOptions&, const LookupKey& key, std::string* val,
GetStats* stats);
bool UpdateStats(const GetStats& stats);
// Record a sample of bytes read at the specified internal key.
// Samples are taken approximately once every config::kReadBytesPeriod
// bytes. Returns true if a new compaction may need to be triggered.
// REQUIRES: lock is held
bool RecordReadSample(Slice key);
// Reference count management (so Versions do not disappear out from
// under live iterators)
void Ref();
void Unref();
void GetOverlappingInputs(
int level,
const InternalKey* begin, // NULL means before all keys
const InternalKey* end, // NULL means after all keys
std::vector<FileMetaData*>* inputs);
// Returns true iff some file in the specified level overlaps
// some part of [*smallest_user_key,*largest_user_key].
// smallest_user_key==NULL represents a key smaller than all keys in the DB.
// largest_user_key==NULL represents a key largest than all keys in the DB.
bool OverlapInLevel(int level,
const Slice* smallest_user_key,
const Slice* largest_user_key);
/*该函数用来选择 需要将从MemTable dump出的sstable file放入第几层*/
int PickLevelForMemTableOutput(const Slice& smallest_user_key,
const Slice& largest_user_key);
/*判断某层level的文件个数*/
int NumFiles(int level) const { return files_[level].size(); }
// Return a human readable string that describes this version's contents.
std::string DebugString() const;
private:
friend class Compaction;
friend class VersionSet;
class LevelFileNumIterator;
Iterator* NewConcatenatingIterator(const ReadOptions&, int level) const;
// Call func(arg, level, f) for every file that overlaps user_key in
// order from newest to oldest. If an invocation of func returns
// false, makes no more calls.
//
// REQUIRES: user portion of internal_key == user_key.
void ForEachOverlapping(Slice user_key, Slice internal_key,
void* arg,
bool (*func)(void*, int, FileMetaData*));
/*所有的version都属于一个集合即Version Set*/
VersionSet* vset_;
/*VersionSet是Version组成的双链表,因此Version需要记录前一个Version和后一个Version*/
Version* next_;
Version* prev_;
int refs_;
/*该version下的所有level的所有sstable文件,每个文件由FileMetaData表示*/
std::vector<FileMetaData*> files_[config::kNumLevels];
// Next file to compact based on seek stats.
FileMetaData* file_to_compact_;
int file_to_compact_level_;
/********************************************************************
*Compaction需要用compaction_score_来判断是否需要发起major compaction
* 这部分逻辑与某level所有SSTable file的大小有关系
********************************************************************/
double compaction_score_;
int compaction_level_;
explicit Version(VersionSet* vset)
: vset_(vset), next_(this), prev_(this), refs_(0),
file_to_compact_(NULL),
file_to_compact_level_(-1),
compaction_score_(-1),
compaction_level_(-1) {
}
~Version();
// No copying allowed
Version(const Version&);
void operator=(const Version&);
};
LevelDB将所有的Version置于一个双向链表之中,即位于一个集合之中。这样所有的Version组成一个名为VersionSet的结构。
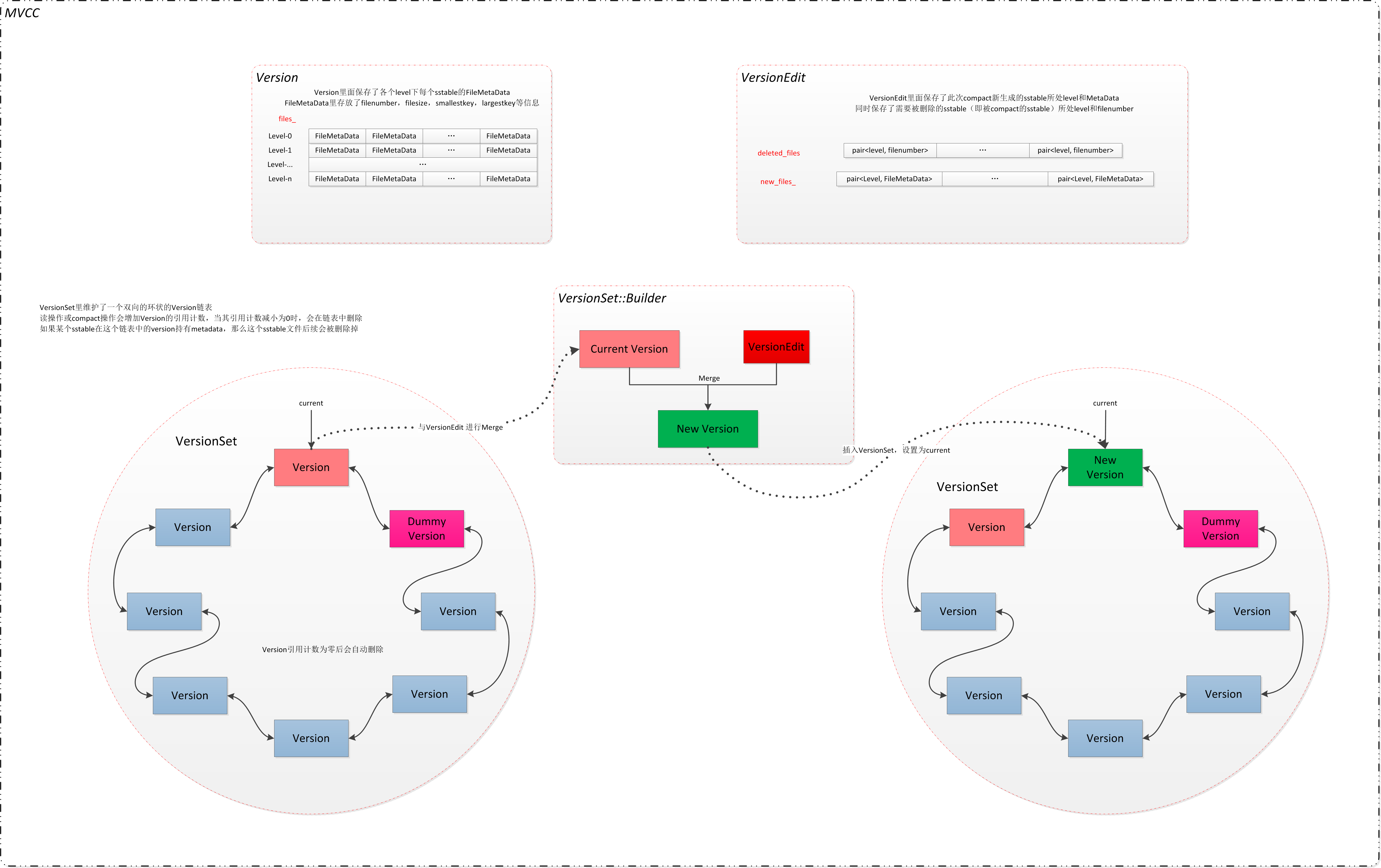
LevelDB会触发Compaction,会对一些文件进行清理操作,让数据更加有序,清理后的数据放到新的版本里面,而老的数据作为原始的素材,最终是要清理掉的,但是如果有读事务位于旧的文件,那么暂时就不能删除。因此利用引用计数,只要一个Verison还活着,就不允许删除该Verison管理的所有文件。当一个Version生命周期结束,它管理的所有文件的引用计数减1.
Version::~Version() {
assert(refs_ == 0);
/* 从VersionSet中注销 */
prev_->next_ = next_;
next_->prev_ = prev_;
/*本Version下所有的文件,引用计数减1*/
for (int level = 0; level < config::kNumLevels; level++) {
for (size_t i = 0; i < files_[level].size(); i++) {
FileMetaData* f = files_[level][i];
assert(f->refs > 0);
f->refs--;
if (f->refs <= 0) {
delete f;
}
}
}
}
从上图我们看到了,从Version 升级到另一个Version中间靠的是VersionEdit。VersionEdit告诉我们哪些文件可以删除了,哪些文件是新增的。这个过程是LogAndApply。为了方便实现
Version(N) + VersionEdit(N) = Version(N+1)
引入了Build数据结构,这个数据结构是一个helper类,帮忙实现Version的跃升。我们下面重点分析LogAndApply。
LogAndApply
调用LogAndApply的时机有4个,其中第一个是打开DB的时候,其余3个都与Compaction有关系。
-
Open DB 的时候,有些记录在上一次操作中,可能有一些记录只在log中,并未写入sstable,因此需要replay, 有点类似journal文件系统断电之后的replay操作。
- Immutable MemTable dump成SStable之后,调用LogAndApply
- 如果是非manual,同时仅仅是sstable文件简单地在不同level之间移动,并不牵扯两个不同level的sstable之间归并排序,就直接调用LogAndApply
- Major Compaction,不同level的文件存在交叉,需要归并排序,生成新的不交叉重叠的sstable文件,同时可能将老的文件废弃。
如下图所示:

对于Compaction而言,它的作用是 : 或者是通过MemTable dump,生成新的sstable文件(一般是level0 或者是level1或者是level2),在一定的时机下,整理已有的sstable,通过归并排序,将某些文件推向更高的level,让数据集合变得更加有序。
生成完毕新文件后,需要产生新的version,这就是LogAndApply的做的事情。
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
if (edit->has_log_number_) {
assert(edit->log_number_ >= log_number_);
assert(edit->log_number_ < next_file_number_);
} else {
edit->SetLogNumber(log_number_);
}
if (!edit->has_prev_log_number_) {
edit->SetPrevLogNumber(prev_log_number_);
}
edit->SetNextFile(next_file_number_);
edit->SetLastSequence(last_sequence_);
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
Finalize(v);
// Initialize new descriptor log file if necessary by creating
// a temporary file that contains a snapshot of the current version.
std::string new_manifest_file;
Status s;
if (descriptor_log_ == NULL) {
// No reason to unlock *mu here since we only hit this path in the
// first call to LogAndApply (when opening the database).
assert(descriptor_file_ == NULL);
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
edit->SetNextFile(next_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
descriptor_log_ = new log::Writer(descriptor_file_);
s = WriteSnapshot(descriptor_log_);
}
}
// Unlock during expensive MANIFEST log write
{
mu->Unlock();
// Write new record to MANIFEST log
if (s.ok()) {
std::string record;
edit->EncodeTo(&record);
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());
}
}
// If we just created a new descriptor file, install it by writing a
// new CURRENT file that points to it.
if (s.ok() && !new_manifest_file.empty()) {
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
// Install the new version
if (s.ok()) {
AppendVersion(v);
log_number_ = edit->log_number_;
prev_log_number_ = edit->prev_log_number_;
} else {
delete v;
if (!new_manifest_file.empty()) {
delete descriptor_log_;
delete descriptor_file_;
descriptor_log_ = NULL;
descriptor_file_ = NULL;
env_->DeleteFile(new_manifest_file);
}
}
return s;
}
构造Builder
首先是以当前的Version为基础,创建出来一个Build类,这个类是一个help类:
Builder builder(this, current_);
调用的构造函数如下:
Builder(VersionSet* vset, Version* base)
: vset_(vset),
base_(base) {
base_->Ref();
BySmallestKey cmp;
cmp.internal_comparator = &vset_->icmp_;
for (int level = 0; level < config::kNumLevels; level++) {
levels_[level].added_files = new FileSet(cmp);
}
}
对于Builder这个类,基本的成员有:
typedef std::set<FileMetaData*, BySmallestKey> FileSet;
struct LevelState {
std::set<uint64_t> deleted_files;
FileSet* added_files;
};
VersionSet* vset_;
Version* base_;
LevelState levels_[config::kNumLevels];
初始化的时候,base_这个指针指向current_ 而,vset_指针指向vset,即当前VersionSet。至于各个level的文件,初始化成空的集合。
apply
builder.Apply(edit);
这一步是将版本与版本的变化部分VersionEdit 记录在Builder
// Apply all of the edits in *edit to the current state.
/*此处不好理解,后面讲到Compaction的部分再来分析*/
void Apply(VersionEdit* edit) {
// Update compaction pointers
for (size_t i = 0; i < edit->compact_pointers_.size(); i++) {
const int level = edit->compact_pointers_[i].first;
vset_->compact_pointer_[level] =
edit->compact_pointers_[i].second.Encode().ToString();
}
/*将删除部分的文件,包括文件所属的层级,记录在Builder的数据结构中
*删除的文件,只需要记录sstable文件的数字就可以了*/
const VersionEdit::DeletedFileSet& del = edit->deleted_files_;
for (VersionEdit::DeletedFileSet::const_iterator iter = del.begin();
iter != del.end();
++iter) {
const int level = iter->first;
const uint64_t number = iter->second;
levels_[level].deleted_files.insert(number);
}
/*处理新增文件部分,要将VersionEdit中的增加文件部分的整个FileMetaData都记录下来*/
for (size_t i = 0; i < edit->new_files_.size(); i++) {
const int level = edit->new_files_[i].first;
FileMetaData* f = new FileMetaData(edit->new_files_[i].second);
f->refs = 1;
// We arrange to automatically compact this file after
// a certain number of seeks. Let's assume:
// (1) One seek costs 10ms
// (2) Writing or reading 1MB costs 10ms (100MB/s)
// (3) A compaction of 1MB does 25MB of IO:
// 1MB read from this level
// 10-12MB read from next level (boundaries may be misaligned)
// 10-12MB written to next level
// This implies that 25 seeks cost the same as the compaction
// of 1MB of data. I.e., one seek costs approximately the
// same as the compaction of 40KB of data. We are a little
// conservative and allow approximately one seek for every 16KB
// of data before triggering a compaction.
f->allowed_seeks = (f->file_size / 16384);
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
levels_[level].deleted_files.erase(f->number);
levels_[level].added_files->insert(f);
}
}
对于文件也记录的allow_seeks这个字段,原因是触发Compaction,可能是因为某一个层级的file个数太多,总长度超过了指定的上限,也可能是因为某sstable seek的次数过多,此处并不展开讲解。
SaveTo
builder.SaveTo(v);
这一部分是根据Builder中的base_指向的当前版本current_, 以及在Apply部分记录的删除文件集合,新增文件集合和CompactionPointer集合,计算出一个新的Verison,保存在v中。
// Save the current state in *v.
void SaveTo(Version* v) {
BySmallestKey cmp;
cmp.internal_comparator = &vset_->icmp_;
for (int level = 0; level < config::kNumLevels; level++) {
// Merge the set of added files with the set of pre-existing files.
// Drop any deleted files. Store the result in *v.
const std::vector<FileMetaData*>& base_files = base_->files_[level];
std::vector<FileMetaData*>::const_iterator base_iter = base_files.begin();
std::vector<FileMetaData*>::const_iterator base_end = base_files.end();
const FileSet* added = levels_[level].added_files;
v->files_[level].reserve(base_files.size() + added->size());
for (FileSet::const_iterator added_iter = added->begin();
added_iter != added->end();
++added_iter) {
// Add all smaller files listed in base_
for (std::vector<FileMetaData*>::const_iterator bpos
= std::upper_bound(base_iter, base_end, *added_iter, cmp);
base_iter != bpos;
++base_iter) {
MaybeAddFile(v, level, *base_iter);
}
MaybeAddFile(v, level, *added_iter);
}
// Add remaining base files
for (; base_iter != base_end; ++base_iter) {
MaybeAddFile(v, level, *base_iter);
}
#ifndef NDEBUG
// Make sure there is no overlap in levels > 0
if (level > 0) {
for (uint32_t i = 1; i < v->files_[level].size(); i++) {
const InternalKey& prev_end = v->files_[level][i-1]->largest;
const InternalKey& this_begin = v->files_[level][i]->smallest;
if (vset_->icmp_.Compare(prev_end, this_begin) >= 0) {
fprintf(stderr, "overlapping ranges in same level %s vs. %s\n",
prev_end.DebugString().c_str(),
this_begin.DebugString().c_str());
abort();
}
}
}
#endif
}
注意一开始新版本v里面各个level的文件集合都是空的,同时除了level0以外,其它的level中的文件是有序的,必须是有序的。因此上面的代码就比较容易理解了。
它是一个三层的循环:最外层是level。无论是当前的Version current_,还是正在生成中的Version v,文件都是分层,包括help类Builder中的delete集合和新增集合,都是分层表示的。因此最外层循环是level就很自然。各个层级处理的逻辑都是一样。
就是base_这个Version(其实就是当前Version current_) 中的文件和 Builder中的added_files文件进行比较,按照顺序进入新Version v的对应level中。
其中很有意思的是MayAddFile。
void MaybeAddFile(Version* v, int level, FileMetaData* f) {
if (levels_[level].deleted_files.count(f->number) > 0) {
/*如果文件在删除列表之内,就没必要加入到新的Version v的对应层级的文件集合*/
} else {
std::vector<FileMetaData*>* files = &v->files_[level];
if (level > 0 && !files->empty()) {
/*除level0外的任何level (1~6),Version v内的对应层级的文件列表必须是有序的,不能交叉
*所以此处有判断 level >0,这是因为并不care level0 是否交叉,事实上,它几乎总是交叉的* /
assert(vset_->icmp_.Compare((*files)[files->size()-1]->largest,
f->smallest) < 0);
}
f->refs++;
files->push_back(f);
}
}
};
VersionSet::Finalize
这个部分是用来帮忙选择下一次Compaction应该从which level 开始。计算部分比较简单,基本就是看该level的文件数目或者所有文件的size 之和是否超过上限:
void VersionSet::Finalize(Version* v) {
// Precomputed best level for next compaction
int best_level = -1;
double best_score = -1;
for (int level = 0; level < config::kNumLevels-1; level++) {
double score;
if (level == 0) {
// We treat level-0 specially by bounding the number of files
// instead of number of bytes for two reasons:
//
// (1) With larger write-buffer sizes, it is nice not to do too
// many level-0 compactions.
//
// (2) The files in level-0 are merged on every read and
// therefore we wish to avoid too many files when the individual
// file size is small (perhaps because of a small write-buffer
// setting, or very high compression ratios, or lots of
// overwrites/deletions).
score = v->files_[level].size() /
static_cast<double>(config::kL0_CompactionTrigger);
} else {
// Compute the ratio of current size to size limit.
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =
static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
}
if (score > best_score) {
best_level = level;
best_score = score;
}
}
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
对于level0 而言,如果文件数目超过了config::kL0_CompactionTrigger, 就标记需要Compaction, 而该参数的值为:
// Level-0 compaction is started when we hit this many files.
static const int kL0_CompactionTrigger = 4;
对于其他 层级而言,是按照每一level的总大小来判定的。按照预想,每一个层级的文件的总大小是有上限的:
level 1 10M
level 2 100M
level 3 1000M
level 4 10000M
level 5 100000M
该层级的得分是该层级的所有文件的size总和 除以上限,然后各个层级比较自己的score,选出最急迫需要Compaction的level。 当然了Level 6就不用算了,它已经是最高的层级了。
Compaction的时候,调用Pick Compaction函数来选择compaction的层级,那时候会先按照Finalize算出来的level进行Compaction。当然了,如果从文件大小和文件个数的角度看,没有任何level需要Compaction,就按照seek次数来决定
Compaction* VersionSet::PickCompaction() {
Compaction* c;
int level;
/*注意注释,优先按照size来选择compaction的层级,选择的依据即按照Finalize函数计算的score*/
// We prefer compactions triggered by too much data in a level over
// the compactions triggered by seeks.
const bool size_compaction = (current_->compaction_score_ >= 1);
const bool seek_compaction = (current_->file_to_compact_ != NULL);
if (size_compaction) {
}
}
LogAndApply的MANIFEST部分
注意,VerisonEdit会写入到磁盘的MANIFEST部分,这一部分不在本文讲解,后面会有单独的MANIFEST的详细介绍。