前言
NSQ 是一款基于Go语言的分布式消息队列,这种消息中间件,已经有很多了,比如RabbitMQ,比如阿里开发的RocketMQ,比如Kafka,NSQ一款比较清爽的消息中间件,尽管功能上不如Kafka这么大而全,但是轻量,简单,入手简单,而且大部分情况下,无论是性能还是功能基本够用。
至于消息中间件的作用,无非是解耦,缓冲之类的,工作中遇到类似困境的自然懂,遇不到类似困境的,多说也无益。
设计原理
最新稳定版本的NSQ可以从如下地方下载:
https://nsq.io/deployment/installing.html
对于我们Linux来讲,下载如下版本并解压:
nsq-1.1.0.linux-amd64.go1.10.3.tar.gz
压缩包的内容如下:
nsq-1.1.0.linux-amd64.go1.10.3/
nsq-1.1.0.linux-amd64.go1.10.3/bin/
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsq_to_file
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsqlookupd
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsq_tail
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsqadmin
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsq_to_http
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsq_stat
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsqd
nsq-1.1.0.linux-amd64.go1.10.3/bin/to_nsq
nsq-1.1.0.linux-amd64.go1.10.3/bin/nsq_to_nsq
为了更好的理解NSQ的设计原理,甚至是消息中间件的原理,我们递进的分析 作为一个消息中间件需要做哪些事情,已经NSQ是如何做的。下面部分深度的参考了知乎大神柳树的文章 MQ(1)—— 从队列到消息中间件,我无意抄袭,只是大神讲解的确实漂亮,强烈建议对消息中间件感兴趣的筒子,阅读大神的系列文章,总是光荣属于前辈,我只是一个小学生。
NSQ 1.0,我需要一个消息队列
生产者和消费者模型,不是一个新的东西,生产者负责源源不断地生产任务,而消费者不需要管消息的来源,只需要源源不断地处理任务。既然是生产者只负责把产生任务,而消费者负责处理任务,问题就来了,任务存放到那里。这时候消息队列就横空出世了。
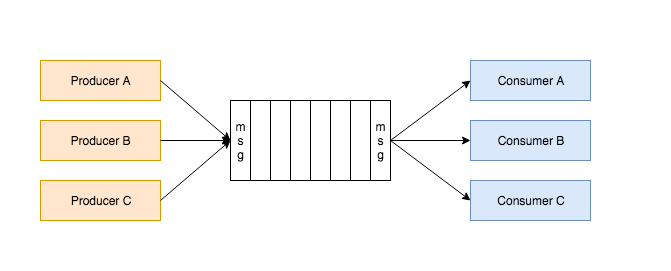
当有任务需要处理的时候,生产者进程就负责往消息队列里面Push一条消息,而消费者能够及时地知道消息队列里面有消息,从而取出任务来处理。 上面这段话有两个问题:
-
任务有很多种类型,并不是所有的生产者会生产出所有类型的任务,同样,也不是所有的消费者都关心所有类型的消息,因此引入了topic的概念。
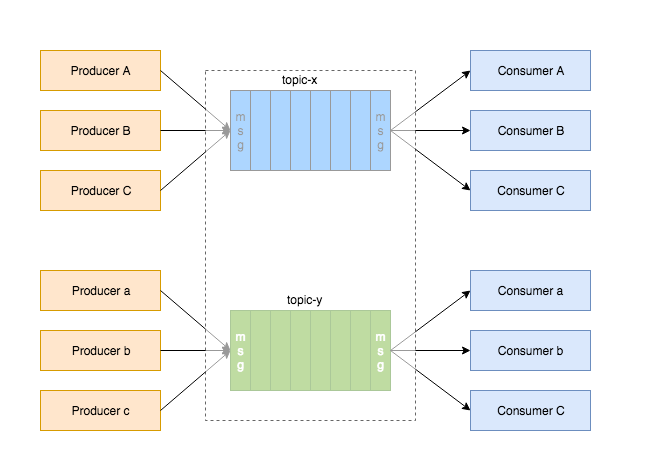
-
消费者如何知道消息队列中存在消息。这里面就有了消息队列中Push和Pull的区别。不同的消息中间件,采用的不同的方法,Kafka采用Pull,而我们介绍的NSQ采用的是Push。
有了这个队列,解决了两个问题:解耦和缓冲。如果消费者处理失败,可以给消息队列回复 requeue, NSQ会将消息重新放入队列,进行重试。
NSQ 2.0 Channel
从生产者的角度来说,放入不同topic的队列,但是从消费者的角度来说,不同的消费者,可能要关注不同的topic。 更详细点说,
- 对于一个集群来讲,收到消息A,到底由哪个消费者负责处理该消息?
- 一条消息,能不能同时发给多个消费者,多个消费者都来处理该消息
这就是消费组(Consumer Group)的概念。Kafka里面,这个概念叫消费组,而NSQ里面叫Channel。
我们还是考虑集群,对于一个集群来讲,有些任务是集群层面的任务,即,不需要每个节点都处理该任务,只需要集群中选出一个代表,负责把该任务处理即可。这事一种很common的场景。
我们用官方给的gif来解释这种场景:
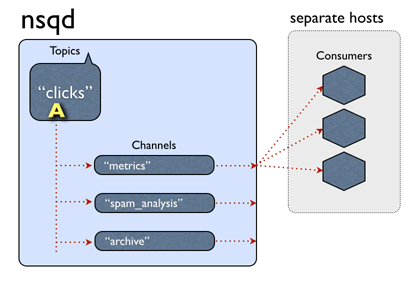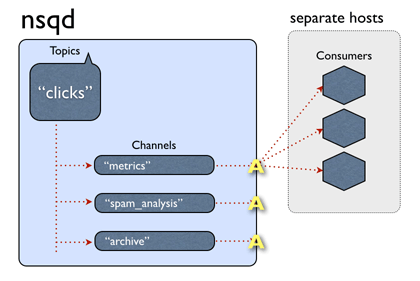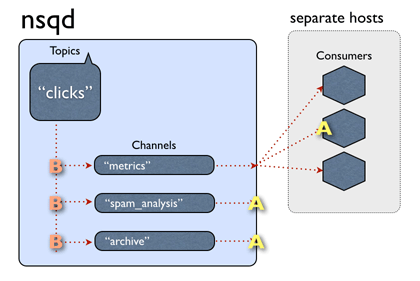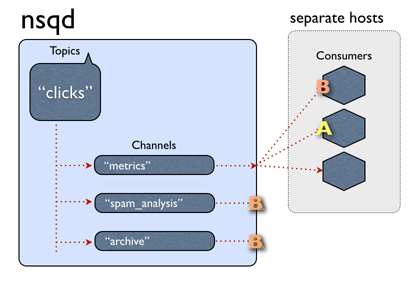
对于topic clicks, 三个消费者同时关注了该topic,同时都属于metrics channel,或者说metrics 消费组,这样,NSQ收到消息后,会给每一个channel复制一份消息,对于metrics这个消费组,有三个Consumer 实例,那么该消息会发给which Consumer?还是说同时发给三个consumer,答案是对于metrics这个channel,只会发给一个consumer,至于要发给谁,那就是负载均衡逻辑。即这次发给消费者A,下一次发给另一消费者。
对于一个集群来讲,一个消息,每个消费者(不同主机上),都要执行该怎么办?

⚠️ NSQ采用的是Push的策略,即,nsqd都会负责push消息到所有关注了该topic的channel。
NSQ 3.0 nsqlookup
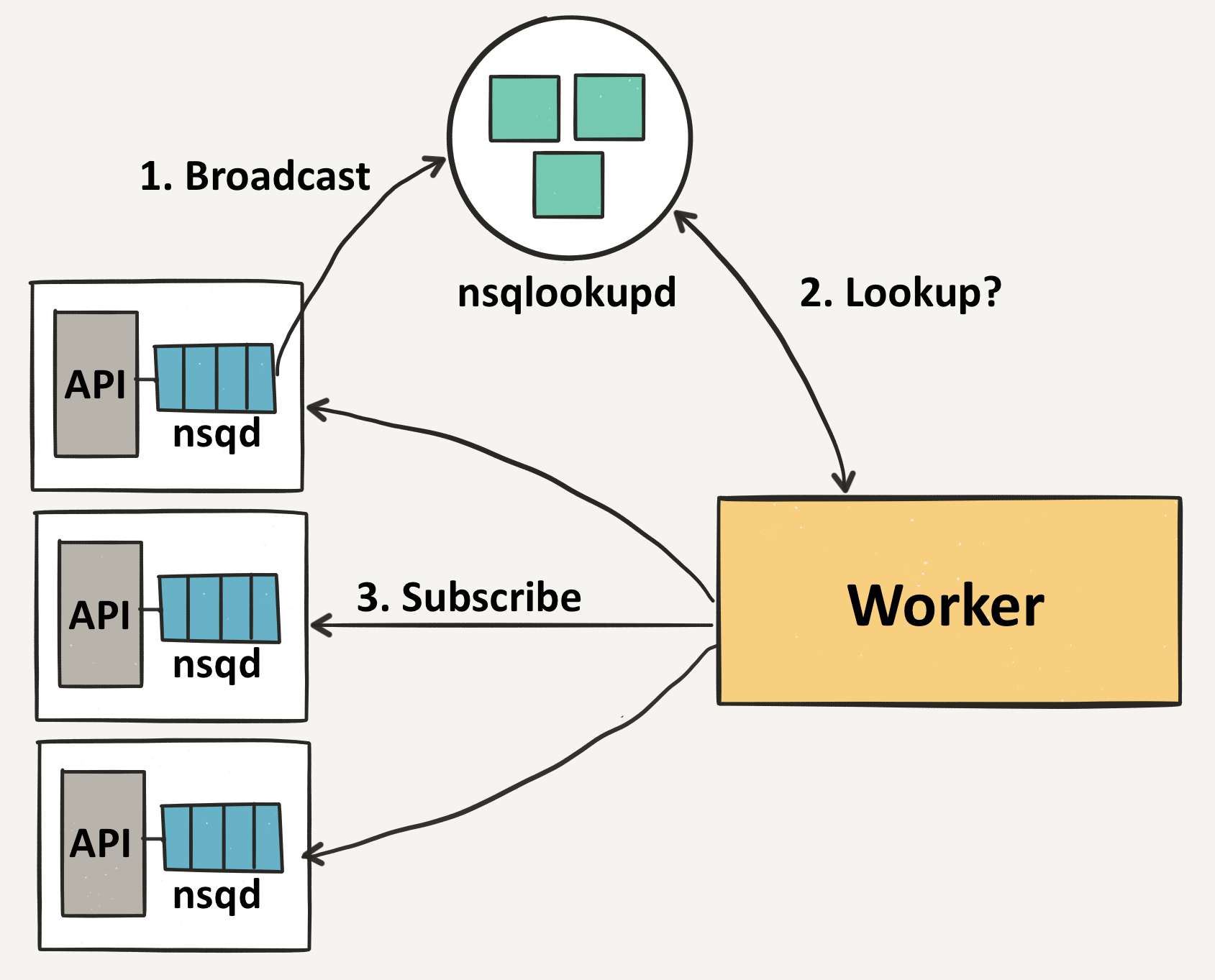
上面讲到,nsq收到生产者生产的消息之后,会将消息复制多份,推送给关注该topic的所有channel。 问题是,nsq怎么知道哪些消费者订阅了对应topic的的消息呢?
最简单的方法是写死,有个配置文件,ip是 xx.xx.xx.xx,端口为yyyy,消费者关注topic-xx,channel是zzz,这样最大的问题是不灵活。 我们需要的是一个叫做服务发现的功能。这个功能就是nsqlookup.
nsqlookup提供了一个类似etcd的kv存储,里面记录了topic下面都有哪些nsq。 nsqlookup 提供了一个 /lookup API,可以实时查询哪些 nsq下面有某个topic的消息。
curl "http://127.0.0.1:4161/lookup?topic=x_topic"
输出如下:
{
"producers" : [
{
"version" : "1.1.0",
"tcp_port" : 4150,
"broadcast_address" : "manu-Inspiron-5748",
"hostname" : "manu-Inspiron-5748",
"http_port" : 4151,
"remote_address" : "127.0.0.1:50662"
}
],
"channels" : []
}
如果我启用了消费者,关注x_topic,并且channel是 work_group_a,那么输出如下:
manu-Inspiron-5748 ~ » curl "http://127.0.0.1:4161/lookup?topic=x_topic" 2>/dev/null |json_pp
{
"producers" : [
{
"tcp_port" : 4150,
"version" : "1.1.0",
"remote_address" : "127.0.0.1:50662",
"hostname" : "manu-Inspiron-5748",
"broadcast_address" : "manu-Inspiron-5748",
"http_port" : 4151
}
],
"channels" : [
"work_group_a"
]
}
消费者就可以通过nsqlookup,获取到producer的列表,根据列表中的broadcast_address和tcp_port ,就可以拿到url 地址。 消费者就会和这些nsq逐个建立连接。当有消息到来的时候,nsq就会给和他建立联系的消费者Push 消息。
小节
我们可以总结下,NSQ的主要组件有三个:
- nsqd : 一个负责接收、排队、转发消息到客户端的守护进程
- nsqlookupd: 管理拓扑信息并提供最终一致性的服务发现 daemon
- nsqadmin: 这是一个WEB用户界面,可选。事实上也可以不启动。实时查看集群的统计数据,并执行管理任务。
开始操练
我们可以简单地使用下NSQ。
只需要将上一节中的可执行文件放入/usr/bin/目录下。
1 启动nsqlookupd
nsqlookupd
可以看到
manu-Inspiron-5748 Python/nsq » nsqlookupd 130 ↵
[nsqlookupd] 2019/03/10 22:05:55.189652 INFO: nsqlookupd v1.1.0 (built w/go1.10.3)
[nsqlookupd] 2019/03/10 22:05:55.190135 INFO: HTTP: listening on [::]:4161
[nsqlookupd] 2019/03/10 22:05:55.190155 INFO: TCP: listening on [::]:4160
我们可以看到版本信息是1.1.0,listen了4161和6160两个端口。
2 运行nsqd实例:
nsqd --lookupd-tcp-address=127.0.0.1:4160
3 启用 nsqadmin
nsqadmin --lookupd-http-address=127.0.0.1:4161
启用nsqadmin之后,我们就可以查看WEB 界面了:
接下来我们通过程序来创建topic,书写生产者和消费者的程序:
import nsq
import tornado.ioloop
import time
import random
import json
def pub_message():
message = {}
message['number'] = random.randint(1,1000)
writer.pub('x_topic', json.dumps(message), finish_pub)
def finish_pub(conn, data):
print data
writer = nsq.Writer(['127.0.0.1:4150'])
tornado.ioloop.PeriodicCallback(pub_message, 1000).start()
nsq.run()
我们创建一个x_topic的topic,并且生产者往里面每秒钟扔一个消息,消息的内容为
{'number': 409}
其中数字部分随机产生,而消费者,负责接受消息,判断数字是否是素数:
import nsq
from tornado import gen
from functools import partial
import ujson as json
def is_prime(n):
n = int(n)
if n < 2:
return False;
if n % 2 == 0:
return n == 2 # return False
k = 3
while k*k <= n:
if n % k == 0:
return False
k += 2
return True
@gen.coroutine
def write_message(topic, data, writer):
response = yield gen.Task(writer.pub, topic, data)
if isinstance(response, nsq.Error):
print "Error with Message: {}:{}".format(data, response)
else:
print "Published Message: ", data
def calculate_prime(message, writer):
message.enable_async()
data = json.loads(message.body)
prime = is_prime(data["number"])
data["prime"] = prime
if prime:
topic = "primes"
else:
topic = "non_primes"
output_message = json.dumps(data)
write_message(topic, output_message,writer)
message.finish()
if __name__ == "__main__":
writer = nsq.Writer(['127.0.0.1:4150',])
handler = partial(calculate_prime, writer=writer)
reader = nsq.Reader(
message_handler = handler,
nsqd_tcp_addresses = ['127.0.0.1:4150'],
topic = 'x_topic',
channel = 'work_group_a')
nsq.run()
我们将两个程序跑起来:
manu-Inspiron-5748 Python/nsq » python nsq_producer.py & ; python nsq_consumer.py
[1] 14833
OK
Published Message: {"prime":false,"number":669}
OK
Published Message: {"prime":false,"number":275}
OK
Published Message: {"prime":false,"number":214}
OK
Published Message: {"prime":false,"number":518}
OK
Published Message: {"prime":true,"number":739}
OK
Published Message: {"prime":false,"number":184}
OK
Published Message: {"prime":true,"number":521}
OK