前言
今天早晨QA来报,我们自己的集群环境里,124~128集群里面,128节点ceph-osd cpu load重,CPU使用率是200%~400% 之间。

我用strace 粗略地看了下,没看出什么端倪。只能上perf了。
排查
perf top
首先用perf top查看下:

CPU消耗大户是ceph-osd,其中用户态的operator« 操作罪魁祸首,其中operator«看起来是运算符重载,应该是和日志打印相关。
perf record
找到ceph-osd的进程ID 4966, 用如下指令采集下:
perf record -e cpu-clock -g -p 4966
- -g 选项是告诉perf record额外记录函数的调用关系
- -e cpu-clock 指perf record监控的指标为cpu周期
- -p 指定需要record的进程pid
我们观测的对象是ceph-osd。运行10秒中左右,ctrl+C中断掉perf record:
root@converger-128:~# perf record -e cpu-clock -g -p 4966
^C[ perf record: Woken up 7 times to write data ]
[ perf record: Captured and wrote 5.058 MB perf.data (17667 samples) ]
root@converger-128:~#
在root目录下会产生出来 perf.data文件。
## perf report
用如下指令查看dump 出来的perf.data
perf report -i perf.data
输出如下:
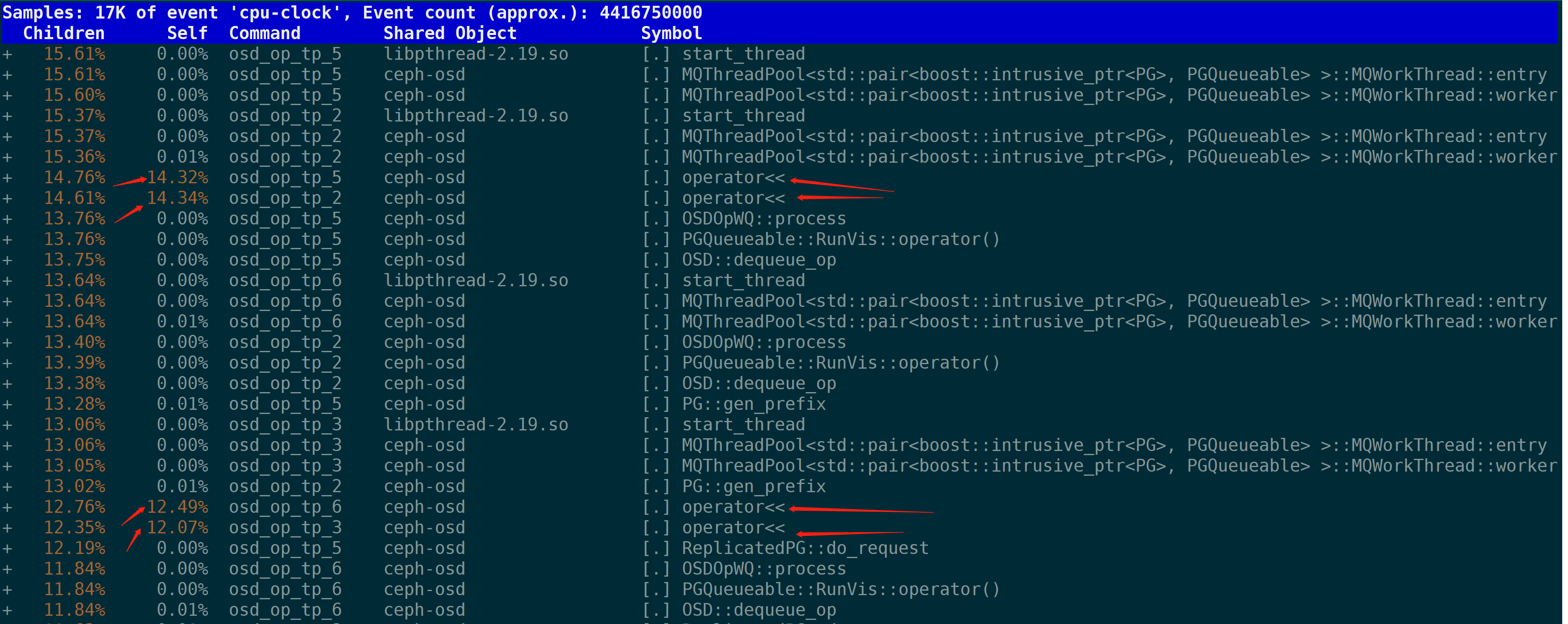
我们把operator«展开:

我们看到,大部分operator«的调用是由gen_prefix函数产生的。
分析
这部分代码代码在:
osd/ReplicatedBackend.cc
------------------------------
#define dout_subsys ceph_subsys_osd
#define DOUT_PREFIX_ARGS this
#undef dout_prefix
#define dout_prefix _prefix(_dout, this)
static ostream& _prefix(std::ostream *_dout, ReplicatedBackend *pgb) {
return *_dout << pgb->get_parent()->gen_dbg_prefix();
}
原因是128集群之前有人分析ceph-osd.4,ceph.conf 里面debug osd = 0/20, 尽管不会往磁盘里面打印日志,但是因为OSD crash的时候,需要dump 级别为20 的debug log,因此,大量的osd debug log会暂存在内存的环形buffer 中,因此,gen_prefix函数被大量的调用,消耗了太多的CPU资源。
实时修改ceph-osd debug_osd的级别,并修改ceph.conf 永久生效,发现ceph-osd CPU使用正常。
root@converger-128:/etc/ceph# ceph daemon osd.5 config set debug_osd 0
{
"success": ""
}
root@converger-128:/etc/ceph# ceph daemon osd.4 config set debug_osd 0
{
"success": ""
}
