前言
EXT4文件系统的inode是非常多的,按照Inodes Per Block Group = 4096而言,1T空间能提供出32M个inode左右,当我们创建一个目录,或者创建一个文件时,EXT4会怎么选择inode呢?
在2002年发表的The Orlov block allocator一文中提到,影响文件系统性能的因素有很多,但是文件在磁盘上的分布非常关键。有一个总体的原则:相关的数据寻处位置相近。因为位置相近甚至连续,那么花在磁盘寻道上的时间机会少,从而提高性能。
但是实际情况下,还有一种特殊情况,对于文件系统的顶层目录,尽量要伸展开,分离开,否则顶层目录挤在一起,底层目录更具局部性原理也挤在一起,最终就会导致文件系统,从远到近地线性展开,很多文件与其父目录的位置隔得很远,从而损坏性能。
因此,一个很重要的原则是,顶层目录尽量在整个存储空间铺开,而目录树深处的目录相关的目录尽量靠近。这个原则是不难理解的。Linux采用了一种叫做Orlov allocator的算法来负责选择inode的位置。该算法时由 Grigory Orlov[提出],在EXT2和EXT3 就开始使用该算法,但是EXT4由于支持flex_bg,所以算法上也有了一点点变化或者变异
内核实现
对于EXT4文件系统,无论是创建文件(create),还是创建目录,还是创建软链接,都会牵扯到inode分配(如图所示)。茫茫无数inode,到底选用那一个?
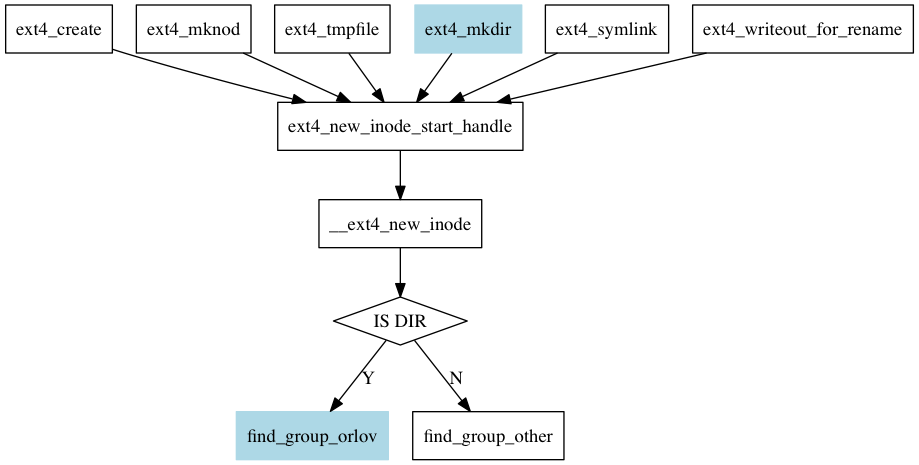
这个__ext4_new_inode是EXT4非常重要的一个函数,它的内容有400行之多,占据了fs/ext4/ialloc.c的四分之一以上的篇幅。本文重点介绍选择inode分配给新的文件或目录的这个流程。
其实我们不难想到,由于EXT4支持flex block group这种战斗小组,选择inode可以分解成3步
- which flex block group
- which block group
- which inode
这些步骤中,第一步决定了目录是分散还是聚集在一起。文件和目录的规则是不同的:
if (S_ISDIR(mode))
ret2 = find_group_orlov(sb, dir, &group, mode, qstr);
else
ret2 = find_group_other(sb, dir, &group, mode);
从上面代码也不难看出,对于目录和文件,选择group的规则是不同的。对于目录而言,使用find_group_orlov函数来寻找合适的group,该函数使用了前面提到的orlov allocator算法,而对于文件,软链接等则 使用了find_group_other来寻找合适的group。
目录的inode分配
首先介绍目录文件的inode分配,目录inode分配,调用的是find_group_orlov函数。
static int find_group_orlov(struct super_block *sb, struct inode *parent,
ext4_group_t *group, umode_t mode,
const struct qstr *qstr)
{
ext4_group_t parent_group = EXT4_I(parent)->i_block_group;
struct ext4_sb_info *sbi = EXT4_SB(sb);
/*获取块组的个数,存放到real_ngroups变量中*/
ext4_group_t real_ngroups = ext4_get_groups_count(sb);
int inodes_per_group = EXT4_INODES_PER_GROUP(sb);
unsigned int freei, avefreei, grp_free;
ext4_fsblk_t freeb, avefreec;
unsigned int ndirs;
int max_dirs, min_inodes;
ext4_grpblk_t min_clusters;
ext4_group_t i, grp, g, ngroups;
struct ext4_group_desc *desc;
struct orlov_stats stats;
int flex_size = ext4_flex_bg_size(sbi);
struct dx_hash_info hinfo;
ngroups = real_ngroups;
/*如果文件系统打开了flex_bg选项,就以逻辑块组为单位分配*/
if (flex_size > 1) {
ngroups = (real_ngroups + flex_size - 1) >>
sbi->s_log_groups_per_flex;
parent_group >>= sbi->s_log_groups_per_flex;
}
freei = percpu_counter_read_positive(&sbi->s_freeinodes_counter);
avefreei = freei / ngroups;
freeb = EXT4_C2B(sbi,
percpu_counter_read_positive(&sbi->s_freeclusters_counter));
avefreec = freeb;
do_div(avefreec, ngroups);
ndirs = percpu_counter_read_positive(&sbi->s_dirs_counter);
if (S_ISDIR(mode) &&
((parent == d_inode(sb->s_root)) ||
(ext4_test_inode_flag(parent, EXT4_INODE_TOPDIR)))) {
int best_ndir = inodes_per_group;
int ret = -1;
if (qstr) {
hinfo.hash_version = DX_HASH_HALF_MD4;
hinfo.seed = sbi->s_hash_seed;
ext4fs_dirhash(qstr->name, qstr->len, &hinfo);
grp = hinfo.hash;
} else
grp = prandom_u32();
parent_group = (unsigned)grp % ngroups;
for (i = 0; i < ngroups; i++) {
g = (parent_group + i) % ngroups;
get_orlov_stats(sb, g, flex_size, &stats);
if (!stats.free_inodes)
continue;
if (stats.used_dirs >= best_ndir)
continue;
if (stats.free_inodes < avefreei)
continue;
if (stats.free_clusters < avefreec)
continue;
grp = g;
ret = 0;
best_ndir = stats.used_dirs;
}
if (ret)
goto fallback;
found_flex_bg:
if (flex_size == 1) {
*group = grp;
return 0;
}
/*
* We pack inodes at the beginning of the flexgroup's
* inode tables. Block allocation decisions will do
* something similar, although regular files will
* start at 2nd block group of the flexgroup. See
* ext4_ext_find_goal() and ext4_find_near().
*/
grp *= flex_size;
for (i = 0; i < flex_size; i++) {
if (grp+i >= real_ngroups)
break;
desc = ext4_get_group_desc(sb, grp+i, NULL);
if (desc && ext4_free_inodes_count(sb, desc)) {
*group = grp+i;
return 0;
}
}
goto fallback;
}
max_dirs = ndirs / ngroups + inodes_per_group / 16;
min_inodes = avefreei - inodes_per_group*flex_size / 4;
if (min_inodes < 1)
min_inodes = 1;
min_clusters = avefreec - EXT4_CLUSTERS_PER_GROUP(sb)*flex_size / 4;
/*
* Start looking in the flex group where we last allocated an
* inode for this parent directory
*/
if (EXT4_I(parent)->i_last_alloc_group != ~0) {
parent_group = EXT4_I(parent)->i_last_alloc_group;
if (flex_size > 1)
parent_group >>= sbi->s_log_groups_per_flex;
}
for (i = 0; i < ngroups; i++) {
grp = (parent_group + i) % ngroups;
get_orlov_stats(sb, grp, flex_size, &stats);
if (stats.used_dirs >= max_dirs)
continue;
if (stats.free_inodes < min_inodes)
continue;
if (stats.free_clusters < min_clusters)
continue;
goto found_flex_bg;
}
fallback:
ngroups = real_ngroups;
avefreei = freei / ngroups;
fallback_retry:
parent_group = EXT4_I(parent)->i_block_group;
for (i = 0; i < ngroups; i++) {
grp = (parent_group + i) % ngroups;
desc = ext4_get_group_desc(sb, grp, NULL);
if (desc) {
grp_free = ext4_free_inodes_count(sb, desc);
if (grp_free && grp_free >= avefreei) {
*group = grp;
return 0;
}
}
}
if (avefreei) {
/*
* The free-inodes counter is approximate, and for really small
* filesystems the above test can fail to find any blockgroups
*/
avefreei = 0;
goto fallback_retry;
}
return -1;
}
这么一大段代码,概括来讲可以描述为以下情况
- 采用spread out 策略让目录散开
- 根据局部性原理,让兄弟目录,父子目录尽可能的靠近
当然这两种搜索都可能失败,那么就忘记战斗小组,各个块组地毯式搜索。
OK,我们开始进入代码细节。首先如果文件系统使用了flex_bg就以战斗小组为单位分配,率先需要确定inode所在的战斗小组,即ngroup的值为文件系统中包含的所有逻辑块组的个数,当然了,如果并没有采用flex_bg,就退化成普通的块组。
接下来,对文件系统的总体使用情况做一个评估,我们如果是伸展开的策略,那么我们希望我们的inode分布在一个试用情况低于平均水平的逻辑块组。这样各个逻辑块组使用才能均衡。
freei = percpu_counter_read_positive(&sbi->s_freeinodes_counter);
avefreei = freei / ngroups;
freeb = EXT4_C2B(sbi,
percpu_counter_read_positive(&sbi->s_freeclusters_counter));
avefreec = freeb;
do_div(avefreec, ngroups);
ndirs = percpu_counter_read_positive(&sbi->s_dirs_counter);
接下来的情况是何时采用伸展开的策略,何时采用靠近的策略。
if (S_ISDIR(mode) &&
((parent == d_inode(sb->s_root)) ||
(ext4_test_inode_flag(parent, EXT4_INODE_TOPDIR)))) {
int best_ndir = inodes_per_group;
int ret = -1;
if (qstr) {
hinfo.hash_version = DX_HASH_HALF_MD4;
hinfo.seed = sbi->s_hash_seed;
ext4fs_dirhash(qstr->name, qstr->len, &hinfo);
grp = hinfo.hash;
} else
grp = prandom_u32();
parent_group = (unsigned)grp % ngroups;
for (i = 0; i < ngroups; i++) {
g = (parent_group + i) % ngroups;
get_orlov_stats(sb, g, flex_size, &stats);
if (!stats.free_inodes)
continue;
if (stats.used_dirs >= best_ndir)
continue;
if (stats.free_inodes < avefreei)
continue;
if (stats.free_clusters < avefreec)
continue;
grp = g;
ret = 0;
best_ndir = stats.used_dirs;
}
if (ret)
goto fallback;
found_flex_bg:
if (flex_size == 1) {
*group = grp;
return 0;
}
首先inode必须为目录文件的inode,除此外,两个条件满足一个,都可以
- 文件系统的顶层目录
- 正在创建的目录的父目录设置了 EXT4_INODE_TOPDIR标志位
第一个条件非常好理解,第二个条件是个什么鬼? 我们不妨以/home目录为例,来理解这个EXT4_INODE_TOPDIR. 我们知道,默认情况下,各个用户的家目录位于/home/下,我们可以想象/home/下可能存在以下的目录:
- bean
- chandler
- bruce
- tony
- henry
事实上,每个子目录都对应一个用户,这些用户的文件可能并不相关,bean用户登陆之后,一般访问的是/home/bean下的文件,极少会访问/home/tony下的文件,因此,从局部性原理上讲,这下目录对应的inode 更应该散开而不是聚集在一起。而且/home/下的任何一个目录,可能都是一个消耗磁盘空间很多,文件数非常多的节点,从这个角度看,这些目录对应的inode应该尽可能分散在整个存储空间上。但是很不幸,如果/home目录不是某个文件系统的根,即/home不是挂载点,默认策略并不是尽可能的散开。
有没有办法补救,告诉文件系统,这个/home下的子目录采取的策略应该是spread out,而不是聚集在一起。答案就是这个EXT_INODE_TOPDIR标志位。我们可以给/home目录添加上该标志位,后续在/home/下新建目录,EXT4会采取spread out的策略。
那么如何给/home目录添加EXT4_INODE_TOPDIR的标志位呢?
chattr +T /home
接下来的for循环,遍历所有的逻辑块组,来寻找最合适的,所谓最合适的,不过是目录数要少,已经分配出去的inode也低于平均值。注意此处采用的并不是first-fit的策略,而是采用的是寻找最优的逻辑块组。即目录数最小的那个逻辑块组。
从for (i = 0; i < ngroups; i++) {这个for循环以可以看出,flex_bg是一种优化,如果没有flex_bg,那么EXT4的layout就过于扁平化,如果没有flex_bg,128MB一个块组,1T的文件系统就有8192个块组,现在4T盘到处都是,8T盘也出现的情况下,块组个数就会更多。如果没有flex_bg,那么搜索的代价就有点大。
如果没有设置flex_bg,此时逻辑块组和块组是一个意思,因此就会可以返回了。 如果设置了flex_bg,上述步骤仅仅是找到了逻辑块组,并未找到块组。寻找合适块组就比较简单了,就依次询问,只要存在free inode,就选择该块组,即first-fit的策略。
上面这一大段,讨论的都是spread out策略的情况,下面代码讨论的是尽可能靠近父目录的策略。
max_dirs = ndirs / ngroups + inodes_per_group / 16;
min_inodes = avefreei - inodes_per_group*flex_size / 4;
if (min_inodes < 1)
min_inodes = 1;
min_clusters = avefreec - EXT4_CLUSTERS_PER_GROUP(sb)*flex_size / 4;
/*
* Start looking in the flex group where we last allocated an
* inode for this parent directory
*/
if (EXT4_I(parent)->i_last_alloc_group != ~0) {
parent_group = EXT4_I(parent)->i_last_alloc_group;
if (flex_size > 1)
parent_group >>= sbi->s_log_groups_per_flex;
}
for (i = 0; i < ngroups; i++) {
grp = (parent_group + i) % ngroups;
get_orlov_stats(sb, grp, flex_size, &stats);
if (stats.used_dirs >= max_dirs)
continue;
if (stats.free_inodes < min_inodes)
continue;
if (stats.free_clusters < min_clusters)
continue;
goto found_flex_bg;
}
各个逻辑块组尽可能平衡的目标明显放松了,
max_dirs = ndirs / ngroups + inodes_per_group / 16;
min_inodes = avefreei - inodes_per_group*flex_size / 4;
即只要不是太不平衡,就一律选择父目录所在的逻辑块,更确切的说法是,父目录上次分配inode所在的逻辑块组,即记录在 EXT4_I(parent)->i_last_alloc_group;中的值。
本次选择的group会记录在父目录inode的i_last_alloc_group中,当在同一个父目录下创建目录是,i_last_alloc_group就是搜索的起点,因为尽可能均衡的条件放送了,只要不太过分,再次创建的目录很可能和上一次创建的目录在同一个逻辑块组中。
if (S_ISDIR(mode))
ret2 = find_group_orlov(sb, dir, &group, mode, qstr);
else
ret2 = find_group_other(sb, dir, &group, mode);
got_group:
EXT4_I(dir)->i_last_alloc_group = group;
找到逻辑块组之后,同样是采用first-fit的策略进行选择块组。
无论是采用spread-out策略还是聚集的策略,都可能失败,如果失败,就一律化整为零,不再以逻辑块组为单位搜索了,而是以细粒度的块组为单位搜索。第一次目标是低于平均值即可,如果这个目标也达不到,只要有free inode即可。
fallback:
ngroups = real_ngroups;
avefreei = freei / ngroups;
fallback_retry:
parent_group = EXT4_I(parent)->i_block_group;
for (i = 0; i < ngroups; i++) {
grp = (parent_group + i) % ngroups;
desc = ext4_get_group_desc(sb, grp, NULL);
if (desc) {
grp_free = ext4_free_inodes_count(sb, desc);
if (grp_free && grp_free >= avefreei) {
*group = grp;
return 0;
}
}
}
if (avefreei) {
/*
* The free-inodes counter is approximate, and for really small
* filesystems the above test can fail to find any blockgroups
*/
avefreei = 0;
goto fallback_retry;
}
其它文件的inode分配
在文件系统中,目录文件有点特殊,它是文件系统的骨架,或者是一颗树的枝干,而普通文件是一颗树的树叶。因此目录文件分配inode,单拎出来,由专门的函数处理。其它文件inode分配由find_group_other函数实现.
在这个函数中,我们主要讲enable flex_bg feature时采用的策略。原因是随着硬盘空间越来越大,flex_bg几乎总是enable的。
static int find_group_other(struct super_block *sb, struct inode *parent,
ext4_group_t *group, umode_t mode)
{
ext4_group_t parent_group = EXT4_I(parent)->i_block_group;
ext4_group_t i, last, ngroups = ext4_get_groups_count(sb);
struct ext4_group_desc *desc;
int flex_size = ext4_flex_bg_size(EXT4_SB(sb));
/*
* Try to place the inode is the same flex group as its
* parent. If we can't find space, use the Orlov algorithm to
* find another flex group, and store that information in the
* parent directory's inode information so that use that flex
* group for future allocations.
*/
if (flex_size > 1) {
int retry = 0;
try_again:
parent_group &= ~(flex_size-1);
last = parent_group + flex_size;
if (last > ngroups)
last = ngroups;
for (i = parent_group; i < last; i++) {
desc = ext4_get_group_desc(sb, i, NULL);
if (desc && ext4_free_inodes_count(sb, desc)) {
*group = i;
return 0;
}
}
if (!retry && EXT4_I(parent)->i_last_alloc_group != ~0) {
retry = 1;
parent_group = EXT4_I(parent)->i_last_alloc_group;
goto try_again;
}
/*
* If this didn't work, use the Orlov search algorithm
* to find a new flex group; we pass in the mode to
* avoid the topdir algorithms.
*/
*group = parent_group + flex_size;
if (*group > ngroups)
*group = 0;
return find_group_orlov(sb, parent, group, mode, NULL);
}
/*
* Try to place the inode in its parent directory
*/
*group = parent_group;
desc = ext4_get_group_desc(sb, *group, NULL);
if (desc && ext4_free_inodes_count(sb, desc) &&
ext4_free_group_clusters(sb, desc))
return 0;
/*
* We're going to place this inode in a different blockgroup from its
* parent. We want to cause files in a common directory to all land in
* the same blockgroup. But we want files which are in a different
* directory which shares a blockgroup with our parent to land in a
* different blockgroup.
*
* So add our directory's i_ino into the starting point for the hash.
*/
*group = (*group + parent->i_ino) % ngroups;
/*
* Use a quadratic hash to find a group with a free inode and some free
* blocks.
*/
for (i = 1; i < ngroups; i <<= 1) {
*group += i;
if (*group >= ngroups)
*group -= ngroups;
desc = ext4_get_group_desc(sb, *group, NULL);
if (desc && ext4_free_inodes_count(sb, desc) &&
ext4_free_group_clusters(sb, desc))
return 0;
}
/*
* That failed: try linear search for a free inode, even if that group
* has no free blocks.
*/
*group = parent_group;
for (i = 0; i < ngroups; i++) {
if (++*group >= ngroups)
*group = 0;
desc = ext4_get_group_desc(sb, *group, NULL);
if (desc && ext4_free_inodes_count(sb, desc))
return 0;
}
return -1;
}
主旋律是很明确的,就是靠近。注释信息说的很清楚了,即首先在父目录的逻辑块组(flex block groups)中寻找有没有可用的inode:
parent_group &= ~(flex_size-1);
last = parent_group + flex_size;
if (last > ngroups)
last = ngroups;
for (i = parent_group; i < last; i++) {
desc = ext4_get_group_desc(sb, i, NULL);
if (desc && ext4_free_inodes_count(sb, desc)) {
*group = i;
return 0;
}
}
如果没有找到,去父目录上次分配inode的逻辑块组(flex block groups),在此寻找有没有可以用的inode。
if (!retry && EXT4_I(parent)->i_last_alloc_group != ~0) {
retry = 1;
parent_group = EXT4_I(parent)->i_last_alloc_group;
goto try_again;
}
如果还没有,那就只能用 find_group_orlov函数来搜索。注意搜索的时候,会将mode 传入,因为S_ISDIR(mode)总是false,因此,为文件搜索inode的时候,并不会采用展开的策略,还是采用尽可能靠近的策略。
*group = parent_group + flex_size;
if (*group > ngroups)
*group = 0;
return find_group_orlov(sb, parent, group, mode, NULL);