前言
文件系统之所以存在,是为了通过对存储空间进行组织,更有序的存放数据,而有序是为了高效地定位数据存放的位置,以及更有效率地写入和读取客户的数据。因此任何文件系统,都会有元数据信息。这些元数据信息或者是描述的文件的一些属性(owner,文件长度,访问权限,修改时间,以及扩展属性),或者是存放数据的位置相关信息以方便更快地定位数据的位置,或者记录空间的分配情况,当有新文件创建更快地分配inode,当有新数据写入的时候,更快地指定存储位置。
EXT4 disk layout
EXT4 是由多个块组(block group)组成的,每个块组的layout如下图所示:
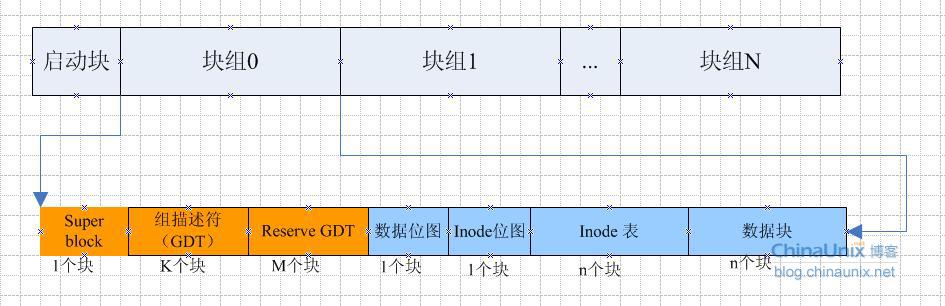
EXT4上承EXT3和EXT2,将大量的存储空间分成块组(Block Group),从上图看出,一个块组用1个block来存放inode的位图和block的位图,这就决定了块组的最大大小。以默认的4K为例,4KB=32K bit,因此,最多也就能记录32K个块的分配情况。因此一个块组是32K*4KB=128MB。
一般而言,一个block的size总是4KB,很少需要调整,但是如果缺失需要调整block的大小,那么可以通过mkfs的 -b选项来指定block的大小。但是需要注意到,一旦block-ize发生了变化,那么块组的大小也就发生了变化。这个影响是两方面的,不仅仅是块大小变化了,而且因为一个块的bit发生了变化,由于位图,直接影响了块组容纳的块的个数。后面我们都以4096字节作为block-size
对于EXT4文件系统而言,上图中的超级快并非每一个块组都要存在,但也不是只有一个super block块。如果只有一个superblock 块组,那么一旦损坏,文件系统也就不能用了,如果每个块组都要分配一个block,空间上有点浪费。因此mkfs的时候,有一个默认的选项sparse_super。
root@node-3:/data/osd.4# cat /etc/mke2fs.conf
[defaults]
base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
default_mntopts = acl,user_xattr
enable_periodic_fsck = 0
blocksize = 4096
inode_size = 256
inode_ratio = 16384
[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
auto_64-bit_support = 1
inode_size = 256
}
ext4dev = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
inode_size = 256
options = test_fs=1
}
该选项的含义是,将superblock 稀疏地分散在文件系统中:既不是每个块组都有superblock,也不是一共只有一个superblock。那么哪些块组会有superblock呢?如果在用了sparse_super选项(默认选项),超级快位于满足一下条件的块组上
- 块组0
- 块组id为3 或5 或7的幂(注意,块组#1是3的0次幂,因此也有backup superblock)。
从下面输出中不难看出,
#1 32768 = (32876)*3^0
#3 98304 = (32768) *3^1
#5 163840 = (32768) *5^1
#7 229376 = (32768) *7^1
#9 294912 = (32768) *3^2
#25
...
root@node-1:~# dumpe2fs /dev/sdb2|grep super
dumpe2fs 1.42 (29-Nov-2011)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Primary superblock at 0, Group descriptors at 1-464
Backup superblock at 32768, Group descriptors at 32769-33232
Backup superblock at 98304, Group descriptors at 98305-98768
Backup superblock at 163840, Group descriptors at 163841-164304
Backup superblock at 229376, Group descriptors at 229377-229840
Backup superblock at 294912, Group descriptors at 294913-295376
Backup superblock at 819200, Group descriptors at 819201-819664
Backup superblock at 884736, Group descriptors at 884737-885200
Backup superblock at 1605632, Group descriptors at 1605633-1606096
Backup superblock at 2654208, Group descriptors at 2654209-2654672
Backup superblock at 4096000, Group descriptors at 4096001-4096464
Backup superblock at 7962624, Group descriptors at 7962625-7963088
Backup superblock at 11239424, Group descriptors at 11239425-11239888
Backup superblock at 20480000, Group descriptors at 20480001-20480464
Backup superblock at 23887872, Group descriptors at 23887873-23888336
Backup superblock at 71663616, Group descriptors at 71663617-71664080
Backup superblock at 78675968, Group descriptors at 78675969-78676432
Backup superblock at 102400000, Group descriptors at 102400001-102400464
Backup superblock at 214990848, Group descriptors at 214990849-214991312
Backup superblock at 512000000, Group descriptors at 512000001-512000464
Backup superblock at 550731776, Group descriptors at 550731777-550732240
Backup superblock at 644972544, Group descriptors at 644972545-644973008
Backup superblock at 1934917632, Group descriptors at 1934917633-1934918096
除了sparse_super选项,EXT4支持一种新的选项 sparse_super2来备份super block,我们不妨看下e2fsprogs该commit的comment:
commit 65c6c3e06f72e76ddb69222b3be1713d870eb782
Author: Theodore Ts'o <tytso@mit.edu>
Date: Sat Jan 11 22:11:42 2014 -0500
Add support for new compat feature "sparse_super2"
In practice, it is **extremely** rare for users to try to use more
than the first backup superblock located at the beginning of block
group #1. (i.e., at block number 32768 for file systems with a 4k
block size). This new compat feature restricts the backup superblock
to block group #1 and the last block group in the file system.
Aside from reducing the overhead of the file system by a small number
of blocks, by eliminating the rest of the backup superblocks, it
allows us to have a much more flexible metadata layout. For example,
we can force all of the allocation bitmaps and inode table blocks to
the beginning of the disk, which allows most of the disk to be
exclusively used for contiguous data blocks.
This simplifies taking advantage of certain HDD specific features,
such as Shingled Magnetic Recording (aka Shingled Drives), and the
TCG's OPAL Storage Specification where having a simple mapping between
LBA block ranges and the data blocks used by the file system can make
life much simpler.
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
这个comment的大意是,纵然Primary superblock损坏了,那么位于block group #1处的super block 也足以恢复,很少有情况需要用到位于其它位置的备用super block。因此,只提供了2个超级快的备用super block,分别位于block group #1和最后一个block group。引入这种方案,好处不仅仅是节省了磁盘空间,更重要的是使元数据分布的更灵活,比如支持后面提到的packed_meta_blocks扩展选项,将所有元数据固定在存储空间的开始位置。
另外一个比较有意思的话题是inode table的长度。对于EXT4的默认情况,一个inode的大小是256字节,inode是EXT4最重要的元数据信息。
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
union {
struct {
__le32 l_i_version;
} linux1;
struct {
__u32 h_i_translator;
} hurd1;
struct {
__u32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high;
__le32 i_obso_faddr; /* Obsoleted fragment address */
union {
struct {
__le16 l_i_blocks_high; /* were l_i_reserved1 */
__le16 l_i_file_acl_high;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__le16 l_i_checksum_lo;/* crc32c(uuid+inum+inode) LE */
__le16 l_i_reserved;
} linux2;
struct {
__le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
__u16 h_i_mode_high;
__u16 h_i_uid_high;
__u16 h_i_gid_high;
__u32 h_i_author;
} hurd2;
struct {
__le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
__le16 m_i_file_acl_high;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
__le16 i_extra_isize;
__le16 i_checksum_hi; /* crc32c(uuid+inum+inode) BE */
__le32 i_ctime_extra; /* extra Change time (nsec << 2 | epoch) */
__le32 i_mtime_extra; /* extra Modification time(nsec << 2 | epoch) */
__le32 i_atime_extra; /* extra Access time (nsec << 2 | epoch) */
__le32 i_crtime; /* File Creation time */
__le32 i_crtime_extra; /* extra FileCreationtime (nsec << 2 | epoch) */
__le32 i_version_hi; /* high 32 bits for 64-bit version */
__le32 i_projid; /* Project ID */
};
尽管inode bitmap是32K个bit,但是并不意味着每个块组一定要分配32K个inode,因为128M的空间里,存放32K个inode太浪费了,只有几乎所有的文件的大小都小于4K的情况下,才会需要这么多的inode。因此,一个块组预先分配多少个inode,反应的是文件系统对系统内文件平均大小的预期。如果文件系统内存放的文件几乎全是1G以上的大文件,那么分配太多的inode,会浪费宝贵的存储空间。
root@node-1:~# tune2fs -l /dev/sdb2 |grep Inode
Inode count: 243073024
Inodes per group: 4096
Inode blocks per group: 256
Inode size: 256
从上面的内容不难看出,每个Inode的大小为256字节,一个块组有4096个inode,所有的inode消耗了256个block。这个情况表明,该文件系统一个块组128M的空间,预期文件个数不会超过4096个,即创建文件系统的人认为,文件系统的文件的平均大小不低于32K。如果该文件系统中所有的文件均是1K或者几KB的小文件,就会出现,磁盘空间还有大量的剩余,但是inode已经分配光的情况。这种情况下,再次创建文件就会有No Space之类的报错。本周,我来看到一个这种错误,同事问我df -h明明有大量的空间,为何报这种错误。如何发现文件系统Inode的使用情况呢:
root@node-1:~# df -ih
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda3 5.9M 2.4M 3.6M 40% /
udev 7.9M 656 7.9M 1% /dev
tmpfs 7.9M 669 7.9M 1% /run
none 7.9M 12 7.9M 1% /run/lock
none 7.9M 9 7.9M 1% /run/shm
/dev/sdb2 232M 5.9M 227M 3% /data/osd.0
/dev/sdc2 232M 6.0M 226M 3% /data/osd.1
EXT4文件系统mkfs提供了一个 -i的选项,用来调节每个块组inode的个数。该参数的含义是 bytes-per-inode,即格式化的时候,提醒下系统,你认为你该文件系统每个文件的平均大小。使用该值的时候,注意该值不要比block-size小,如果比block-size还要小,意味着很多inode根本没有机会分配出去,纯属浪费。
下面以一个100G的盘做实验,看下-i选项对inodes per group的影响:
dd if=/dev/zero of=bean bs=1G count=100
losetup /dev/loop0 bean
从源码上看,该值不得小于1024(即最小的block-size),但是不能大于67108864(即64M),这部分逻辑位于e2fsprogs源码中:
/*
* Macro-instructions used to manage several block sizes
*/
#define EXT2_MIN_BLOCK_LOG_SIZE 10 /* 1024 */
#define EXT2_MAX_BLOCK_LOG_SIZE 16 /* 65536 */
#define EXT2_MIN_BLOCK_SIZE (1 << EXT2_MIN_BLOCK_LOG_SIZE)
#define EXT2_MAX_BLOCK_SIZE (1 << EXT2_MAX_BLOCK_LOG_SIZE)
case 'i':
inode_ratio = parse_num_blocks(optarg, -1);
if (inode_ratio < EXT2_MIN_BLOCK_SIZE ||
inode_ratio > EXT2_MAX_BLOCK_SIZE * 1024) {
com_err(program_name, 0,
_("invalid inode ratio %s (min %d/max %d)"),
optarg, EXT2_MIN_BLOCK_SIZE,
EXT2_MAX_BLOCK_SIZE * 1024);
exit(1);
}
root@node-1:/data/osd.0# mkfs.ext4 -i 1024 /dev/loop0
mke2fs 1.42 (29-Nov-2011)
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
104857600 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1099956224
3200 block groups
8192 blocks per group, 8192 fragments per group
32768 inodes per group
Superblock backups stored on blocks:
8192, 24576, 40960, 57344, 73728, 204800, 221184, 401408, 663552,
1024000, 1990656, 2809856, 5120000, 5971968, 17915904, 19668992,
25600000
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
root@node-1:/data/osd.0# tune2fs -l /dev/loop0 |grep Inode
Inode count: 104857600
Inodes per group: 32768
Inode blocks per group: 2048
Inode size: 256
尽管指定了bytes-per-inode 为1024,按照计算,inode per group = 128MB/1024 = 128K个inode;但实际上,并没有那么多,而只有32768即32K个inode,原因在于block-size 是4K,并非1024,因此,考虑到每个文件至少消耗1个4KB的block存放数据,创建超过32K个inode无实际意义。
root@node-1:/data/osd.0# mkfs.ext4 -i 67108864 /dev/loop0
mke2fs 1.42 (29-Nov-2011)
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
12800 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
800 block groups
32768 blocks per group, 32768 fragments per group
16 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
root@node-1:/data/osd.0# tune2fs -l /dev/loop0 |grep Inode
Inode count: 12800
Inodes per group: 16
Inode blocks per group: 1
Inode size: 256
尽管指定了bytes-per-inode是64M,但是inode per group 也并不是128MB/64MB = 2个,而是16个,这是因为inode 最小也要消耗1个4KB的block,该block能放下16个inode(因为每个inode大小为256字节)。
另外一个和inode个数相关的参数是-N,这个用来指定这个文件系统inode的个数。系统并非严格按照该值来推算,因为每个块组至少有16的整数倍给inode。系统推算出,满足该inode的最小 inode blocks per group,然后得到真实的inode个数
root@node-1:/data/osd.0# mkfs.ext4 -N 80000 /dev/loop0
mke2fs 1.42 (29-Nov-2011)
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
89600 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
800 block groups
32768 blocks per group, 32768 fragments per group
112 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
root@node-1:/data/osd.0# tune2fs -l /dev/loop0 |grep Inode
Inode count: 89600
Inodes per group: 112
Inode blocks per group: 7
Inode size: 256
flex_bg
上面讲述的是经典的EXT4布局。从EXT4开始,内核引入了flexible block groups的概念。这个弹性块组群是个什么概念呢。就是打破128MB一个块组,块组之间泾渭分明的界限,让多个块组形成一个战斗小组。
用更确切的话说就是多个块组,将block bitmap聚合在一起,inode bitmap聚合在一起,同时inode table 也聚合在一起,形成一个逻辑块组。这些信息连续的好处是,如果客户连续读,就减少因为inode或bitmap不连续而不得不寻道带来的额外effort。
该格式化选项,默认是开着的,执行dubugfs -R stats /dev/loop0可以看到如下的参数:
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
也就说16个块组组成了一个战斗小组逻辑块组,这16个块组的inode位图,block位图,以及inode table是连续的,如下所示:
Group 0: block bitmap at 1025, inode bitmap at 1041, inode table at 1057
23513 free blocks, 8181 free inodes, 2 used directories, 8181 unused inodes
[Checksum 0x8fd1]
Group 1: block bitmap at 1026, inode bitmap at 1042, inode table at 1569
31743 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Checksum 0xff08]
Group 2: block bitmap at 1027, inode bitmap at 1043, inode table at 2081
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0xebd4]
Group 3: block bitmap at 1028, inode bitmap at 1044, inode table at 2593
31743 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Checksum 0x89d6]
Group 4: block bitmap at 1029, inode bitmap at 1045, inode table at 3105
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0xa182]
Group 5: block bitmap at 1030, inode bitmap at 1046, inode table at 3617
31743 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Checksum 0xfc62]
Group 6: block bitmap at 1031, inode bitmap at 1047, inode table at 4129
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0x79ac]
Group 7: block bitmap at 1032, inode bitmap at 1048, inode table at 4641
31743 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Checksum 0x646a]
Group 8: block bitmap at 1033, inode bitmap at 1049, inode table at 5153
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0xa43c]
Group 9: block bitmap at 1034, inode bitmap at 1050, inode table at 5665
31743 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Checksum 0xf9dc]
Group 10: block bitmap at 1035, inode bitmap at 1051, inode table at 6177
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0xed00]
Group 11: block bitmap at 1036, inode bitmap at 1052, inode table at 6689
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0x6dc8]
Group 12: block bitmap at 1037, inode bitmap at 1053, inode table at 7201
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0xa756]
Group 13: block bitmap at 1038, inode bitmap at 1054, inode table at 7713
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0x187c]
Group 14: block bitmap at 1039, inode bitmap at 1055, inode table at 8225
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0x1d5f]
Group 15: block bitmap at 1040, inode bitmap at 1056, inode table at 8737
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
32768 blocks per group, 32768 fragments per group
Group 16: block bitmap at 524288, inode bitmap at 524304, inode table at 524320
24544 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Checksum 0x2f61]
Group 17: block bitmap at 524289, inode bitmap at 524305, inode table at 524832
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0xb41c]
Group 18: block bitmap at 524290, inode bitmap at 524306, inode table at 525344
32768 free blocks, 8192 free inodes, 0 used directories, 8192 unused inodes
[Inode not init, Block not init, Checksum 0x1572]
我们不难看出 Group 0~Group 15组成了战斗小组,这个战斗小组metadata信息是连续的,后面的Group 16~Group 31也是一样的,依次类推。
- 1025~1040 block bitmap
- 1041~1056 inode bitmap
- 1057~8737+512 inode table
EXT4文件系统有一个控制选项inode_readahead_blks,该参数是指定了inode 预读的块数,如果不启用flex_bg,纵然inode_readahead_blks设置的很大,比如4096,但是因为块组之间inode不连续(比如单个块组 inode table只占用了256个块),这种是没有意义的。 root@node-1:/# cat /sys/fs/ext4/sdb2/inode_readahead_blks 32
对于连续读的场景,flex_bg配合较大的inode_readahead_blks,能提升连续读的性能。《Linux内核精髓:精通Linux内核必会的75个绝技》一书中提到,当inode_readahead_blks 等于1和等于4096时对比,读取内核所有源码文件有6%左右的提升。
inode_readahead_blks = 1
# time find /mnt/mp1/linux-2.6.39-rc1 -type f -exec cat > /dev/null {} \;
real 3m36.599s
user 0m5.092s
sys 0m43.510s
inode_readahead_blks = 4096
# time find /mnt/mp1/linux-2.6.39-rc1 -type f -exec cat > /dev/null {} \;
real 3m23.613s
user 0m5.080s
sys 0m43.341s
这个战斗小组中块组的个数,取决于超级块中的sb.s_log_groups_per_flex成员变量,该值默认是4,即一个战斗小组中有2^s_log_groups_per_flex个(即16个)块组。
当然战斗小组成员的个数是可以调整的,mke2fs 提供了-G格式化选项,通过该选项,可以指定由多少个块组组成一个战斗小组。但是该值需要是2的整数幂。
root@node-1:/# mkfs.ext4 -G 64 /dev/loop0
mke2fs 1.42 (29-Nov-2011)
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
6553600 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
此时,通过tune2fs 可以看出Flex block group siz是64。当然了debugfs -R stats 命令一样可以看到该值。
root@node-1:/# tune2fs -l /dev/loop0 |grep Flex
Flex block group size: 64
packed_meta_blocks
EXT4出了flex_bg这个影响布局的选项外,同时提供了另外一种更加天外飞仙的扩展选项 packed_meta_blocks,这个扩展选项的作用是将位图和inode table放置在整个存储区域的头部。
这个feature好的地方在于,可以将元数据集中在整个存储的头部。表面看没什么,但是如果将元数据信息聚集在一起,就有机会将元数据放到更快速,容量更小的设备上,比如SSD + HDD,我们完全可以将SSD切出一个分区,和HDD组成一个整体,然后将元数据信息存放到SSD上。
ceph的mail list中给出如下的方案,很有参考价值:
size_of() {
blockdev --getsize $1
}
mkdmsetup() {
_ssd=/dev/$1
_hdd=/dev/$2
_size_of_ssd=$(size_of $_ssd)
echo """0 $_size_of_ssd linear $_ssd 0
$_size_of_ssd $(size_of $_hdd) linear $_hdd 0" | dmsetup create dm-${1}-${2}
}
mkdmsetup sdg1 sdb
mkfs.ext4 -O
^has_journal,flex_bg,^uninit_bg,^sparse_super,sparse_super2,^extra_isize,^dir_nlink,^resize_inode
-E packed_meta_blocks=1,lazy_itable_init=0 -G 32768 -I 128 -i
$((1024*512)) /dev/mapper/dm-sdg1-sdb