前言
Finisher是ceph的一个基础类,ceph的实现中有大量的回调,在回调中,Finisher是重要的组成部分。
基础数据结构
我们以最基本写流程为例:
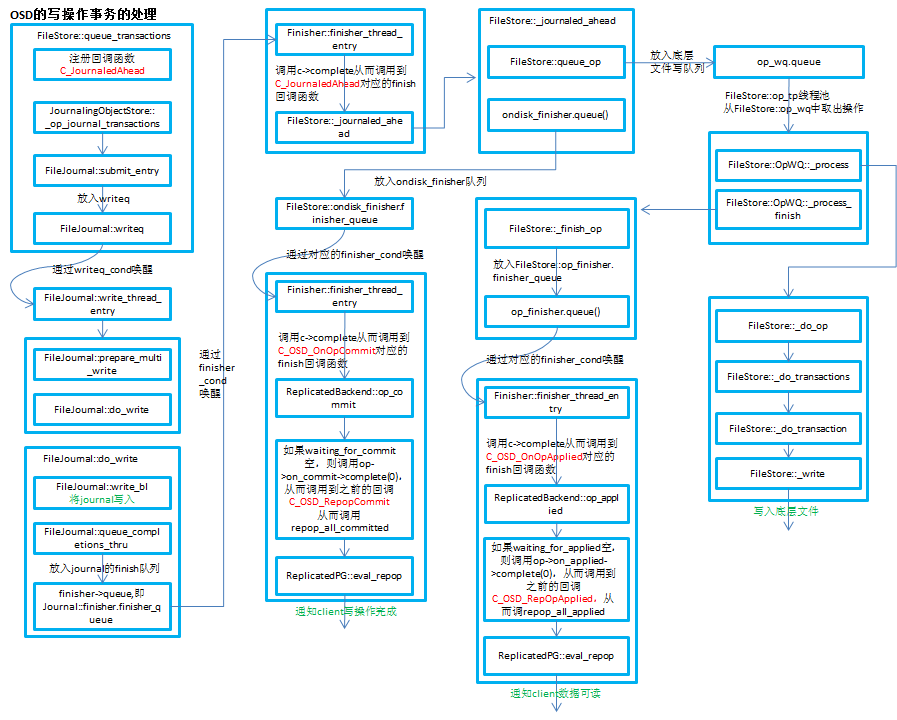
图片来自dong_wu大神的CEPH OSD 读写流程(2),无意盗取,作者介意的话立删。
上图中就有多个Finisher,其实Finisher的本质是任务队列和线程:
class Finisher {
CephContext *cct;
Mutex finisher_lock; ///< Protects access to queues and finisher_running.
Cond finisher_cond; ///< Signaled when there is something to process.
Cond finisher_empty_cond; ///< Signaled when the finisher has nothing more to process.
bool finisher_stop; ///< Set when the finisher should stop.
bool finisher_running; ///< True when the finisher is currently executing contexts.
/// Queue for contexts for which complete(0) will be called.
/// NULLs in this queue indicate that an item from finisher_queue_rval
/// should be completed in that place instead.
/*任务队列,当任务完成时*/
vector<Context*> finisher_queue;
/*线程的名字*/
string thread_name;
list<pair<Context*,int> > finisher_queue_rval;
PerfCounters *logger;
/*线程的主函数*/
void *finisher_thread_entry();
/*FinisherThread 继承了Thread 基类*/
struct FinisherThread : public Thread {
Finisher *fin;
explicit FinisherThread(Finisher *f) : fin(f) {}
void* entry() { return (void*)fin->finisher_thread_entry(); }
} finisher_thread
上面的成员变量中,最重要的两个成员变量是finisher_queue和finisher_thread,而finisher_thread继承了Thread的基类,因为Thread这个类比较简单,基本就是Linux下线程的基本操作,所以不再赘述。
当在合适的时机,将任务插入队列,当然,Finisher类中的线程自然会消化这些任务,首先看将任务推入队列的函数:
/*将单个任务推入队列*/
void queue(Context *c, int r = 0) {
finisher_lock.Lock();
if (finisher_queue.empty()) {
finisher_cond.Signal();
}
if (r) {
finisher_queue_rval.push_back(pair<Context*, int>(c, r));
finisher_queue.push_back(NULL);
} else
finisher_queue.push_back(c);
if (logger)
logger->inc(l_finisher_queue_len);
finisher_lock.Unlock();
}
/*将多个任务组成的vector推入队列*/
void queue(vector<Context*>& ls) {
finisher_lock.Lock();
if (finisher_queue.empty()) {
finisher_cond.Signal();
}
finisher_queue.insert(finisher_queue.end(), ls.begin(), ls.end());
if (logger)
logger->inc(l_finisher_queue_len, ls.size());
finisher_lock.Unlock();
ls.clear();
}
注意,由于finisher_queue是个 Contect指针类型的vector,它支持将多种类型的推入其中,比如单独的Context指针,比如Context指针vector,列表,双向队列,等等,大同小异,考得都是vector支持的标准操作:
single element (1) iterator insert (iterator position, const value_type& val);
fill (2) void insert (iterator position, size_type n, const value_type& val);
range (3) template <class InputIterator> void insert (iterator position, InputIterator first, InputIterator last);
此处插一句,当插入单个任务的时候,如果r != 0那么插入的并不是finisher_queue,而是finisher_queue_rval这个列表。
void queue(Context *c, int r = 0)
任务进入队列,接下来是工作线程的职责了。
void *Finisher::finisher_thread_entry()
{
finisher_lock.Lock();
ldout(cct, 10) << "finisher_thread start" << dendl;
utime_t start;
while (!finisher_stop) {
/// Every time we are woken up, we process the queue until it is empty.
while (!finisher_queue.empty()) {
if (logger)
start = ceph_clock_now(cct);
/*快速地将任务换出,换出以后就可以解锁了,无需等待任务完成才解锁,减少锁的竞争。*/
vector<Context*> ls;
list<pair<Context*,int> > ls_rval;
ls.swap(finisher_queue);
ls_rval.swap(finisher_queue_rval);
finisher_running = true;
finisher_lock.Unlock();
ldout(cct, 10) << "finisher_thread doing " << ls << dendl;
// Now actually process the contexts.
for (vector<Context*>::iterator p = ls.begin();
p != ls.end();
++p) {
if (*p) {
/*无需参数的情况,即queue时r = 0的情况*/
(*p)->complete(0);
} else {
/*需要参数的情况,即queue时, r !=0的情况*/
assert(!ls_rval.empty());
Context *c = ls_rval.front().first;
c->complete(ls_rval.front().second);
ls_rval.pop_front();
}
if (logger) {
logger->dec(l_finisher_queue_len);
logger->tinc(l_finisher_complete_lat, ceph_clock_now(cct) - start);
}
}
ldout(cct, 10) << "finisher_thread done with " << ls << dendl;
ls.clear();
finisher_lock.Lock();
finisher_running = false;
}
ldout(cct, 10) << "finisher_thread empty" << dendl;
finisher_empty_cond.Signal();
if (finisher_stop)
break;
ldout(cct, 10) << "finisher_thread sleeping" << dendl;
finisher_cond.Wait(finisher_lock);
}
// If we are exiting, we signal the thread waiting in stop(),
// otherwise it would never unblock
finisher_empty_cond.Signal();
ldout(cct, 10) << "finisher_thread stop" << dendl;
finisher_stop = false;
finisher_lock.Unlock();
return 0;
}
注意,在入队列的时候,类型时Context或者pair<Context*,int>, 其中Context有一个重要的变量即complete函数,如何处理任务,Context已经交代的很清楚了,而finished_thread_entry不过是搭建一个舞台一个框架罢了。
例子
下面以ondisk_finisher为例介绍 Finisher的使用过程
首先引入FileStore的时候,ondisk_finisher作为成员,就会被引入。注意ceph早期的版本中,每个OSD只有一个ondisk_finisher,在高版本中,ondisk_finisher的数量变成可以配置。 m_ondisk_finisher_num(g_conf->filestore_ondisk_finisher_threads),多个线程自然是为了增大并发,提高处理能力。
FileStore::FileStore(const std::string &base, const std::string &jdev, osflagbits_t flags, const char *name, bool do_update) :
...
for (int i = 0; i < m_ondisk_finisher_num; ++i) {
ostringstream oss;
oss << "filestore-ondisk-" << i;
Finisher *f = new Finisher(g_ceph_context, oss.str(), "fn_odsk_fstore");
ondisk_finishers.push_back(f);
}
for (int i = 0; i < m_apply_finisher_num; ++i) {
ostringstream oss;
oss << "filestore-apply-" << i;
Finisher *f = new Finisher(g_ceph_context, oss.str(), "fn_appl_fstore");
apply_finishers.push_back(f);
}
OSD启动的过程中,会掉用FileStore::mount,在该函数中,ondisk_finisher的工作线程也会启动:
init_temp_collections();
journal_start();
op_tp.start();
for (vector<Finisher*>::iterator it = ondisk_finishers.begin(); it != ondisk_finishers.end(); ++it) {
(*it)->start();
}
for (vector<Finisher*>::iterator it = apply_finishers.begin(); it != apply_finishers.end(); ++it) {
(*it)->start();
}
本来想讲ondisk_finisher和applied_finisher在本篇博文介绍完毕,但是写入流程比较复杂,而且目前也太晚了,Finisher就暂时介绍到这。后面介绍写流程的时候,会详细介绍ondisk_finisher和apply_finisher 。