前言
ceph-mon负责的功能有很多:
- startup
- data store
- data sync
- data check
- scrub
- leader elect
- timecheck
- lease
- paxos
- paxos service
- consistency
我们今天先挑一个软一点地柿子捏一下,简单介绍下timecheck。
分布式系统正常运转依赖系统时间,ceph通过这个timecheck机制来检查每个monitor的时间是否一致,如果误差过大(clock skew),会发出警告信息。
我们知道,集群中多个节点可能都存在ceph-mon,当时扮演的角色不同,有一个节点是monitor leader,其他的节点上的monitor 为peon, 在timecheck机制中,两者扮演的角色不同,如下图所示:
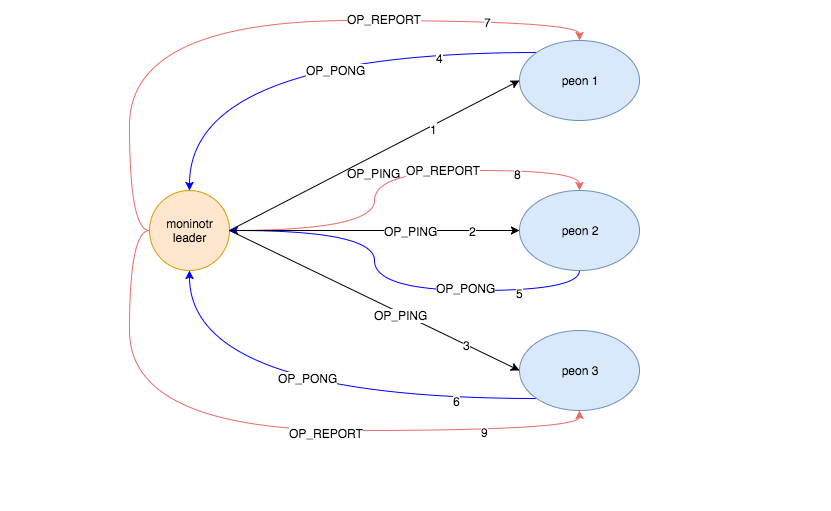
注意,monitor leader是整个战术的发起点,他会主动向所有的peon发送OP_PING请求,所有的peon monitor会恢复OP_PONG,在OP_PONG消息中,会带上自己这边的时间戳。当monitor leader收到回应后,会计算出monitor leader和各个peon中间的时间偏移(估算,无法做到绝对精确),记录到ceph-mon的数据结构中。
当所有的peon都回应过OP_PONG之后,monitor leader收到所有的回应之后,会在timecheck_finish_round 函数中通过调用timecheck_report ,给所有的peon发送OP_REPORT消息,在消息体中,会把monitor leader算出来的时钟偏移和往来延迟记入其中,这样peon收到OP_REPROT消息之后,就能得到,该节点与monitor leader之间的往来延迟和时钟偏移。
粗略的过程就是如上,下面要展开细节,详细的描述这个过程。
原点
不介绍ceph-mon的PAXOS以及election,似乎很难介绍好其他功能,但是们还是暂时放下Paxos和election,我们起点从有一个节点赢得ceph-mon monitor leader的选举开始:
如同封建时代,新皇登基总要大赦天下,提拔一群新的大臣到重要岗位,某个节点的ceph-mon赢得monitor leader 选举之后,也会做一些重新洗牌的动作。其中timecheck的重新初始化也在其中。
void Monitor::win_election(epoch_t epoch, set<int>& active, uint64_t features,
const MonCommand *cmdset, int cmdsize,
const set<int> *classic_monitors)
{
if (monmap->size() > 1 &&
monmap->get_epoch() > 0)
timecheck_start();
}
void Monitor::timecheck_start()
{
dout(10) << __func__ << dendl;
timecheck_cleanup();
timecheck_start_round();
}
void Monitor::timecheck_cleanup()
{
timecheck_round = 0;
timecheck_acks = 0;
timecheck_round_start = utime_t();
if (timecheck_event) {
timer.cancel_event(timecheck_event);
timecheck_event = NULL;
}
timecheck_waiting.clear();
timecheck_skews.clear();
timecheck_latencies.clear();
}
我们可以看到,新当选的monitor leader通过win_election—>timecheck_start—->timecheck_cleanup,完成了对timecheck相关数据结构的重新洗牌。
竞争leader的失败者,也需要重新洗牌,完成对timecheck相关数据结构的初始化。
void Monitor::lose_election(epoch_t epoch, set<int> &q, int l, uint64_t features)
{
state = STATE_PEON;
...
logger->inc(l_mon_election_win);
finish_election();
}
void Monitor::finish_election()
{
apply_quorum_to_compatset_features();
timecheck_finish();
...
}
void Monitor::timecheck_finish()
{
dout(10) << __func__ << dendl;
timecheck_cleanup();
}
void Monitor::timecheck_cleanup()
{
timecheck_round = 0;
timecheck_acks = 0;
timecheck_round_start = utime_t();
if (timecheck_event) {
timer.cancel_event(timecheck_event);
timecheck_event = NULL;
}
timecheck_waiting.clear();
timecheck_skews.clear();
timecheck_latencies.clear();
}
通过上面的讨论可以看到,竞争leader的失败者,也重新初始化了timecheck相关的数据结构。
timecheck的流程
现在我们可以开始讨论下相关的数据结构到底记录什么信息了。
map<entity_inst_t, utime_t> timecheck_waiting;
map<entity_inst_t, double> timecheck_skews;
map<entity_inst_t, double> timecheck_latencies;
// odd value means we are mid-round; even value means the round has
// finished.
version_t timecheck_round;
unsigned int timecheck_acks;
utime_t timecheck_round_start;
首先的话timecheck_round是一个version_t类型,即uint64_t类型的变量。因为timecheck是一轮一轮的做的,因此需要一个轮数的概念。当timecheck_round 是奇数还是偶数,有不同的含义,后面会详细分析。
timecheck_round_start是一个时间值,记录的是本轮timecheck发起的时间。记录下这个时间之后,就要开始给各个PEON monitor发送OP_PING消息了。这个时间非常有用。因为有些时候,可能并不顺利,很可能过了很久,也收不到某个PEON回应的OP_PONG消息,比如发送的时候,该PEON网络还是通的,但是PEON收到消息之后,网路不通了,monitor leader可能无法集齐所有PEON monitor的回应,这种情况下,timecheck需要有cancel的机制,不能因为单个节点的故障,导致大家timecheck都无法进行。
void Monitor::timecheck_start_round()
{
dout(10) << __func__ << " curr " << timecheck_round << dendl;
assert(is_leader());
if (monmap->size() == 1) {
assert(0 == "We are alone; this shouldn't have been scheduled!");
return;
}
if (timecheck_round % 2) {
dout(10) << __func__ << " there's a timecheck going on" << dendl;
utime_t curr_time = ceph_clock_now(g_ceph_context);
double max = g_conf->mon_timecheck_interval*3;
if (curr_time - timecheck_round_start < max) {
dout(10) << __func__ << " keep current round going" << dendl;
goto out;
} else {
dout(10) << __func__
<< " finish current timecheck and start new" << dendl;
timecheck_cancel_round();
}
}
assert(timecheck_round % 2 == 0);
timecheck_acks = 0;
timecheck_round ++;
timecheck_round_start = ceph_clock_now(g_ceph_context);
dout(10) << __func__ << " new " << timecheck_round << dendl;
timecheck();
out:
dout(10) << __func__ << " setting up next event" << dendl;
timecheck_event = new C_TimeCheck(this);
timer.add_event_after(g_conf->mon_timecheck_interval, timecheck_event);
}
前面讲过,timecheck_round是奇数还是偶数,含义是不同的
- 奇数:timecheck已经发起,但是尚未结束
- 偶数:timecheck已经完成,正在等待下一轮timecheck的发起。
wait a minute, 我们提到了等待下一轮,那么到底多久是一轮呢?我们看定时器:
out:
dout(10) << __func__ << " setting up next event" << dendl;
timecheck_event = new C_TimeCheck(this);
timer.add_event_after(g_conf->mon_timecheck_interval, timecheck_event);
OPTION(mon_timecheck_interval, OPT_FLOAT, 300.0)
这个浮点数300秒,定义了timecheck的周期,每五分钟,发起一轮timecheck。注意C_TimeCheck:
struct C_TimeCheck : public Context {
Monitor *mon;
C_TimeCheck(Monitor *m) : mon(m) { }
void finish(int r) {
mon->timecheck_start_round();
}
};
定时器到了,会执行下一轮的timecheck_start_round函数。
注意哈,当ceph-mon成为monitor leader之后,在win_election函数中调用timecheck_start函数,在该函数中会第一次调用timecheck_start_round,后续的timecheck发起,就靠定时任务了。每过300秒,就会发起下一轮的timecheck。
void Monitor::timecheck_start()
{
dout(10) << __func__ << dendl;
timecheck_cleanup();
timecheck_start_round();
}
timecheck_start_round作为timecheck的发起者,就非常重要了。
timecheck_start_round函数
/*如果是只有一个cephmon,压根就不需要发起timecheck,
*事实上win_election中也判定了,是否是一个mon*/
if (monmap->size() == 1) {
assert(0 == "We are alone; this shouldn't have been scheduled!");
return;
}
理想很丰满,显示很骨感,实际情况是很复杂的,比如又有某种原因,上一轮的timecheck迟迟不能结案,现实中又不能不理,因此,下面这段逻辑处理的是timecheck因为某些原因无法结束的情形。如果定时器timeout了,即等待了300秒,结果发现上一轮的timecheck居然还没完工,那么是放弃还是继续等待?取决于等待的时间,如果等待了3倍的mon_timecheck_interval时间,即15分钟以上,还没等到timecheck结束,那么就不等路,直接cancel本轮timecheck,但是如果低于3倍时间,就goto out设置定时器,再等一轮。
/*timecheck_round为奇数的时候,表示有一轮timecheck 正在进行中*/
if (timecheck_round % 2) {
dout(10) << __func__ << " there's a timecheck going on" << dendl;
utime_t curr_time = ceph_clock_now(g_ceph_context);
double max = g_conf-> if (timecheck_round % 2) {
dout(10) << __func__ << " there's a timecheck going on" << dendl;
utime_t curr_time = ceph_clock_now(g_ceph_context);
double max = g_conf->mon_timecheck_interval*3;
/*如果等待时间低于3倍的mon_timecheck_interval,那么再等300秒
* goto out是为了设置新的定时器的*/
if (curr_time - timecheck_round_start < max) {
dout(10) << __func__ << " keep current round going" << dendl;
goto out;
} else {
dout(10) << __func__
<< " finish current timecheck and start new" << dendl;
timecheck_cancel_round();
}
}
正常情况下,300秒的时间,timecheck肯定是完成了,但是也有异常,比如发送OP_PING的时候,PEON好好的,但是某一个PEON就是不给会消息,这种情况下,没有搜集起所有的相应,本轮timecheck就不能结束。上面的逻辑就是处理这个的。
这一部分逻辑是异常部分,正常情况下不会走到。正常部分下,走下面这个逻辑:
/*assert判定,并无当前正在进行的timecheck*/
assert(timecheck_round % 2 == 0);
/*新的一轮check,自然一个回应也没收到*/
timecheck_acks = 0;
/*timecheck_round自加,变成奇数,表示正在进行timecheck*/
timecheck_round ++;
/*记录本轮timecheck的起始时间,到timecheck_round_start变量*/
timecheck_round_start = ceph_clock_now(g_ceph_context);
dout(10) << __func__ << " new " << timecheck_round << dendl;
/*真正发起timecheck*/
timecheck();
out:
dout(10) << __func__ << " setting up next event" << dendl;
timecheck_event = new C_TimeCheck(this);
timer.add_event_after(g_conf->mon_timecheck_interval, timecheck_event);
timecheck函数
void Monitor::timecheck()
{
dout(10) << __func__ << dendl;
assert(is_leader());
if (monmap->size() == 1) {
assert(0 == "We are alone; we shouldn't have gotten here!");
return;
}
assert(timecheck_round % 2 != 0);
timecheck_acks = 1; // we ack ourselves
dout(10) << __func__ << " start timecheck epoch " << get_epoch()
<< " round " << timecheck_round << dendl;
// we are at the eye of the storm; the point of reference
timecheck_skews[messenger->get_myinst()] = 0.0;
timecheck_latencies[messenger->get_myinst()] = 0.0;
for (set<int>::iterator it = quorum.begin(); it != quorum.end(); ++it) {
if (monmap->get_name(*it) == name)
continue;
entity_inst_t inst = monmap->get_inst(*it);
utime_t curr_time = ceph_clock_now(g_ceph_context);
timecheck_waiting[inst] = curr_time;
MTimeCheck *m = new MTimeCheck(MTimeCheck::OP_PING);
m->epoch = get_epoch();
m->round = timecheck_round;
dout(10) << __func__ << " send " << *m << " to " << inst << dendl;
messenger->send_message(m, inst);
}
}
首先是下面的逻辑,用来处理monitor leader自身到自身的时间偏移,毫无疑问,自己和自己肯定是没有任何偏移的,也不需要假惺惺地发消息测试:
timecheck_acks = 1; // we ack ourselves
dout(10) << __func__ << " start timecheck epoch " << get_epoch()
<< " round " << timecheck_round << dendl;
// we are at the eye of the storm; the point of reference
timecheck_skews[messenger->get_myinst()] = 0.0;
timecheck_latencies[messenger->get_myinst()] = 0.0;
接下来是发给其他ceph-mon的消息:
for (set<int>::iterator it = quorum.begin(); it != quorum.end(); ++it) {
/*如果ceph-mon是leader自己,就不用发消息了*/
if (monmap->get_name(*it) == name)
continue;
entity_inst_t inst = monmap->get_inst(*it);
utime_t curr_time = ceph_clock_now(g_ceph_context);
/*记录下发送OP_PING的时间点,到timecheck_waiting[inst],后面会有用
*后面要计算latency,这时候,发送的时间和收到OP_PONG响应的时间,就能估算延迟了*/
timecheck_waiting[inst] = curr_time;
MTimeCheck *m = new MTimeCheck(MTimeCheck::OP_PING);
m->epoch = get_epoch();
m->round = timecheck_round;
dout(10) << __func__ << " send " << *m << " to " << inst << dendl;
messenger->send_message(m, inst);
}
handle_timecheck 函数
对于Monitor::dispatch 函数我就不提了,他是整个Monitor的消息集散中心,其中我们timecheck相关的消息类型,都是这种MSG_TIMECHECK。
case MSG_TIMECHECK:
handle_timecheck(static_cast<MTimeCheck *>(m));
break;
我们细细来看handle_timecheck函数:
void Monitor::handle_timecheck(MTimeCheck *m)
{
dout(10) << __func__ << " " << *m << dendl;
/*monitor leader只会、应该收到 OP_PONG的消息*/
if (is_leader()) {
if (m->op != MTimeCheck::OP_PONG) {
dout(1) << __func__ << " drop unexpected msg (not pong)" << dendl;
} else {
handle_timecheck_leader(m);
}
} else if (is_peon()) {
/*非Leader,则只应该收到OP_PING和OP_REPORT两种消息*/
if (m->op != MTimeCheck::OP_PING && m->op != MTimeCheck::OP_REPORT) {
dout(1) << __func__ << " drop unexpected msg (not ping or report)" << dendl;
} else {
handle_timecheck_peon(m);
}
} else {
dout(1) << __func__ << " drop unexpected msg" << dendl;
}
m->put();
}
很明显,peon只会收到OP_PING和OP_REPORT两种消息,先收到OP_PING。
void Monitor::handle_timecheck_peon(MTimeCheck *m)
{
...
if (m->epoch != get_epoch()) {
dout(1) << __func__ << " got wrong epoch "
<< "(ours " << get_epoch()
<< " theirs: " << m->epoch << ") -- discarding" << dendl;
return;
}
/*如果收到消息的round,小于自己的timecheck_round,表示迷路已久的OP_PING终于到了,
*因为时过境迁,这种过时的消息已经没有回复的必要了。*/
if (m->round < timecheck_round) {
dout(1) << __func__ << " got old round " << m->round
<< " current " << timecheck_round
<< " (epoch " << get_epoch() << ") -- discarding" << dendl;
return;
}
/*peon修改自己的timecheck_round,向monitor leader看起*/
timecheck_round = m->round;
assert((timecheck_round % 2) != 0);
MTimeCheck *reply = new MTimeCheck(MTimeCheck::OP_PONG);
utime_t curr_time = ceph_clock_now(g_ceph_context);
/*把当前节点的时间写入消息体,回给monitor leader*/
reply->timestamp = curr_time;
reply->epoch = m->epoch;
reply->round = m->round;
dout(10) << __func__ << " send " << *m
<< " to " << m->get_source_inst() << dendl;
m->get_connection()->send_message(reply);
}
OK,接下来看下,monitor leader收到 OP_PONG之后,如何处理:
void Monitor::handle_timecheck_leader(MTimeCheck *m)
{
dout(10) << __func__ << " " << *m << dendl;
/* handles PONG's */ /*monitor leader只会OP_PONG类型的消息*/
assert(m->op == MTimeCheck::OP_PONG);
entity_inst_t other = m->get_source_inst();
if (m->epoch < get_epoch()) {
dout(1) << __func__ << " got old timecheck epoch " << m->epoch
<< " from " << other
<< " curr " << get_epoch()
<< " -- severely lagged? discard" << dendl;
return;
}
assert(m->epoch == get_epoch());
if (m->round < timecheck_round) {
dout(1) << __func__ << " got old round " << m->round
<< " from " << other
<< " curr " << timecheck_round << " -- discard" << dendl;
return;
}
utime_t curr_time = ceph_clock_now(g_ceph_context);
/*timecheck_waiting中记录了消息的发送时间
*取出来发送时间之后,该记录可以清除掉了,而该发送时间用来计算延迟latency*/
assert(timecheck_waiting.count(other) > 0);
utime_t timecheck_sent = timecheck_waiting[other];
timecheck_waiting.erase(other);
/*这是一种特殊情况,即收到消息的时间,比发送的时间还要早,
*这意味着monitor leader 调整了时间,如果发生这种情况,本轮timecheck没有必要进行了,cancel掉*/
if (curr_time < timecheck_sent) {
// our clock was readjusted -- drop everything until it all makes sense.
dout(1) << __func__ << " our clock was readjusted --"
<< " bump round and drop current check"
<< dendl;
timecheck_cancel_round();
return;
}
/* 更新monitor leader 到对应peon的latency
* 计算简单粗暴,即收到回应消息的时间减掉发送时间
* 注意如果有历史值的话,要将历史值和当前值加权。
* 最终的latency结果,保存在timecheck_latencies中*/
double latency = (double)(curr_time - timecheck_sent);
if (timecheck_latencies.count(other) == 0)
timecheck_latencies[other] = latency;
else {
double avg_latency = ((timecheck_latencies[other]*0.8)+(latency*0.2));
timecheck_latencies[other] = avg_latency;
}
截止到此处,逻辑比较清晰,latency用发送OP_PING的时间和收到OP_PONG回应的时间来计算。然后将latency信息保存在timecheck_latencies 数据结构。
接下来到了最核心的地方,即如何估算两个节点的时间差。ceph给出了一段很长的注释:
/*
* update skews
*
* some nasty thing goes on if we were to do 'a - b' between two utime_t,
* and 'a' happens to be lower than 'b'; so we use double instead.
*
* latency is always expected to be >= 0.
*
* delta, the difference between theirs timestamp and ours, may either be
* lower or higher than 0; will hardly ever be 0.
*
* The absolute skew is the absolute delta minus the latency, which is
* taken as a whole instead of an rtt given that there is some queueing
* and dispatch times involved and it's hard to assess how long exactly
* it took for the message to travel to the other side and be handled. So
* we call it a bounded skew, the worst case scenario.
*
* Now, to math!
*
* Given that the latency is always positive, we can establish that the
* bounded skew will be:
*
* 1. positive if the absolute delta is higher than the latency and
* delta is positive
* 2. negative if the absolute delta is higher than the latency and
* delta is negative.
* 3. zero if the absolute delta is lower than the latency.
*
* On 3. we make a judgement call and treat the skew as non-existent.
* This is because that, if the absolute delta is lower than the
* latency, then the apparently existing skew is nothing more than a
* side-effect of the high latency at work.
*
* This may not be entirely true though, as a severely skewed clock
* may be masked by an even higher latency, but with high latencies
* we probably have worse issues to deal with than just skewed clocks.
*/
这段注释解释了如何计算两个节点之间的时间偏移(clock skew)。PEON节点的时间戳是a,monitor leader收到OP_PONG之后当前的时间戳是b,那么时间偏移粗略来看是 a-b,但是还是要考虑延迟。
a-b的值要和latency比较一下,如果说(a-b)的绝对值小于latency,说明a和b之间的这点时间偏移太小了,比网络延迟还要小,这种情况下,就不必计较a和b之间的时间偏移。这就是注释当中的第三条。
double delta = ((double) m->timestamp) - ((double) curr_time);
double abs_delta = (delta > 0 ? delta : -delta);
double skew_bound = abs_delta - latency;
/*时间偏移的值小于网络延迟,那么就认为skew_bound =0,没有偏移
*否则,就认定偏移的值为skew_bound,不过还是要根据delta的正负,确定是领先monitor leader,还是落后*/
if (skew_bound < 0)
skew_bound = 0;
else if (delta < 0)
skew_bound = -skew_bound;
ostringstream ss;
health_status_t status = timecheck_status(ss, skew_bound, latency);
if (status == HEALTH_ERR)
clog->error() << other << " " << ss.str() << "\n";
else if (status == HEALTH_WARN)
clog->warn() << other << " " << ss.str() << "\n";
dout(10) << __func__ << " from " << other << " ts " << m->timestamp
<< " delta " << delta << " skew_bound " << skew_bound
<< " latency " << latency << dendl;
if (timecheck_skews.count(other) == 0) {
timecheck_skews[other] = skew_bound;
} else {
timecheck_skews[other] = (timecheck_skews[other]*0.8)+(skew_bound*0.2);
}
/*收到PEON回应的个数自加*/
timecheck_acks++;
/*如果所有的PEON都回应了,那么执行timecheck_finish_round*/
if (timecheck_acks == quorum.size()) {
dout(10) << __func__ << " got pongs from everybody ("
<< timecheck_acks << " total)" << dendl;
assert(timecheck_skews.size() == timecheck_acks);
assert(timecheck_waiting.empty());
// everyone has acked, so bump the round to finish it.
timecheck_finish_round();
}
计算规则就是注释中的三点,不多说。逻辑非常简单,不多说了。如果所有的PEON的回应都收到了,那么执行timecheck_finish_round函数。
/*这个timecheck_finish_round函数是公用的,无论成功还是cancel掉本轮,都会调用
*区别就在标志位success,如果为true,表示成功处理本轮timecheck,所有的PEON的OP_PONG都收到
*如果success = false,表示本轮失败,由于某种原因,取消掉了本轮timecheck*/
void Monitor::timecheck_finish_round(bool success)
{
dout(10) << __func__ << " curr " << timecheck_round << dendl;
assert(timecheck_round % 2);
timecheck_round ++;
timecheck_round_start = utime_t();
/*如果成功,则发送OP_REPORT消息到各个PEON,通知他们更新最新计算出来的clock skew*/
if (success) {
assert(timecheck_waiting.empty());
assert(timecheck_acks == quorum.size());
timecheck_report();
return;
}
/*如果是取消本轮timecheck的话,将还未收到消息的PEON从timecheck_waiting中去掉,并打印*/
dout(10) << __func__ << " " << timecheck_waiting.size()
<< " peers still waiting:";
for (map<entity_inst_t,utime_t>::iterator p = timecheck_waiting.begin();
p != timecheck_waiting.end(); ++p) {
*_dout << " " << p->first.name;
}
*_dout << dendl;
timecheck_waiting.clear()
dout(10) << __func__ << " finished to " << timecheck_round << dendl;
}
注意,如果所有的PEON的回应都收到,才会,通过timecheck_report 发送OP_REPORT消息到各个PEON。为什么要发送这个消息呢。其实就是把最新的计算结果告诉PEON,通知它,所有PEON与monitor leader的时间偏移和延迟。
void Monitor::timecheck_report()
{
dout(10) << __func__ << dendl;
assert(is_leader());
assert((timecheck_round % 2) == 0);
if (monmap->size() == 1) {
assert(0 == "We are alone; we shouldn't have gotten here!");
return;
}
assert(timecheck_latencies.size() == timecheck_skews.size());
bool do_output = true; // only output report once
for (set<int>::iterator q = quorum.begin(); q != quorum.end(); ++q) {
/*如果是monitor leader ,不用自己发给你自己*/
if (monmap->get_name(*q) == name)
continue;
MTimeCheck *m = new MTimeCheck(MTimeCheck::OP_REPORT);
m->epoch = get_epoch();
m->round = timecheck_round;
for (map<entity_inst_t, double>::iterator it = timecheck_skews.begin(); it != timecheck_skews.end(); ++it) {
double skew = it->second;
double latency = timecheck_latencies[it->first];
/*消息体里,带着skew和latency的信息,把最新的结果告诉对端的PEON*/
m->skews[it->first] = skew;
m->latencies[it->first] = latency;
if (do_output) {
dout(25) << __func__ << " " << it->first
<< " latency " << latency
<< " skew " << skew << dendl;
}
}
do_output = false;
entity_inst_t inst = monmap->get_inst(*q);
dout(10) << __func__ << " send report to " << inst << dendl;
messenger->send_message(m, inst);
}
}
对端的PEON收到OP_REPORT信息之后,把这个信息记录下来:
void Monitor::handle_timecheck_peon(MTimeCheck *m)
{
...
timecheck_round = m->round;
if (m->op == MTimeCheck::OP_REPORT) {
assert((timecheck_round % 2) == 0);
/*记录下来monitor leader发过来的最新的latency和skew信息*/
timecheck_latencies.swap(m->latencies);
timecheck_skews.swap(m->skews);
return;
}
...
}
如果clock skew,如何处理
讲了这么多,还是没说,如果发生了这种情况,如何处理。
首先是如果节点间的时间偏移确实很大,ceph health detail中会有警告信息出现,那么问题是多大的偏移才叫比较大呢?
health_status_t Monitor::timecheck_status(ostringstream &ss,
const double skew_bound,
const double latency)
{
health_status_t status = HEALTH_OK;
double abs_skew = (skew_bound > 0 ? skew_bound : -skew_bound);
assert(latency >= 0);
if (abs_skew > g_conf->mon_clock_drift_allowed) {
status = HEALTH_WARN;
ss << "clock skew " << abs_skew << "s"
<< " > max " << g_conf->mon_clock_drift_allowed << "s";
}
return status;
}
此处有个配置项,mon_clock_drift_allowed
OPTION(mon_clock_drift_allowed, OPT_FLOAT, .050)
即,允许节点之间的偏移为50毫秒。
如果超过,ceph health detail 会有如下的打印:
ceph health detail
HEALTH_WARN clock skew detected on mon.1, mon.2
mon.1 addr 192.168.0.6:6789/0 clock skew 8.37274s > max 0.05s (latency 0.004945s)
mon.2 addr 192.168.0.7:6789/0 clock skew 8.52479s > max 0.05s (latency 0.005965s)
这部分逻辑在
void Monitor::get_health(string& status, bufferlist *detailbl, Formatter *f)
{
...
if (f) {
f->open_object_section("timechecks");
f->dump_unsigned("epoch", get_epoch());
f->dump_int("round", timecheck_round);
f->dump_stream("round_status")
<< ((timecheck_round%2) ? "on-going" : "finished");
}
if (!timecheck_skews.empty()) {
list<string> warns;
if (f)
f->open_array_section("mons");
for (map<entity_inst_t,double>::iterator i = timecheck_skews.begin();
i != timecheck_skews.end(); ++i) {
entity_inst_t inst = i->first;
double skew = i->second;
double latency = timecheck_latencies[inst];
string name = monmap->get_name(inst.addr);
ostringstream tcss;
health_status_t tcstatus = timecheck_status(tcss, skew, latency);
if (tcstatus != HEALTH_OK) {
if (overall > tcstatus)
overall = tcstatus;
warns.push_back(name);
ostringstream tmp_ss;
tmp_ss << "mon." << name
<< " addr " << inst.addr << " " << tcss.str()
<< " (latency " << latency << "s)";
detail.push_back(make_pair(tcstatus, tmp_ss.str()));
}
if (f) {
f->open_object_section("mon");
f->dump_string("name", name.c_str());
f->dump_float("skew", skew);
f->dump_float("latency", latency);
f->dump_stream("health") << tcstatus;
if (tcstatus != HEALTH_OK)
f->dump_stream("details") << tcss.str();
f->close_section();
}
}
...
}
发生这种事情,应该如何处理,很多文章都有提到了,基本就是强制ntpdate一次,让时间强制校准:
-
停掉所有节点的ntpd服务,如果有的话
/etc/init.d/ntpd stop -
同步时间
ntpdate {ntpserver}
注意,如果无法连出外网的情况下,可以选择某一台机器作为NTP Server,大家强制向它看齐。