前言
在do_op函数中,会调用find_object_context,获得对象的上下文信息。
int r = find_object_context(
oid, &obc, can_create,
m->has_flag(CEPH_OSD_FLAG_MAP_SNAP_CLONE),
&missing_oid);
初次运行的时候,OSD进程中并且有对象的上下文信息,需要从OSD对应的存储设备中读取:
#define OI_ATTR "_"
#define SS_ATTR "snapset"
存储设备中,对应的值为:
root@BEAN-2:/data/osd.2/current/2.3a0_head# ll
total 4244
drwxr-xr-x 2 root root 4096 Sep 19 16:09 ./
drwxr-xr-x 4646 root root 135168 Sep 19 14:58 ../
-rw-r--r-- 1 root root 4194304 Sep 19 16:09 100000003eb.00000000__head_AFE74FA0__2
-rw-r--r-- 1 root root 0 Sep 19 14:58 __head_000003A0__2
root@BEAN-2:/data/osd.2/current/2.3a0_head# man getfattr
root@BEAN-2:/data/osd.2/current/2.3a0_head# man getfattr
root@BEAN-2:/data/osd.2/current/2.3a0_head# getfattr -d 100000003eb.00000000__head_AFE74FA0__2
# file: 100000003eb.00000000__head_AFE74FA0__2
user.ceph._=0sDgjxAAAABAM1AAAAAAAAABQAAAAxMDAwMDAwMDNlYi4wMDAwMDAwMP7/////////oE/nrwAAAAAAAgAAAAAAAAAGAxwAAAACAAAAAAAAAP////8AAAAAAAAAAP//////////AAAAAAEAAAAAAAAAMQAAAAAAAAAAAAAAAAAAAAICFQAAAAh2eQAAAAAAAAkAAAAAAAAAAQAAAAAAQAAAAAAAPZ3fVxtaICECAhUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAQAAABCnd9XELeZIQ==
user.ceph.snapset=0sAgIZAAAAAQAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAA==
user.cephos.spill_out=0sMAA=
那么ObjectContext数据结构到底维护了那些信息,OSD中为什么要维护上下文信息,它起到了什么作用呢。
struct ObjectContext {
ObjectState obs;
SnapSetContext *ssc; // may be null
Context *destructor_callback;
private:
Mutex lock;
public:
Cond cond;
int unstable_writes, readers, writers_waiting, readers_waiting;
// set if writes for this object are blocked on another objects recovery
ObjectContextRef blocked_by; // object blocking our writes
set<ObjectContextRef> blocking; // objects whose writes we block
// any entity in obs.oi.watchers MUST be in either watchers or unconnected_watchers.
map<pair<uint64_t, entity_name_t>, WatchRef> watchers;
// attr cache
map<string, bufferlist> attr_cache;
...
}
对于提供信息而言,最重要的是ObjectState obs 和 SnapSetContext *ssc 这两个成员变量:
struct ObjectState {
object_info_t oi;
bool exists; ///< the stored object exists (i.e., we will remember the object_info_t)
ObjectState() : exists(false) {}
ObjectState(const object_info_t &oi_, bool exists_)
: oi(oi_), exists(exists_) {}
};
struct object_info_t {
hobject_t soid;
eversion_t version, prior_version;
version_t user_version;
osd_reqid_t last_reqid;
uint64_t size;
utime_t mtime;
utime_t local_mtime; // local mtime
// note: these are currently encoded into a total 16 bits; see
// encode()/decode() for the weirdness.
typedef enum {
FLAG_LOST = 1<<0,
FLAG_WHITEOUT = 1<<1, // object logically does not exist
FLAG_DIRTY = 1<<2, // object has been modified since last flushed or undirtied
FLAG_OMAP = 1 << 3, // has (or may have) some/any omap data
FLAG_DATA_DIGEST = 1 << 4, // has data crc
FLAG_OMAP_DIGEST = 1 << 5, // has omap crc
FLAG_CACHE_PIN = 1 << 6, // pin the object in cache tier
// ...
FLAG_USES_TMAP = 1<<8, // deprecated; no longer used.
} flag_t;
flag_t flags;
...
}
其中object_info_t类型的成员变量oi,来自存在磁盘上的扩展属性 OI_ATTR,即user.ceph._。
获取到对象上下文之后,OSD会SharedLRU类型的共享cache中。后续的读写操作,都要根据上下文信息决定阻塞与否。
那么这个对象上下文到底是干啥的呢?
作用1:读写互斥
对于object的读写操作是有互斥的。对于这个话题,wu_dong的ceph中对象读写的顺序性及并发性保证介绍的非常精彩。
我们可以理解,如果对于同一个底层对象,同时写入,必然牵扯到互斥,同时读写也必然牵扯互斥。因此,对象层面的互斥是不可少的。在刚才提到的文章中有一图片,非常精炼地介绍了读写流程中 ObjectContext层面的锁:
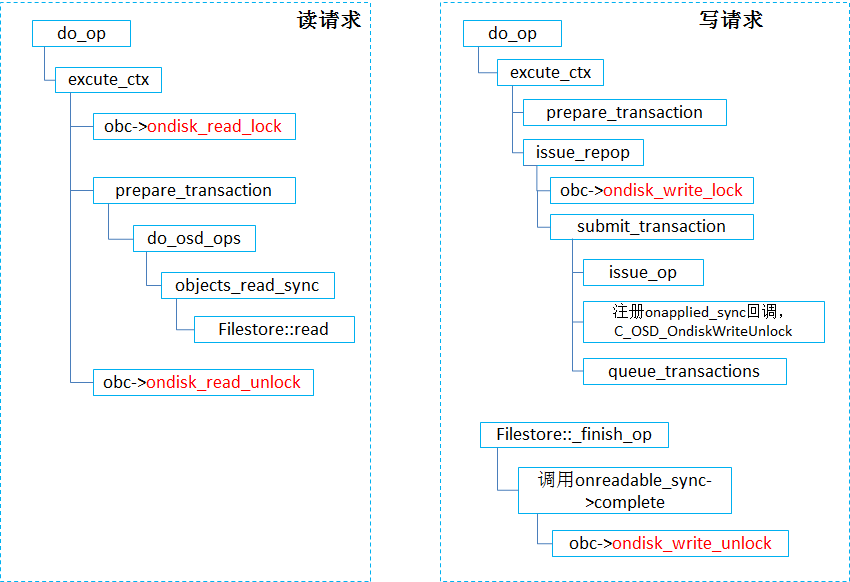
如果对上图介绍的流程不清晰也没关系,因为接下来会重点介绍写流程,会加深理解上图的流程。
// do simple synchronous mutual exclusion, for now. no waitqueues or anything fancy.
void ondisk_write_lock() {
lock.Lock();
writers_waiting++;
while (readers_waiting || readers)
cond.Wait(lock);
writers_waiting--;
unstable_writes++;
lock.Unlock();
}
void ondisk_write_unlock() {
lock.Lock();
assert(unstable_writes > 0);
unstable_writes--;
if (!unstable_writes && readers_waiting)
cond.Signal();
lock.Unlock();
}
void ondisk_read_lock() {
lock.Lock();
readers_waiting++;
while (unstable_writes)
cond.Wait(lock);
readers_waiting--;
readers++;
lock.Unlock();
}
void ondisk_read_unlock() {
lock.Lock();
assert(readers > 0);
readers--;
if (!readers && writers_waiting)
cond.Signal();
lock.Unlock();
}
从上面的加锁操作中,我们不难看出,读读之间是可以并发的,不需要阻塞,写写也是可以并发的,也不会阻塞,ObjectContext上的读写互斥,限制的是同一个对象上的读和写的并发。
我们细细的读上面的代码不难看出,ondisk_write_lock 会一直阻塞(wait),直到没有正在进行中的reader,也没有读请求正在等待(readers_waiting), 但是ondisk_read_lock相对要占一些便宜,它一直阻塞,直到没有正在处理中的写请求(unstable_writes),哪怕此时同时存在其他的写请求(writers_waiting)。
也就是说,对于同一个object,ObjectContext允许同时存在多个读请求正在并发处理,也允许同时存在多个写请求正在并发处理,但是不允许读写混合在一起处理。
读读之间不需要加锁保护是很容易理解的,可是写写之间为什么也不需要加锁互斥呢?同一个对象上的两个写请求会不会导致数据错乱呢?事实上不会,事实上在执行do_op之前,就已经对PG加锁了,请求下发到store层才释放PG lock,因此同一个对象的2个写请求,不会并发进入PG层处理,必定是按照顺序前一个写请求经过pg层的处理后,到达store层进行处理(由另外的线程来进行),然后后一个写请求才会进入pg层处理后下发到store层。
OSD在处理消息的时候,从消息队列中取出消息的时候,就已经给对对应的PG加锁了,对应代码如下:
void OSD::ShardedOpWQ::_process(uint32_t thread_index, heartbeat_handle_d *hb ) {
...
pair<PGRef, PGQueueable> item = sdata->pqueue->dequeue();
sdata->pg_for_processing[&*(item.first)].push_back(item.second);
sdata->sdata_op_ordering_lock.Unlock();
ThreadPool::TPHandle tp_handle(osd->cct, hb, timeout_interval,
suicide_interval);
(item.first)->lock_suspend_timeout(tp_handle);
...
}
void PG::lock_suspend_timeout(ThreadPool::TPHandle &handle)
{
handle.suspend_tp_timeout();
lock();
handle.reset_tp_timeout();
}
void PG::lock(bool no_lockdep) const
{
_lock.Lock(no_lockdep);
// if we have unrecorded dirty state with the lock dropped, there is a bug
assert(!dirty_info);
assert(!dirty_big_info);
dout(30) << "lock" << dendl;
}
另外,并非只有来自客户端的读写请求会调用ObjectContext提供的读写互斥,PG的recovery流程也会调用ondisk_read_unlock。
int ReplicatedPG::prep_object_replica_pushes(
const hobject_t& soid, eversion_t v,
PGBackend::RecoveryHandle *h)
{
...
start_recovery_op(soid);
assert(!recovering.count(soid));
recovering.insert(make_pair(soid, obc));
/* We need this in case there is an in progress write on the object. In fact,
* the only possible write is an update to the xattr due to a lost_revert --
* a client write would be blocked since the object is degraded.
* In almost all cases, therefore, this lock should be uncontended.
*/
obc->ondisk_read_lock();
pgbackend->recover_object(
soid,
v,
ObjectContextRef(),
obc, // has snapset context
h);
obc->ondisk_read_unlock();
return 1;
}
细细读上面的注释,其实可以获得很多的信息。当PG处于degraded状态的时候,会发起Recovery,此时,不会有来自client端的写请求到对象,因此不会有来自client端的写请求竞争锁资源。唯一的可能是lost_revert。
此处其实提醒了我们还存在另外一种可能,即LOST_REVERT。
/**
* do one recovery op.
* return true if done, false if nothing left to do.
*/
uint64_t ReplicatedPG::recover_primary(uint64_t max, ThreadPool::TPHandle &handle)
{
...
case pg_log_entry_t::LOST_REVERT:
{
if (item.have == latest->reverting_to) {
ObjectContextRef obc = get_object_context(soid, true);
if (obc->obs.oi.version == latest->version) {
// I'm already reverting
dout(10) << " already reverting " << soid << dendl;
} else {
dout(10) << " reverting " << soid << " to " << latest->prior_version << dendl;
obc->ondisk_write_lock();
obc->obs.oi.version = latest->version;
ObjectStore::Transaction t;
bufferlist b2;
obc->obs.oi.encode(b2, get_osdmap()->get_up_osd_features());
assert(!pool.info.require_rollback());
t.setattr(coll, ghobject_t(soid), OI_ATTR, b2);
recover_got(soid, latest->version);
missing_loc.add_location(soid, pg_whoami);
++active_pushes;
osd->store->queue_transaction(osr.get(), std::move(t),
new C_OSD_AppliedRecoveredObject(this, obc),
new C_OSD_CommittedPushedObject(
this,
get_osdmap()->get_epoch(),
info.last_complete),
new C_OSD_OndiskWriteUnlock(obc));
continue;
}
}else {
...
}
}
因为此处我们并不会重点介绍recovery流程,以及lost_revert流程,因此,我们一笔带过。知道某些情况下,需要有读写互斥来保护对象即可。
作用2:blocking and blocked by
ObjectContext有两个成员变量 blocking和blocked_by
// set if writes for this object are blocked on another objects recovery
ObjectContextRef blocked_by; // object blocking our writes
set<ObjectContextRef> blocking; // objects whose writes we block
其含义,代码注释解释的非常清楚了。
一般来讲,牵扯到多个对象的,才会存在被某个对象阻塞,或者反过来,阻塞某个对象。
do_op 函数中的如下语句:
if (!ceph_osd_op_type_multi(osd_op.op.op))
continue;
static inline int ceph_osd_op_type_multi(int op)
{
return (op & CEPH_OSD_OP_TYPE) == CEPH_OSD_OP_TYPE_MULTI;
}
如果不带改标志位CEPH_OSD_OP_TYPE_MULTI,就跳过检查。那些类型的操作带了该标志位呢? 从内核的include/linux/ceph/rados.h中,有以下三个操作带了该标志位。从名字上不难看出,都是牵扯到多个对象的操作,比如CLONERANGE,必然牵扯到源和目的。
/** multi **/
CEPH_OSD_OP_CLONERANGE = CEPH_OSD_OP_MODE_WR | CEPH_OSD_OP_TYPE_MULTI | 1,
CEPH_OSD_OP_ASSERT_SRC_VERSION = CEPH_OSD_OP_MODE_RD | CEPH_OSD_OP_TYPE_MULTI | 2,
CEPH_OSD_OP_SRC_CMPXATTR = CEPH_OSD_OP_MODE_RD | CEPH_OSD_OP_TYPE_MULTI | 3,
一般来讲,这个标志用于同一个对象的多个版本,而不是多个不同的对象 (参考 Anatomy of ObjectContext, the Ceph in core representation of an object)。
下面我们阅读 do_op中的如下内容:
if (src_oid.is_head() && is_missing_object(src_oid)) {
wait_for_unreadable_object(src_oid, op);
} else if ((r = find_object_context(
src_oid, &sobc, false, false,
&wait_oid)) == -EAGAIN) {
// missing the specific snap we need; requeue and wait.
wait_for_unreadable_object(wait_oid, op);
} else if (r) {
if (!maybe_handle_cache(op, write_ordered, sobc, r, wait_oid, true))
osd->reply_op_error(op, r);
} else if (sobc->obs.oi.is_whiteout()) {
osd->reply_op_error(op, -ENOENT);
} else {
if (sobc->obs.oi.soid.get_key() != obc->obs.oi.soid.get_key() &&
sobc->obs.oi.soid.get_key() != obc->obs.oi.soid.oid.name &&
sobc->obs.oi.soid.oid.name != obc->obs.oi.soid.get_key()) {
dout(1) << " src_oid " << sobc->obs.oi.soid << " != "
<< obc->obs.oi.soid << dendl;
osd->reply_op_error(op, -EINVAL);
} else if (is_degraded_or_backfilling_object(sobc->obs.oi.soid) ||
(check_src_targ(sobc->obs.oi.soid, obc->obs.oi.soid))) {
if (is_degraded_or_backfilling_object(sobc->obs.oi.soid)) {
wait_for_degraded_object(sobc->obs.oi.soid, op);
} else {
waiting_for_degraded_object[sobc->obs.oi.soid].push_back(op);
op->mark_delayed("waiting for degraded object");
}
dout(10) << " writes for " << obc->obs.oi.soid << " now blocked by "
<< sobc->obs.oi.soid << dendl;
obc->blocked_by = sobc;
sobc->blocking.insert(obc);
} else {
dout(10) << " src_oid " << src_oid << " obc " << src_obc << dendl;
src_obc[src_oid] = sobc;
continue;
}
}
我们看到,如果is_degraded_or_backfilling_object 返回true, 就会执行:
obc->blocked_by = sobc;
sobc->blocking.insert(obc);
这两句是一对,sobc纪录了我阻塞了谁,而obc纪录了我被谁阻塞。
被阻塞的写操作,希望能被及时唤醒,因此将op推入了 waiting_for_degraded_object[soid]对应的链表。后面会讲唤醒。
void ReplicatedPG::wait_for_degraded_object(const hobject_t& soid, OpRequestRef op)
{
assert(is_degraded_or_backfilling_object(soid));
maybe_kick_recovery(soid);
waiting_for_degraded_object[soid].push_back(op);
op->mark_delayed("waiting for degraded object");
}
(check_src_targ函数在此处并不打算展开,否则枝叶太多,掩盖了主干。)
在peering的时候,start_peering_interval会调用ReplicatedPG::on_change函数,而onchange会调用ReplicatedPG::finish_degraded_object函数。
void ReplicatedPG::finish_degraded_object(const hobject_t& oid)
{
dout(10) << "finish_degraded_object " << oid << dendl;
ObjectContextRef obc(object_contexts.lookup(oid));
if (obc) {
for (set<ObjectContextRef>::iterator j = obc->blocking.begin();
j != obc->blocking.end();
obc->blocking.erase(j++)) {
dout(10) << " no longer blocking writes for " << (*j)->obs.oi.soid << dendl;
(*j)->blocked_by = ObjectContextRef();
}
}
if (callbacks_for_degraded_object.count(oid)) {
list<Context*> contexts;
contexts.swap(callbacks_for_degraded_object[oid]);
callbacks_for_degraded_object.erase(oid);
for (list<Context*>::iterator i = contexts.begin();
i != contexts.end();
++i) {
(*i)->complete(0);
}
}
map<hobject_t, snapid_t>::iterator i = objects_blocked_on_degraded_snap.find(
oid.get_head());
if (i != objects_blocked_on_degraded_snap.end() &&
i->second == oid.snap)
objects_blocked_on_degraded_snap.erase(i);
}
另一个值得注意的地方是on_change函数中,会重新将请求入列,然后op_wq队列的工作线程会重新取出op,进行处理。
for (map<hobject_t,list<OpRequestRef>, hobject_t::BitwiseComparator>::iterator p = waiting_for_blocked_object.begin();
p != waiting_for_blocked_object.end();
waiting_for_blocked_object.erase(p++)) {
if (is_primary())
requeue_ops(p->second);
else
p->second.clear();
}
void PG::requeue_ops(list<OpRequestRef> &ls)
{
dout(15) << " requeue_ops " << ls << dendl;
for (list<OpRequestRef>::reverse_iterator i = ls.rbegin();
i != ls.rend();
++i) {
osd->op_wq.queue_front(make_pair(PGRef(this), *i));
}
ls.clear();
}
尾声
至此,我们初步介绍了ObjectContext的作用,有了一个笼统的体会。后面我们会介绍写流程,以及Recovery 等流程,会有更深的体会。