前言
上篇介绍了从读请求到达开始讲起,一直讲到了进入消息队列。以及负责处理读请求的消息队列和线程池的渊源由来。本文重点focus在从队列中取出读请求,后续如何处理该请求。
流程图
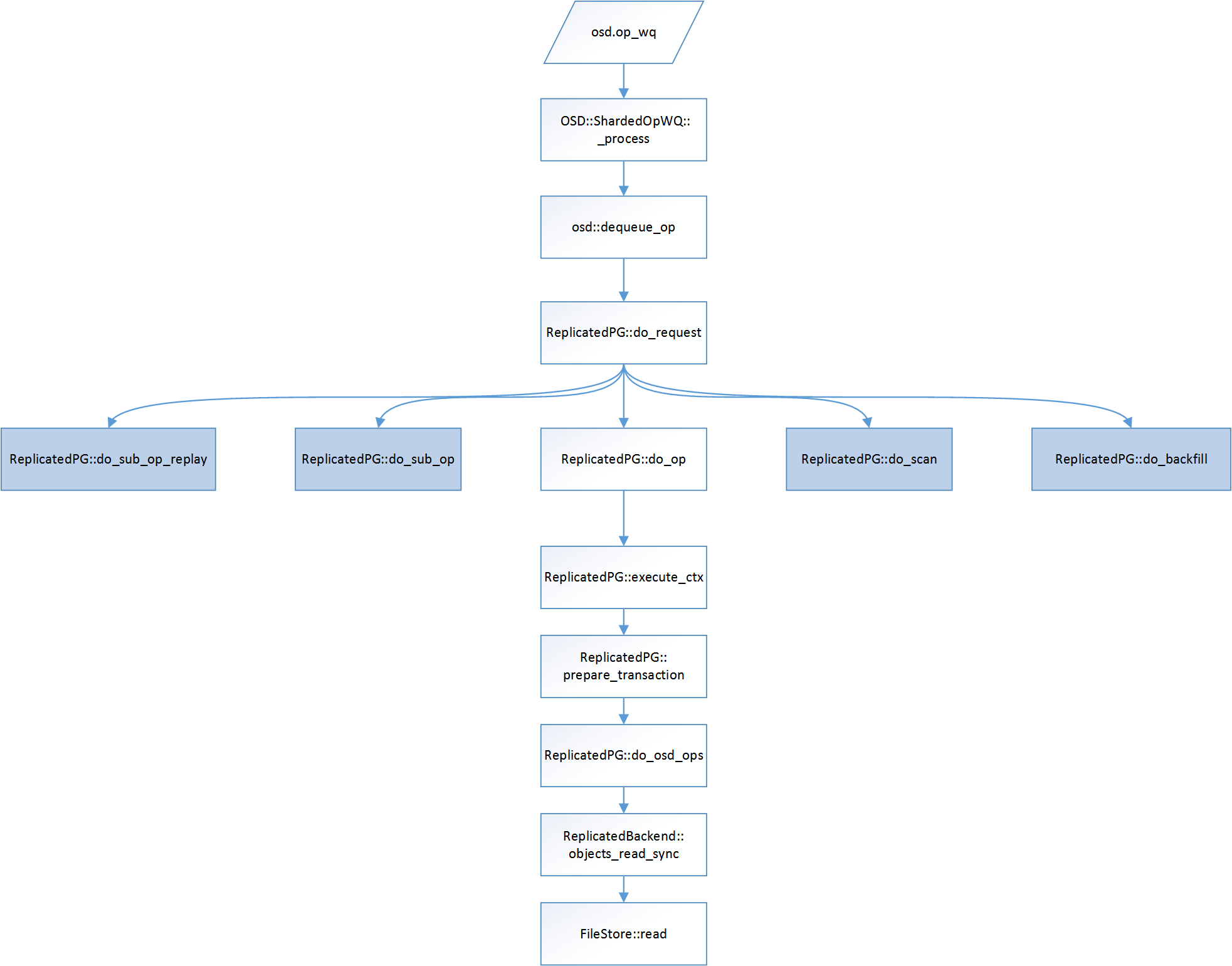
上图是从运行队列开始取出消息,一直到FileStore从磁盘中读到文件的内容的过程。箭头指向并非下一个工序的一次,而是A调用了B的含义。
很多函数很复杂,并非仅仅处理读,比如ReplicatedPG::execute_ctx不仅仅处理读,也处理写以及其他的请求。函数流程异常复杂。我们从读入手的目的,是熟悉相关的调用流程,为后面更复杂的写入,以及更复杂的异常流程做好铺垫,
相关的debug log
我们打开debug log,写入一个4M的文件file_01,从另外一个存储节点读取它
root@BEAN-2:/var/share/ezfs/shareroot/NAS# cephfs file_01 map
WARNING: This tool is deprecated. Use the layout.* xattrs to query and modify layouts.
FILE OFFSET OBJECT OFFSET LENGTH OSD
0 100000003eb.00000000 0 4194304 2
root@BEAN-2:/var/share/ezfs/shareroot/NAS#
root@BEAN-2:/var/share/ezfs/shareroot/NAS#
root@BEAN-2:/var/share/ezfs/shareroot/NAS# ceph osd map data 100000003eb.00000000
osdmap e49 pool 'data' (2) object '100000003eb.00000000' -> pg 2.afe74fa0 (2.3a0) -> up ([2,0], p2) acting ([2,0], p2)
我们通过dd命令读取该文件:
root@BEAN-0:/var/share/ezfs/shareroot/NAS# dd if=file_01 of=/dev/null bs=1M
4+0 records in
4+0 records out
4194304 bytes (4.2 MB) copied, 0.0335059 s, 125 MB/s
很明显osd.2是Primary OSD,因此,读取会从osd.2中读取。osd.2的debug log如下:
log 是giant版本的ceph
2016-09-19 18:02:42.338838 7f9aae9fd700 15 osd.2 49 enqueue_op 0x7f9aa796ae00 prio 127 cost 0 latency 0.000105 osd_op(client.19941.1:20 100000003eb.00000000 [read 2097152~2097152 [1@-1]] 2.afe74fa0 read e49) v4
2016-09-19 18:02:42.338879 7f9ac17f8700 10 osd.2 49 dequeue_op 0x7f9aa796ae00 prio 127 cost 0 latency 0.000146 osd_op(client.19941.1:20 100000003eb.00000000 [read 2097152~2097152 [1@-1]] 2.afe74fa0 read e49) v4 pg pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean]
2016-09-19 18:02:42.338899 7f9ac17f8700 20 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] op_has_sufficient_caps pool=2 (data ) owner=0 need_read_cap=1 need_write_cap=0 need_class_read_cap=0 need_class_write_cap=0 -> yes
2016-09-19 18:02:42.338912 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] handle_message: 0x7f9aa796ae00
2016-09-19 18:02:42.338920 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] do_op osd_op(client.19941.1:20 100000003eb.00000000 [read 2097152~2097152 [1@-1]] 2.afe74fa0 read e49) v4 may_read -> read-ordered flags read
2016-09-19 18:02:42.338943 7f9ac17f8700 15 filestore(/data/osd.2) getattr 2.3a0_head/afe74fa0/100000003eb.00000000/head//2 '_'
2016-09-19 18:02:42.338970 7f9ac17f8700 10 filestore(/data/osd.2) getattr 2.3a0_head/afe74fa0/100000003eb.00000000/head//2 '_' = 247
2016-09-19 18:02:42.338983 7f9ac17f8700 15 filestore(/data/osd.2) getattr 2.3a0_head/afe74fa0/100000003eb.00000000/head//2 'snapset'
2016-09-19 18:02:42.338991 7f9ac17f8700 10 filestore(/data/osd.2) getattr 2.3a0_head/afe74fa0/100000003eb.00000000/head//2 'snapset' = 31
2016-09-19 18:02:42.338998 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] populate_obc_watchers afe74fa0/100000003eb.00000000/head//2
2016-09-19 18:02:42.339006 7f9ac17f8700 20 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] ReplicatedPG::check_blacklisted_obc_watchers for obc afe74fa0/100000003eb.00000000/head//2
2016-09-19 18:02:42.339013 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] get_object_context: creating obc from disk: 0x7f9ad3533500
2016-09-19 18:02:42.339021 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] get_object_context: 0x7f9ad3533500 afe74fa0/100000003eb.00000000/head//2 rwstate(none n=0 w=0) oi: afe74fa0/100000003eb.00000000/head//2(49'1 client.31094.1:9 wrlock_by=unknown.0.0:0 dirty s 4194304 uv1) ssc: 0x7f9ab23e4e00 snapset: 1=[]:[]+head
2016-09-19 18:02:42.339033 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] find_object_context afe74fa0/100000003eb.00000000/head//2 @head oi=afe74fa0/100000003eb.00000000/head//2(49'1 client.31094.1:9 wrlock_by=unknown.0.0:0 dirty s 4194304 uv1)
2016-09-19 18:02:42.339052 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] execute_ctx 0x7f9ad34cd000
2016-09-19 18:02:42.339061 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] do_op afe74fa0/100000003eb.00000000/head//2 [read 2097152~2097152 [1@-1]] ov 49'1
2016-09-19 18:02:42.339069 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] taking ondisk_read_lock
2016-09-19 18:02:42.339077 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] do_osd_op afe74fa0/100000003eb.00000000/head//2 [read 2097152~2097152 [1@-1]]
2016-09-19 18:02:42.339084 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] do_osd_op read 2097152~2097152 [1@-1]
2016-09-19 18:02:42.339092 7f9ac17f8700 15 filestore(/data/osd.2) read 2.3a0_head/afe74fa0/100000003eb.00000000/head//2 2097152~2097152
2016-09-19 18:02:42.339590 7f9ac17f8700 10 filestore(/data/osd.2) FileStore::read 2.3a0_head/afe74fa0/100000003eb.00000000/head//2 2097152~2097152/2097152
2016-09-19 18:02:42.339597 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] read got 2097152 / 2097152 bytes from obj afe74fa0/100000003eb.00000000/head//2
2016-09-19 18:02:42.339611 7f9ac17f8700 15 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] do_osd_op_effects on session 0x7f9aa7811500
2016-09-19 18:02:42.339619 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] dropping ondisk_read_lock
2016-09-19 18:02:42.339629 7f9ac17f8700 15 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] log_op_stats osd_op(client.19941.1:20 100000003eb.00000000 [read 2097152~2097152] 2.afe74fa0 read e49) v4 inb 0 outb 2097152 rlat 0.000000 lat 0.000895
2016-09-19 18:02:42.339659 7f9ac17f8700 15 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] publish_stats_to_osd 49:35
2016-09-19 18:02:42.339671 7f9ac17f8700 15 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47 n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] requeue_ops
2016-09-19 18:02:42.339688 7f9ac17f8700 10 osd.2 49 dequeue_op 0x7f9aa796ae00 finish
我们可以通过上面的debug打印,跟踪读流程的全部过程。
代码分析
deuque_op fucntion
/*
* NOTE: dequeue called in worker thread, with pg lock
*/
void OSD::dequeue_op(
PGRef pg, OpRequestRef op,
ThreadPool::TPHandle &handle)
{
utime_t now = ceph_clock_now(cct);
op->set_dequeued_time(now);
utime_t latency = now - op->get_req()->get_recv_stamp();
dout(10) << "dequeue_op " << op << " prio " << op->get_req()->get_priority()
<< " cost " << op->get_req()->get_cost()
<< " latency " << latency
<< " " << *(op->get_req())
<< " pg " << *pg << dendl;
// share our map with sender, if they're old
if (op->send_map_update) {
Message *m = op->get_req();
Session *session = static_cast<Session *>(m->get_connection()->get_priv());
epoch_t last_sent_epoch;
if (session) {
session->sent_epoch_lock.lock();
last_sent_epoch = session->last_sent_epoch;
session->sent_epoch_lock.unlock();
}
service.share_map(
m->get_source(),
m->get_connection().get(),
op->sent_epoch,
osdmap,
session ? &last_sent_epoch : NULL);
if (session) {
session->sent_epoch_lock.lock();
if (session->last_sent_epoch < last_sent_epoch) {
session->last_sent_epoch = last_sent_epoch;
}
session->sent_epoch_lock.unlock();
session->put();
}
}
if (pg->deleting)
return;
op->mark_reached_pg();
pg->do_request(op, handle);
// finish
dout(10) << "dequeue_op " << op << " finish" << dendl;
}
其中op->mark_reached_pg 表示,对于该op的处理已经到了reach_pg的阶段。
void mark_reached_pg() {
mark_flag_point(flag_reached_pg, "reached_pg");
}
我们dump_ops_in_flight 可以看到当前的OP进行到了哪一步:
注意例子和read没关系,只是为了展示reched_pg 节点。
root@Storage2:~# ceph daemon osd.7 dump_ops_in_flight
{ "num_ops": 1,
"ops": [
{ "description": "osd_op(client.2130451838.0:899198714 rbd_data.2686620486def23.0000000000011595 [sparse-read 4034048~16384] 13.2f7f3fd e34077)",
"rmw_flags": 2,
"received_at": "2016-08-03 10:06:13.399398",
"age": "235.772246",
"duration": "0.000113",
"flag_point": "reached pg",
"client_info": { "client": "client.2130451838",
"tid": 899198714},
"events": [
{ "time": "2016-08-03 10:06:13.399452",
"event": "waiting_for_osdmap"},
{ "time": "2016-08-03 10:06:13.399511",
"event": "reached_pg"}]}]}
do_request function
void ReplicatedPG::do_request(
OpRequestRef& op,
ThreadPool::TPHandle &handle)
{
assert(!op_must_wait_for_map(get_osdmap()->get_epoch(), op));
if (can_discard_request(op)) {
return;
}
if (flushes_in_progress > 0) {
dout(20) << flushes_in_progress
<< " flushes_in_progress pending "
<< "waiting for active on " << op << dendl;
waiting_for_peered.push_back(op);
op->mark_delayed("waiting for peered");
return;
}
if (!is_peered()) {
// Delay unless PGBackend says it's ok
if (pgbackend->can_handle_while_inactive(op)) {
bool handled = pgbackend->handle_message(op);
assert(handled);
return;
} else {
waiting_for_peered.push_back(op);
op->mark_delayed("waiting for peered");
return;
}
}
assert(is_peered() && flushes_in_progress == 0);
if (pgbackend->handle_message(op))
return;
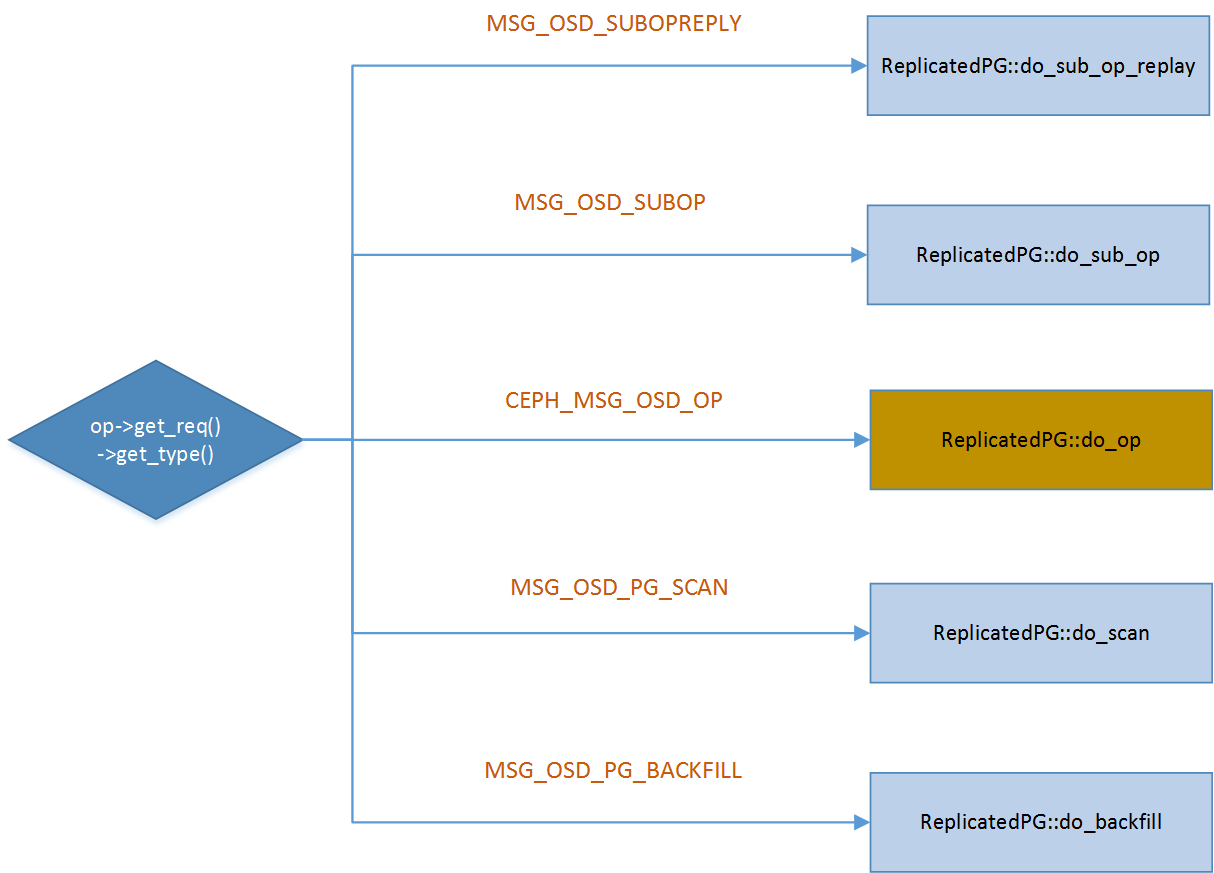
switch (op->get_req()->get_type()) {
case CEPH_MSG_OSD_OP:
if (!is_active()) {
dout(20) << " peered, not active, waiting for active on " << op << dendl;
waiting_for_active.push_back(op)
op->mark_delayed("waiting for active");
return;
}
if (is_replay()) {
dout(20) << " replay, waiting for active on " << op << dendl;
waiting_for_active.push_back(op);
op->mark_delayed("waiting for replay end");
return;
}
// verify client features
if ((pool.info.has_tiers() || pool.info.is_tier()) &&
!op->has_feature(CEPH_FEATURE_OSD_CACHEPOOL)) {
osd->reply_op_error(op, -EOPNOTSUPP);
return;
}
do_op(op); // do it now
break;
...
}
}
该函数是一个消息处理的总控,根据收到的消息的类型不同,调用不同的函数处理。对于read请求,调用为do_op。
do_op function
这个函数非常重要,非常的长,也非常的复杂,原因在于无论是读还是写,无论是cephfs还是rbd,是否又快照,集群状态是否健康,种种因素汇聚于此,导致该函数非常难以理解。
本文不打算每一行代码都详细的展开,展开的话会导致本文异常繁复,事实上我的功力也到不了这个层次,我们就抓主要的正常的流程中的读流程。
void ReplicatedPG::do_op(OpRequestRef& op)
{
MOSDOp *m = static_cast<MOSDOp*>(op->get_req());
assert(m->get_type() == CEPH_MSG_OSD_OP);
/*消息解码*/
m->finish_decode();
m->clear_payload();
if (m->has_flag(CEPH_OSD_FLAG_PARALLELEXEC)) {
// not implemented.
osd->reply_op_error(op, -EINVAL);
return;
}
if (op->rmw_flags == 0) {
/*此处会根据op的类型打上相应的标记,对于我们是读,只会打上*/
int r = osd->osd->init_op_flags(op);
if (r) {
osd->reply_op_error(op, r);
return;
}
}
对于我们普通的读而言,只会打上读标志位
void OpRequest::set_read() { set_rmw_flags(CEPH_OSD_RMW_FLAG_READ); }
正常情况下,读操作只从Primary OSD读取信息,但是如果是读操作,并且设置CEPH_OSD_FLAG_BALANCE_READS或者CEPH_OSD_FLAG_LOCALIZE_READS标志位,那么Primary OSD或者Replica OSD都可以承担读请求。当然了既不是Primary OSD也不是Replica OSD,那么毫无疑问,请求发错了地方。相关代码如下:
if ((m->get_flags() & (CEPH_OSD_FLAG_BALANCE_READS |
CEPH_OSD_FLAG_LOCALIZE_READS)) &&
op->may_read() &&
!(op->may_write() || op->may_cache())) {
// balanced reads; any replica will do
if (!(is_primary() || is_replica())) {
osd->handle_misdirected_op(this, op);
return;
}
} else {
// normal case; must be primary
if (!is_primary()) {
osd->handle_misdirected_op(this, op);
return;
}
}
接下来判断op中是否includes_pg_op操作。调用pg_op_must_wait检查该操作是否需要等待,如果需要等待,加入waiting_for_all_missing队列,如果不需要等待,调用do_pg_op处理pg相关的操作。
if (op->includes_pg_op()) {
if (pg_op_must_wait(m)) {
wait_for_all_missing(op);
return;
}
return do_pg_op(op);
}
接下来是op_has_sufficient_caps检查是否有足够权限
if (!op_has_sufficient_caps(op)) {
osd->reply_op_error(op, -EPERM);
return;
}
接下来根据请求,构建head对象,判断对象是否合法
hobject_t head(m->get_oid(), m->get_object_locator().key,
CEPH_NOSNAP, m->get_pg().ps(),
info.pgid.pool(), m->get_object_locator().nspace);
// object name too long?
if (m->get_oid().name.size() > g_conf->osd_max_object_name_len) {
dout(4) << "do_op name is longer than "
<< g_conf->osd_max_object_name_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_object_locator().key.size() > g_conf->osd_max_object_name_len) {
dout(4) << "do_op locator is longer than "
<< g_conf->osd_max_object_name_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (m->get_object_locator().nspace.size() >
g_conf->osd_max_object_namespace_len) {
dout(4) << "do_op namespace is longer than "
<< g_conf->osd_max_object_namespace_len
<< " bytes" << dendl;
osd->reply_op_error(op, -ENAMETOOLONG);
return;
}
if (int r = osd->store->validate_hobject_key(head)) {
dout(4) << "do_op object " << head << " invalid for backing store: "
<< r << dendl;
osd->reply_op_error(op, r);
return;
}
// blacklisted?
if (get_osdmap()->is_blacklisted(m->get_source_addr())) {
dout(10) << "do_op " << m->get_source_addr() << " is blacklisted" << dendl;
osd->reply_op_error(op, -EBLACKLISTED);
return;
}
首先对象的名字长度,ceph是有限制的,超过长度限制,会返回ENAMETOOLONG,后面有一连串的检查。
也会检查客户端是否在黑名单之后,如果是的话,也会拒绝服务,返回EBLACKLISTED。
接下来的检查时集群是否full,这种检查只有在写请求的时候才会检查,和读无关,如下所示:
// order this op as a write?
bool write_ordered =
op->may_write() ||
op->may_cache() ||
m->has_flag(CEPH_OSD_FLAG_RWORDERED);
// discard due to cluster full transition? (we discard any op that
// originates before the cluster or pool is marked full; the client
// will resend after the full flag is removed or if they expect the
// op to succeed despite being full). The except is FULL_FORCE ops,
// which there is no reason to discard because they bypass all full
// checks anyway.
// If this op isn't write or read-ordered, we skip
// FIXME: we exclude mds writes for now.
if (write_ordered && !( m->get_source().is_mds() || m->has_flag(CEPH_OSD_FLAG_FULL_FORCE)) &&
info.history.last_epoch_marked_full > m->get_map_epoch()) {
dout(10) << __func__ << " discarding op sent before full " << m << " "
<< *m << dendl;
return;
}
if (!(m->get_source().is_mds()) && osd->check_failsafe_full() && write_ordered) {
dout(10) << __func__ << " fail-safe full check failed, dropping request"
<< dendl;
return;
}
常规的检查之后,下面的一条debug级别的打印宣告了do_op要做的事情,
dout(10) << "do_op " << *m
<< (op->may_write() ? " may_write" : "")
<< (op->may_read() ? " may_read" : "")
<< (op->may_cache() ? " may_cache" : "")
<< " -> " << (write_ordered ? "write-ordered" : "read-ordered")
<< " flags " << ceph_osd_flag_string(m->get_flags())
<< dendl;
对于我们这个例子而言,就是如下打印:
2016-09-19 18:02:42.338920 7f9ac17f8700 10 osd.2 pg_epoch: 49 pg[2.3a0( v 49'1 (0'0,49'1] local-les=47
n=1 ec=10 les/c 47/47 46/46/42) [2,0] r=0 lpr=46 crt=0'0 lcod 0'0 mlcod 0'0 active+clean] do_op osd_op
(client.19941.1:20 100000003eb.00000000 [read 2097152~2097152 [1@-1]] 2.afe74fa0 read e49) v4 may_read
-> read-ordered flags read
检查是否是missing object:
// missing object?
if (is_unreadable_object(head)) {
wait_for_unreadable_object(head, op);
return;
}
检查snapdir对象,是否missing等状态,因为此处我们研究最简单的情形,不考虑snap,因此可以略过不读:
// missing snapdir?
hobject_t snapdir = head.get_snapdir();
if (is_unreadable_object(snapdir)) {
wait_for_unreadable_object(snapdir, op);
return;
}
构建oid对象,这才是真正要操作的对象:
hobject_t missing_oid;
hobject_t oid(m->get_oid(),
m->get_object_locator().key,
m->get_snapid(),
m->get_pg().ps(),
m->get_object_locator().get_pool(),
m->get_object_locator().nspace);
接下来的内容是调用函数find_object_context 获取object_context。此处非常关键,是do_op函数中做实事的函数之一。
注意,ObjectContext,是对象的上下文信息,其作用有点类似于内核中的struct file这种上下文信息。对于同一个对象,可能有读操作,有写操作,这些操作必须要互斥,否则的话,可能发生不一致。比如,如果正在进行写操作,那么,对对象的读取操作就必须先阻塞住。反之亦然。
因此,ObjectContext是必不可少的,如果内存中尚没有对应对象的上下文信息ObjectContext,需要从磁盘上加载相关的信息。但是读写操作的时候,一定要有ObjectContext。ceph将对象的上下文信息ObjectContext以LRU的算法维护,维护在内存中。如果内存中没有找到,就需要去磁盘上通过对象的扩展属性生成上下文信息。
这两个属性为:
#define OI_ATTR "_"
#define SS_ATTR "snapset"
从要操作的对象可以看到,其确实存在如下两个扩展属性:
root@BEAN-2:/data/osd.2/current/2.3a0_head# ll
total 4244
drwxr-xr-x 2 root root 4096 Sep 19 16:09 ./
drwxr-xr-x 4646 root root 135168 Sep 19 14:58 ../
-rw-r--r-- 1 root root 4194304 Sep 19 16:09 100000003eb.00000000__head_AFE74FA0__2
-rw-r--r-- 1 root root 0 Sep 19 14:58 __head_000003A0__2
root@BEAN-2:/data/osd.2/current/2.3a0_head# man getfattr
root@BEAN-2:/data/osd.2/current/2.3a0_head# man getfattr
root@BEAN-2:/data/osd.2/current/2.3a0_head# getfattr -d 100000003eb.00000000__head_AFE74FA0__2
# file: 100000003eb.00000000__head_AFE74FA0__2
user.ceph._=0sDgjxAAAABAM1AAAAAAAAABQAAAAxMDAwMDAwMDNlYi4wMDAwMDAwMP7/////////oE/nrwAAAAAAAgAAAAAAAAAGAxwAAAACAAAAAAAAAP////8AAAAAAAAAAP//////////AAAAAAEAAAAAAAAAMQAAAAAAAAAAAAAAAAAAAAICFQAAAAh2eQAAAAAAAAkAAAAAAAAAAQAAAAAAQAAAAAAAPZ3fVxtaICECAhUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAQAAABCnd9XELeZIQ==
user.ceph.snapset=0sAgIZAAAAAQAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAA==
user.cephos.spill_out=0sMAA=
find_object_context 函数,通过user.ceph._ 属性,获得到object_info_t类型的oi信息,通过snapset获得ssc信息,这些信息的具体含义此处略过.
有了obc之后,接下来又是一通检查,在此处略过,直接进入创建opContext和执行execute_ctx:
op->mark_started();
ctx->src_obc.swap(src_obc);
execute_ctx(ctx);
utime_t prepare_latency = ceph_clock_now(cct);
prepare_latency -= op->get_dequeued_time();
osd->logger->tinc(l_osd_op_prepare_lat, prepare_latency);
if (op->may_read() && op->may_write()) {
osd->logger->tinc(l_osd_op_rw_prepare_lat, prepare_latency);
} else if (op->may_read()) {
osd->logger->tinc(l_osd_op_r_prepare_lat, prepare_latency);
} else if (op->may_write() || op->may_cache()) {
osd->logger->tinc(l_osd_op_w_prepare_lat, prepare_latency);
}
这个execute_ctx是非常重要的函数,是整个处理流程中正常流程的台柱子,前面是一些检查,和准备素材,到了execute_ctx开始进入深水区了。 这个函数和do_op一样,因为负责的东西太多,因此比较繁复,我们一样只分析read相关的流程
execute_ctx function
对于读流程而言,相对于写要简单很多:
if (op->may_read()) {
dout(10) << " taking ondisk_read_lock" << dendl;
obc->ondisk_read_lock();
}
for (map<hobject_t,ObjectContextRef, hobject_t::BitwiseComparator>::iterator p = src_obc.begin(); p != src_obc.end(); ++p) {
dout(10) << " taking ondisk_read_lock for src " << p->first << dendl;
p->second->ondisk_read_lock();
}
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = ctx->op->get_reqid();
#endif
tracepoint(osd, prepare_tx_enter, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
int result = prepare_transaction(ctx);
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = ctx->op->get_reqid();
#endif
tracepoint(osd, prepare_tx_exit, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
/**/
if (op->may_read()) {
dout(10) << " dropping ondisk_read_lock" << dendl;
obc->ondisk_read_unlock();
}
for (map<hobject_t,ObjectContextRef, hobject_t::BitwiseComparator>::iterator p = src_obc.begin(); p != src_obc.end(); ++p) {
dout(10) << " dropping ondisk_read_lock for src " << p->first << dendl;
p->second->ondisk_read_unlock();
}
if (result == -EINPROGRESS) {
// come back later.
return;
}
if (result == -EAGAIN) {
// clean up after the ctx
close_op_ctx(ctx);
return;
}
bool successful_write = !ctx->op_t->empty() && op->may_write() && result >= 0;
// prepare the reply
ctx->reply = new MOSDOpReply(m, 0, get_osdmap()->get_epoch(), 0,
successful_write);
if (successful_write) {
// write. normalize the result code.
dout(20) << " zeroing write result code " << result << dendl;
result = 0;
}
ctx->reply->set_result(result);
// read or error?
if ((ctx->op_t->empty() || result < 0) && !ctx->update_log_only) {
// finish side-effects
if (result >= 0)
do_osd_op_effects(ctx, m->get_connection());
if (ctx->pending_async_reads.empty()) {
complete_read_ctx(result, ctx);
} else {
in_progress_async_reads.push_back(make_pair(op, ctx));
ctx->start_async_reads(this);
}
return;
}
主要干了4件事,加锁,prepare_transaction,解锁,回应。
其中加锁就是对对象上下文ObjectContext加读锁。 其中毫无疑问,prepare_transaction承担了核心任务。
注意这个函数绝不像我此处描述的这么简单,尤其是对于后面的写流程来说,控制流非常复杂,后面的 issue_repop,以及eval_repop都是重要的角色,只不过读流程不牵扯该部分的代码,绝不能低估该函数的复杂程度。。
prepare_transaction
该函数将主要的工作委托给了do_osd_ops函数:
int ReplicatedPG::prepare_transaction(OpContext *ctx)
{
assert(!ctx->ops.empty());
const hobject_t& soid = ctx->obs->oi.soid;
// valid snap context?
if (!ctx->snapc.is_valid()) {
dout(10) << " invalid snapc " << ctx->snapc << dendl;
return -EINVAL;
}
// prepare the actual mutation
int result = do_osd_ops(ctx, ctx->ops);
if (result < 0) {
if (ctx->op->may_write() &&
get_osdmap()->test_flag(CEPH_OSDMAP_REQUIRE_KRAKEN)) {
// need to save the error code in the pg log, to detect dup ops,
// but do nothing else
ctx->update_log_only = true;
}
return result;
}
// read-op? done?
if (ctx->op_t->empty() && !ctx->modify) {
unstable_stats.add(ctx->delta_stats);
return result;
}