前言
对于一个分布式存储而言,读和写流程是重头戏,我还记的我刚毕业的时候,在中兴学习ZXDFS的时候,在师父和师公的指点下,学习读写流程的过程,一晃N多年已经过去了。
相对于写而言,读更单纯,更简单,因为对于ceph的副本池而言,写是很复杂的,牵扯到多个副本。对ceph的读而言,只需要访问Primary OSD,读取相应的内容即可。
本文介绍读,醉翁之意不仅仅在酒,也为接下来介绍的写流程扫清前边的共用流程。
整体流程图之核心数据结构
关于读写流程,网上有一些资料,个人遇到的最好的资料为:
- ceph读写流程分析
- ceph osd 读写流程(1) - 主OSD的处理流程
- OSD Request Processing Latency
参考这几篇文章,对照ceph的代码,基本可以将读流程分析清楚。这三者都画了流程图,三者之中,我最爱第三篇的流程图:
简单,明了,不蔓不枝。
关于读操作进入工作队列的流程,我绘制了如下流程图:
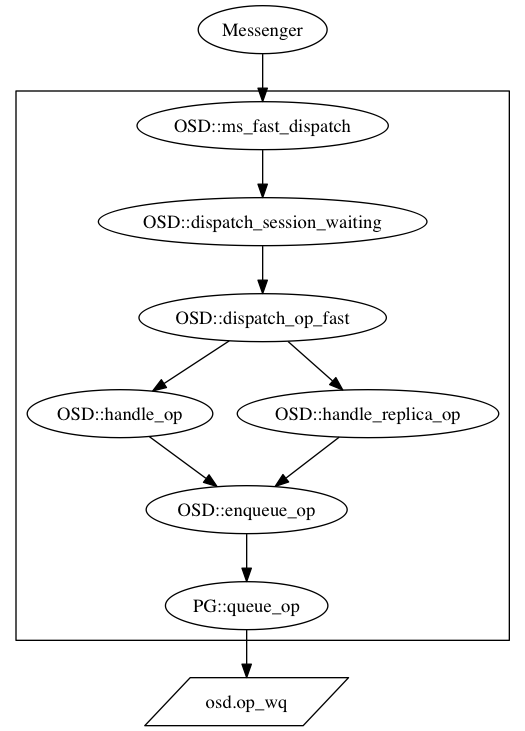
最后进入队列的时候,函数如下:
void PG::queue_op(OpRequestRef& op)
{
Mutex::Locker l(map_lock);
if (!waiting_for_map.empty()) {
// preserve ordering
waiting_for_map.push_back(op);
return;
}
if (op_must_wait_for_map(get_osdmap_with_maplock()->get_epoch(), op)) {
waiting_for_map.push_back(op);
return;
}
osd->op_wq.queue(make_pair(PGRef(this), op));
{
// after queue() to include any locking costs
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(pg, queue_op, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc, op->rmw_flags);
}
}
上面代码中的osd->op_wq是PG进入的队列。
其中代码中的osd是指向OSDService类型的变量:
class PG {
public:
std::string gen_prefix() const;
/*** PG ****/
protected:
OSDService *osd;
CephContext *cct;
...
}
class OSDService {
public:
OSD *osd;
...
ShardedThreadPool::ShardedWQ <PGRef, OpRequestRef> &op_wq;
}
那么这个工作队列到底是啥队列,何时创建的呢?我们从头讲起。
在class OSD,有以下成员变量:
ThreadPool osd_tp;
ShardedThreadPool osd_op_tp;
ThreadPool recovery_tp;
ThreadPool disk_tp;
ThreadPool command_tp;
其中创建对象的时候(OSD::OSD)
osd_tp(cct, "OSD::osd_tp", cct->_conf->osd_op_threads, "osd_op_threads"),
osd_op_tp(cct, "OSD::osd_op_tp",
cct->_conf->osd_op_num_threads_per_shard * cct->_conf->osd_op_num_shards),
recovery_tp(cct, "OSD::recovery_tp", cct->_conf->osd_recovery_threads, "osd_recovery_threads"),
disk_tp(cct, "OSD::disk_tp", cct->_conf->osd_disk_threads, "osd_disk_threads"),
command_tp(cct, "OSD::command_tp", 1),
我们故事的主角共享线程池 osd_op_tp的好搭档工作队列op_shardedwq
op_shardedwq(cct->_conf->osd_op_num_shards, this,
cct->_conf->osd_op_thread_timeout, &osd_op_tp),
生产者将任务放倒工作队列 opshardedwq,线程池中的线程负责从工作队列中取出任务来处理。
创建OSD对象的时候(OSD::OSD函数),会创建出来OSDService对象,在创建OSDService的时候(OSDService::OSDService),会将OSDService中的op_wq变量指向osd对象的opshardedwq,即本质是一个队列。前面流程图中进入OSDService中的op_wq,即进入OSD的opshardedwq队列。
OSDService::OSDService(OSD *osd) :
osd(osd),
cct(osd->cct),
whoami(osd->whoami), store(osd->store),
log_client(osd->log_client), clog(osd->clog),
pg_recovery_stats(osd->pg_recovery_stats),
infos_oid(OSD::make_infos_oid()),
cluster_messenger(osd->cluster_messenger),
client_messenger(osd->client_messenger),
logger(osd->logger),
recoverystate_perf(osd->recoverystate_perf),
monc(osd->monc),
op_wq(osd->op_shardedwq),
peering_wq(osd->peering_wq),
recovery_wq(osd->recovery_wq),
snap_trim_wq(osd->snap_trim_wq),
scrub_wq(osd->scrub_wq),
scrub_finalize_wq(osd->scrub_finalize_wq),
OSD初始化的函数 OSD::init,在load_pgs之后,会创建这些线程池:
osd_tp.start();
osd_op_tp.start();
recovery_tp.start();
disk_tp.start();
command_tp.start();
set_disk_tp_priority();
其中,我们关心的是osd_op_tp.start()
void ShardedThreadPool::start_threads()
{
assert(shardedpool_lock.is_locked());
int32_t thread_index = 0;
while (threads_shardedpool.size() < num_threads) {
WorkThreadSharded *wt = new WorkThreadSharded(this, thread_index);
ldout(cct, 10) << "start_threads creating and starting " << wt << dendl;
threads_shardedpool.push_back(wt);
wt->create();
thread_index++;
}
}
void ShardedThreadPool::start()
{
ldout(cct,10) << "start" << dendl;
shardedpool_lock.Lock();
start_threads();
shardedpool_lock.Unlock();
ldout(cct,15) << "started" << dendl;
}
WorkThreadSharded继承自Thread:
struct WorkThreadSharded : public Thread {
ShardedThreadPool *pool;
uint32_t thread_index;
WorkThreadSharded(ShardedThreadPool *p, uint32_t pthread_index): pool(p),
thread_index(pthread_index) {}
void *entry() {
pool->shardedthreadpool_worker(thread_index);
return 0;
}
};
最关键的线程入口函数为entry,执行的是shardedthreadpool_worker函数,这就是线程池的worker函数,即消费者
void ShardedThreadPool::shardedthreadpool_worker(uint32_t thread_index)
{
assert(wq != NULL);
ldout(cct,10) << "worker start" << dendl;
std::stringstream ss;
ss << name << " thread " << (void*)pthread_self();
heartbeat_handle_d *hb = cct->get_heartbeat_map()->add_worker(ss.str());
while (!stop_threads.read()) {
if(pause_threads.read()) {
shardedpool_lock.Lock();
++num_paused;
wait_cond.Signal();
while(pause_threads.read()) {
cct->get_heartbeat_map()->reset_timeout(
hb,
wq->timeout_interval, wq->suicide_interval);
shardedpool_cond.WaitInterval(cct, shardedpool_lock,
utime_t(
cct->_conf->threadpool_empty_queue_max_wait, 0));
}
--num_paused;
shardedpool_lock.Unlock();
}
if (drain_threads.read()) {
shardedpool_lock.Lock();
if (wq->is_shard_empty(thread_index)) {
++num_drained;
wait_cond.Signal();
while (drain_threads.read()) {
cct->get_heartbeat_map()->reset_timeout(
hb,
wq->timeout_interval, wq->suicide_interval);
shardedpool_cond.WaitInterval(cct, shardedpool_lock,
utime_t(
cct->_conf->threadpool_empty_queue_max_wait, 0));
}
--num_drained;
}
shardedpool_lock.Unlock();
}
cct->get_heartbeat_map()->reset_timeout(
hb,
wq->timeout_interval, wq->suicide_interval);
wq->_process(thread_index, hb);
}
ldout(cct,10) << "sharded worker finish" << dendl;
cct->get_heartbeat_map()->remove_worker(hb);
}
上述代码中,全函数之眼是
wq->_process(thread_index, hb);
而_process 函数定义自ShardedOpWQ,位于src/osd/OSD.cc中
void OSD::ShardedOpWQ::_process(uint32_t thread_index, heartbeat_handle_d *hb ) {
uint32_t shard_index = thread_index % num_shards;
ShardData* sdata = shard_list[shard_index];
assert(NULL != sdata);
sdata->sdata_op_ordering_lock.Lock();
if (sdata->pqueue.empty()) {
sdata->sdata_op_ordering_lock.Unlock();
osd->cct->get_heartbeat_map()->reset_timeout(hb, 4, 0);
sdata->sdata_lock.Lock();
sdata->sdata_cond.WaitInterval(osd->cct, sdata->sdata_lock, utime_t(2, 0));
sdata->sdata_lock.Unlock();
sdata->sdata_op_ordering_lock.Lock();
if(sdata->pqueue.empty()) {
sdata->sdata_op_ordering_lock.Unlock();
return;
}
}
pair<PGRef, OpRequestRef> item = sdata->pqueue.dequeue();
sdata->pg_for_processing[&*(item.first)].push_back(item.second);
sdata->sdata_op_ordering_lock.Unlock();
ThreadPool::TPHandle tp_handle(osd->cct, hb, timeout_interval,
suicide_interval);
(item.first)->lock_suspend_timeout(tp_handle);
OpRequestRef op;
{
Mutex::Locker l(sdata->sdata_op_ordering_lock);
if (!sdata->pg_for_processing.count(&*(item.first))) {
(item.first)->unlock();
return;
}
assert(sdata->pg_for_processing[&*(item.first)].size());
op = sdata->pg_for_processing[&*(item.first)].front();
sdata->pg_for_processing[&*(item.first)].pop_front();
if (!(sdata->pg_for_processing[&*(item.first)].size()))
sdata->pg_for_processing.erase(&*(item.first));
}
// osd:opwq_process marks the point at which an operation has been dequeued
// and will begin to be handled by a worker thread.
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(osd, opwq_process_start, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
lgeneric_subdout(osd->cct, osd, 30) << "dequeue status: ";
Formatter *f = new_formatter("json");
f->open_object_section("q");
dump(f);
f->close_section();
f->flush(*_dout);
delete f;
*_dout << dendl;
osd->dequeue_op(item.first, op, tp_handle);
{
#ifdef WITH_LTTNG
osd_reqid_t reqid = op->get_reqid();
#endif
tracepoint(osd, opwq_process_finish, reqid.name._type,
reqid.name._num, reqid.tid, reqid.inc);
}
(item.first)->unlock();
}
总结
通过本文的学习,我们知道,线程池和工作队列是消息处理的核心,读这个请求的处理也不例外。对于OSD而言,将读请求放入到OSD的op_shardedwq这个队列,和该队列搭档工作的是线程池。线程池中的线程会负责取出消息,然后处理请求。
关于线程工作的细节,我们下一篇在讲述。