前言
部署ceph集群之后,会比较关心其存储集群的容量,包括总容量、已用容量,剩余容量。 今天之所以想写一篇文章介绍这个topic,源自一个很有意思的事情。
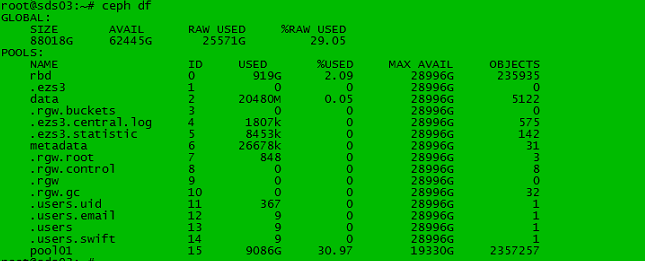
注意在上图中,pool01 是一个三副本的pool,该pool中USED是9086GB,按照三副本计算,其消耗的空间应该是:
9086* 3 = 27258GB
但是实际上, GLOBAL中AVAIL为25571GB,仅算pool 01 也少消耗了1T多,遑论还有其他的pool中也有不可忽视的数据。
为什么GLOBAL中 USED的空间要明显低于 所有的pool中USED的总和呢?
我们下面细细分析这部分逻辑。
ceph df 代码流程梳理
我们首先给出一个真实环境中的 ceph df的输出:
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
2924T 1072T 1851T 63.32
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 188T 0
.ezs3 1 0 0 188T 1
data 2 230 0 188T 5071558
metadata 3 63358k 0 188T 1635135
.rgw.buckets 4 0 0 188T 0
.ezs3.central.log 5 386k 0 188T 1049
.ezs3.statistic 6 33879k 0 188T 530
.rgw.root 7 840 0 188T 3
.rgw.control 8 0 0 188T 8
.rgw 9 207 0 188T 1
.rgw.gc 10 0 0 188T 32
.users.uid 11 6210 0 188T 12
.users.email 12 158 0 188T 12
.users 13 158 0 188T 12
.users.swift 14 307 0 188T 23
.usage 17 0 0 188T 2
pool 18 917T 31.37 188T 37175243
yunweibu 19 4201G 0.14 186T 306273
.rgw.buckets.index 20 0 0 188T 1
rujiaTR 21 1981M 0 188T 698
rujiaAD 22 2012M 0 188T 652
上面是一个真实ceph集群的空间使用情况,通过GLOBAL统计,我们可以看到,总空间2924T,用户已经使用了1851T,剩余空间1072T,注意,用户所有的pool都是双副本。也就是说,用户的数据在920+T。而剩余的1072T,还能存放500T左右的用户数据。
注意各个pool使用量(USED一栏) , 乘以副本个数,是和GLOBAL中的RAW USED 一栏是非常逼近的。 这也是符合我们的直观认识。
但是也有情况是前言的哪种,即各个Pool计算的USED以及考虑副本之后,和GLOBAL中的RAW USED 相去甚远,不能忽略其差距。
为何?
我们要细细考虑GLOBAL和POOL的数据来源是不同的。
源码分析之源头
ceph df这个命令,是由ceph-mon负责处理的。在Monitor::hanlde_command 函数中:
else if (prefix == "df") {
bool verbose = (detail == "detail");
if (f)
f->open_object_section("stats");
pgmon()->dump_fs_stats(ds, f.get(), verbose);
if (!f)
ds << '\n';
pgmon()->dump_pool_stats(ds, f.get(), verbose);
if (f) {
f->close_section();
f->flush(ds);
ds << '\n';
}
}
从上述代码中可以看出来,数据分成两段
- pgmon()->dump_fs_stats
- pgmon()->dump_pool_stats
第一段是dump_fs_stat,也就是我们看到的GLOBAL,第二段是统计pool的,也就就是我们看到的POOL 。
dump_fs_stats
void PGMonitor::dump_fs_stats(stringstream &ss, Formatter *f, bool verbose)
{
if (f) {
f->open_object_section("stats");
f->dump_int("total_bytes", pg_map.osd_sum.kb * 1024ull);
f->dump_int("total_used_bytes", pg_map.osd_sum.kb_used * 1024ull);
f->dump_int("total_avail_bytes", pg_map.osd_sum.kb_avail * 1024ull);
if (verbose) {
f->dump_int("total_objects", pg_map.pg_sum.stats.sum.num_objects);
}
f->close_section();
} else {
TextTable tbl;
tbl.define_column("SIZE", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("AVAIL", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("RAW USED", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("%RAW USED", TextTable::LEFT, TextTable::RIGHT);
if (verbose) {
tbl.define_column("OBJECTS", TextTable::LEFT, TextTable::RIGHT);
}
tbl << stringify(si_t(pg_map.osd_sum.kb*1024))
<< stringify(si_t(pg_map.osd_sum.kb_avail*1024))
<< stringify(si_t(pg_map.osd_sum.kb_used*1024));
float used = 0.0;
if (pg_map.osd_sum.kb > 0) {
used = ((float)pg_map.osd_sum.kb_used / pg_map.osd_sum.kb);
}
tbl << percentify(used*100);
if (verbose) {
tbl << stringify(si_t(pg_map.pg_sum.stats.sum.num_objects));
}
tbl << TextTable::endrow;
ss << "GLOBAL:\n";
tbl.set_indent(4);
ss << tbl;
}
}
可以看到相关字段数值的输出主要依赖pg_map.osd_sum的值,而osd_sum是各个osd_stat的总和。所以我们需要知道单个osd的osd_stat_t是如何计算的。
单个osd_stat_t的计算在update_osd_stat 函数中:
void OSDService::update_osd_stat(vector<int>& hb_peers)
{
Mutex::Locker lock(stat_lock);
// fill in osd stats too
struct statfs stbuf;
/*注意OSD的store是FileStore*/
osd->store->statfs(&stbuf);
uint64_t bytes = stbuf.f_blocks * stbuf.f_bsize;
uint64_t used = (stbuf.f_blocks - stbuf.f_bfree) * stbuf.f_bsize;
uint64_t avail = stbuf.f_bavail * stbuf.f_bsize;
osd_stat.kb = bytes >> 10;
osd_stat.kb_used = used >> 10;
osd_stat.kb_avail = avail >> 10;
osd->logger->set(l_osd_stat_bytes, bytes);
osd->logger->set(l_osd_stat_bytes_used, used);
osd->logger->set(l_osd_stat_bytes_avail, avail);
osd_stat.hb_in.swap(hb_peers);
osd_stat.hb_out.clear();
check_nearfull_warning(osd_stat);
osd->op_tracker.get_age_ms_histogram(&osd_stat.op_queue_age_hist);
dout(20) << "update_osd_stat " << osd_stat << dendl;
}
注意,OSD的store的实例是FileStore,而FileStore的statfs实现如下:
int FileStore::statfs(struct statfs *buf)
{
// basedir and current_fn are different fs if the backend is ZFS
// we return current_fn statfs here because basedir only contains metadata and its size can be ignored.
if (::statfs(current_fn.c_str(), buf) < 0) {
int r = -errno;
assert(!m_filestore_fail_eio || r != -EIO);
return r;
}
return 0;
}
而这个就是我们常说的statfs,可以通过stat -f 这个shell命令查看OSD FileStore所在的本地文件系统的统计信息。
总结: ceph df输出中,GLOBAL一项,来源自OSD 所属Store,我们默认是FileStore对应的本地文件系统使用情况统计,这个统计和我们传统意义上的磁盘空间使用是一致的,比较准确地反应出了所有OSD的文件系统的 总体使用量和总体剩余空间。
dump_pool_stats
void PGMonitor::dump_pool_stats(stringstream &ss, Formatter *f, bool verbose)
{
TextTable tbl;
if (f) {
f->open_array_section("pools");
} else {
tbl.define_column("NAME", TextTable::LEFT, TextTable::LEFT);
tbl.define_column("ID", TextTable::LEFT, TextTable::LEFT);
if (verbose)
tbl.define_column("CATEGORY", TextTable::LEFT, TextTable::LEFT);
tbl.define_column("USED", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("%USED", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("MAX AVAIL", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("OBJECTS", TextTable::LEFT, TextTable::RIGHT);
if (verbose) {
tbl.define_column("DIRTY", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("READ", TextTable::LEFT, TextTable::RIGHT);
tbl.define_column("WRITE", TextTable::LEFT, TextTable::RIGHT);
}
}
map<int,uint64_t> avail_by_rule;
OSDMap &osdmap = mon->osdmon()->osdmap;
for (map<int64_t,pg_pool_t>::const_iterator p = osdmap.get_pools().begin();
p != osdmap.get_pools().end(); ++p) {
int64_t pool_id = p->first;
if ((pool_id < 0) || (pg_map.pg_pool_sum.count(pool_id) == 0))
continue;
const string& pool_name = osdmap.get_pool_name(pool_id);
pool_stat_t &stat = pg_map.pg_pool_sum[pool_id];
const pg_pool_t *pool = osdmap.get_pg_pool(pool_id);
int ruleno = osdmap.crush->find_rule(pool->get_crush_ruleset(),
pool->get_type(),
pool->get_size());
int64_t avail;
if (avail_by_rule.count(ruleno) == 0) {
avail = get_rule_avail(osdmap, ruleno);
if (avail < 0)
avail = 0;
avail_by_rule[ruleno] = avail;
} else {
avail = avail_by_rule[ruleno];
}
switch (pool->get_type()) {
case pg_pool_t::TYPE_REPLICATED:
avail /= pool->get_size();
break;
case pg_pool_t::TYPE_ERASURE:
{
const map<string,string>& ecp =
osdmap.get_erasure_code_profile(pool->erasure_code_profile);
map<string,string>::const_iterator pm = ecp.find("m");
map<string,string>::const_iterator pk = ecp.find("k");
if (pm != ecp.end() && pk != ecp.end()) {
int k = atoi(pk->second.c_str());
int m = atoi(pm->second.c_str());
avail = avail * k / (m + k);
}
}
break;
default:
assert(0 == "unrecognized pool type");
}
if (f) {
f->open_object_section("pool");
f->dump_string("name", pool_name);
f->dump_int("id", pool_id);
f->open_object_section("stats");
} else {
tbl << pool_name
<< pool_id;
if (verbose)
tbl << "-";
}
dump_object_stat_sum(tbl, f, stat.stats.sum, avail, verbose);
if (f)
f->close_section(); // stats
else
tbl << TextTable::endrow;
/*如果命令是ceph df detail*/
if (verbose) {
if (f)
f->open_array_section("categories");
for (map<string,object_stat_sum_t>::iterator it = stat.stats.cat_sum.begin();
it != stat.stats.cat_sum.end(); ++it) {
if (f) {
f->open_object_section(it->first.c_str());
} else {
tbl << ""
<< ""
<< it->first;
}
dump_object_stat_sum(tbl, f, it->second, avail, verbose);
if (f)
f->close_section(); // category name
else
tbl << TextTable::endrow;
}
if (f)
f->close_section(); // categories
}
if (f)
f->close_section(); // pool
}
if (f)
f->close_section();
else {
ss << "POOLS:\n";
tbl.set_indent(4);
ss << tbl;
}
}
其中中间输出数据部分是dump_object_stat_sum :
void PGMonitor::dump_object_stat_sum(TextTable &tbl, Formatter *f,
object_stat_sum_t &sum, uint64_t avail,
bool verbose)
{
if (f) {
f->dump_int("kb_used", SHIFT_ROUND_UP(sum.num_bytes, 10));
f->dump_int("bytes_used", sum.num_bytes);
f->dump_unsigned("max_avail", avail);
f->dump_int("objects", sum.num_objects);
if (verbose) {
f->dump_int("dirty", sum.num_objects_dirty);
f->dump_int("rd", sum.num_rd);
f->dump_int("rd_bytes", sum.num_rd_kb * 1024ull);
f->dump_int("wr", sum.num_wr);
f->dump_int("wr_bytes", sum.num_wr_kb * 1024ull);
}
} else {
/*ceph df 走这个分支*/
tbl << stringify(si_t(sum.num_bytes));
int64_t kb_used = SHIFT_ROUND_UP(sum.num_bytes, 10);
float used = 0.0;
if (pg_map.osd_sum.kb > 0)
used = (float)kb_used / pg_map.osd_sum.kb;
tbl << percentify(used*100);
tbl << si_t(avail);
tbl << sum.num_objects;
if (verbose) {
/*如果是ceph df detail,则输出DIRTY READ 和WRITE*/
tbl << stringify(si_t(sum.num_objects_dirty))
<< stringify(si_t(sum.num_rd))
<< stringify(si_t(sum.num_wr));
}
}
}
注意如果执行的是ceph df detail 则verbose == True输出的样式如下:
root@BEAN-2:~# ceph df detail
GLOBAL:
SIZE AVAIL RAW USED %RAW USED OBJECTS
105G 103G 2010M 1.85 4575
POOLS:
NAME ID CATEGORY USED %USED MAX AVAIL OBJECTS DIRTY READ WRITE
rbd 0 - 65600k 0.06 52162M 29 29 4702k 16317
.ezs3 1 - 0 0 52162M 0 0 0 0
data 2 - 210M 0.19 52162M 64 64 12 118
metadata 3 - 13242k 0.01 52162M 23 23 75 4400
.rgw.buckets 4 - 0 0 52162M 0 0 0 0
.ezs3.central.log 5 - 74570 0 52162M 93 93 0 164
.ezs3.statistic 6 - 3363k 0 52162M 58 58 11669k 6650k
.rgw.root 7 - 840 0 52162M 3 3 160k 3
.rgw.control 8 - 0 0 52162M 8 8 0 0
.rgw 9 - 0 0 52162M 0 0 0 0
.rgw.gc 10 - 0 0 52162M 32 32 73897 49298
.users.uid 11 - 367 0 52162M 1 1 45 4
.users.email 12 - 9 0 52162M 1 1 0 1
.users 13 - 9 0 52162M 1 1 0 1
.users.swift 14 - 9 0 52162M 1 1 0 1
wsg 15 - 1024M 0.94 34775M 261 261 179k 272k
hole 16 - 16000M 14.75 52162M 4000 4000 0 4000
数据的源头是?
通过分析代码我们知道,pool的使用空间(USED)是通过osd来更新的,因为有update(write,truncate,delete等)操作的的时候,会更新ctx->delta_stats,具体请见ReplicatedPG::do_osd_ops。举例的话,可以从处理WRITE的op为入手点,当处理CEPH_OSD_OP_WRITE类型的op的时候,会调用write_update_size_and_usage()。里面会更新ctx->delta_stats。当IO处理完,也就是applied和commited之后,会publish_stats_to_osd()。
void ReplicatedPG::write_update_size_and_usage(object_stat_sum_t& delta_stats, object_info_t& oi,
SnapSet& ss, interval_set<uint64_t>& modified,
uint64_t offset, uint64_t length, bool count_bytes)
{
/*这个函数是用来写入之后更新统计量的*/
interval_set<uint64_t> ch;
if (length)
ch.insert(offset, length);
modified.union_of(ch);
if (length && (offset + length > oi.size)) {
uint64_t new_size = offset + length;
delta_stats.num_bytes += new_size - oi.size;
oi.size = new_size;
}
delta_stats.num_wr++;
if (count_bytes)
delta_stats.num_wr_kb += SHIFT_ROUND_UP(length, 10);
}
这里会将变化的pg的stat_queue_item入队到pg_stat_queue中。然后设置osd_stat_updated为True。入队之后,由tick_timer在C_Tick_WithoutOSDLock这个ctx中通过send_pg_stats()将PG的状态发送给Monitor。这样Monitor就可以知道pg的的变化了。
注意,计算MAX AVAIL会比较麻烦一些,dump_pool_stats 之所以啰里啰唆一长段,很大的篇幅都是用来计算MAX AVAIL.
Ceph是先计算Available的值,然后根据副本策略再计算MAX AVAIL的值。Available的值是在get_rule_avail()中计算的。在该函数中通过get_rule_weight_osd_map()算出来一个有weight的osd列表。
注意这里的weight一般是小于1的,因为它除以了sum。而sum就是pool中所有osd weight的总和。在拿到weight列表后,就会根据pg_map.osd_stat中kb_avail的值进行除以weight,选出其中最小的,作为Available的值。
这么描述有些抽象了,具体举一个例子。比如这里我们的pool中有三个osd,假设kb_avail都是400G
即,{osd_0: 0.9, osd_1, 0.8, osd_2: 0.7}。计算出来的weight值是{osd_0: 0.9/2.4,osd_1: 0.8/2.4,osd_2: 0.7/2.4}
本文这一小节,大量参考Ceph中的容量计算与管理 , 无意剽窃前辈的成果,只是前辈写的太好,我就拿来主义了。
GLOBAL统计和Pool统计的不一致
我们回到开头的疑问,为什么GLOBAL统计的和Pool统计的数值有时候差距甚远。注意大多数情况下是一样的。相差无几的,但是有种情况是真实消耗的磁盘空间要小于所有pool中 USED 乘以副本个数对应的空间之和。
一个很容易构造的长久就是hole。
我们知道,文件可能有hole, 即,比如我要写一个1G的文件,我可能跳过了前面的1023MB,直接offset = 1023MB开始,写入1M的数据。那么这个文件是有洞的。前面的1023MB根本就不消耗磁盘空间。ceph也很容易构造这种场景。
我们以cephfs为例,我们在cephfs中的某个文件夹下,执行如下命令。
seq 1 4000 |xargs -I {} -P 10 dd if=/dev/zero of={} bs=1K seek=4095 count=1
注意,我们创造了4000个文件,但是我们通过seek,跳过前面的4095个1KB的内容,直接写最后的1KB,考虑到4MB 一个object 大小,表面上看,我们创造了4000个4MB的对象,但是实际上,在磁盘空间上,只消耗了很少了的空间。
我们首先比对下创建之前和之后,ceph df的输出情况:
root@BEAN-2:~# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
105G 103G 1928M 1.78
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 65600k 0.06 52195M 29
.ezs3 1 0 0 52195M 0
data 2 210M 0.19 52195M 64
metadata 3 402k 0 52195M 20
.rgw.buckets 4 0 0 52195M 0
.ezs3.central.log 5 73107 0 52195M 91
.ezs3.statistic 6 3363k 0 52195M 58
.rgw.root 7 840 0 52195M 3
.rgw.control 8 0 0 52195M 8
.rgw 9 0 0 52195M 0
.rgw.gc 10 0 0 52195M 32
.users.uid 11 367 0 52195M 1
.users.email 12 9 0 52195M 1
.users 13 9 0 52195M 1
.users.swift 14 9 0 52195M 1
wsg 15 1024M 0.94 34797M 261
hole 16 0 0 52195M 0
root@BEAN-2:~#
seq 1 4000 |xargs -I {} -P 10 dd if=/dev/zero of={} bs=1K seek=4095 count=1
root@BEAN-2:~# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
105G 103G 2000M 1.84
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 65600k 0.06 52170M 29
.ezs3 1 0 0 52170M 0
data 2 210M 0.19 52170M 64
metadata 3 13242k 0.01 52170M 23
.rgw.buckets 4 0 0 52170M 0
.ezs3.central.log 5 73107 0 52170M 91
.ezs3.statistic 6 3363k 0 52170M 58
.rgw.root 7 840 0 52170M 3
.rgw.control 8 0 0 52170M 8
.rgw 9 0 0 52170M 0
.rgw.gc 10 0 0 52170M 32
.users.uid 11 367 0 52170M 1
.users.email 12 9 0 52170M 1
.users 13 9 0 52170M 1
.users.swift 14 9 0 52170M 1
wsg 15 1024M 0.94 34780M 261
hole 16 16000M 14.75 52170M 4000
注意hole这个pool 统计USED是4000*4M =16000MB,但是实际上GLOBAL中USED只增加了72MB。这是因为落到OSD 的FileStore下的本地文件系统来说,单个对象并未消耗4M空间,而是远远小于4M。
我们可以随意去一个文件,比如2005这个文件:
root@BEAN-2:/var/share/ezfs/shareroot/hole# cephfs /var/share/ezfs/shareroot/hole/2005 show_location
WARNING: This tool is deprecated. Use the layout.* xattrs to query and modify layouts.
location.file_offset: 0
location.object_offset:0
location.object_no: 0
location.object_size: 4194304
location.object_name: 10000000bd9.00000000
location.block_offset: 0
location.block_size: 4194304
location.osd: 1
root@BEAN-2:/var/share/ezfs/shareroot/hole# ceph osd map hole 10000000bd9.00000000
osdmap e129 pool 'hole' (16) object '10000000bd9.00000000' -> pg 16.61237fba (16.3ba) -> up ([1,2], p1) acting ([1,2], p1)
通过ceph osd map可以找到该文件位于OSD.1,所属PG为16.3ba。
root@BEAN-2:/data/osd.1/current/16.3ba_head# ll
total 328
drwxr-xr-x 2 root root 4096 Jan 22 02:04 ./
drwxr-xr-x 6385 root root 217088 Jan 22 01:59 ../
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000816.00000000__head_EEA8D3BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000857.00000000__head_486277BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000874.00000000__head_B6B303BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 100000009f4.00000000__head_3EBB4FBA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000ae0.00000000__head_6C5023BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000bd9.00000000__head_61237FBA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000c72.00000000__head_697163BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:03 10000000cc6.00000000__head_414E17BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:04 10000000eba.00000000__head_149CEBBA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:04 10000000ef6.00000000__head_CE01BFBA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:04 10000000ff5.00000000__head_D67A17BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:04 10000001223.00000000__head_AE8D57BA__10
-rw-r--r-- 1 root root 4194304 Jan 22 02:04 100000012c4.00000000__head_B12D2FBA__10
-rw-r--r-- 1 root root 0 Jan 22 01:57 __head_000003BA__10
root@BEAN-2:/data/osd.1/current/16.3ba_head# du -sh .
112K
注意,每个 文件都是4MB,但是这么多对象对应的本地文件,只占用了112KB的空间。
我们通过debugfs的stat 命令可以查看单个对象对应本地文件数据块的个数及数值:,
可以看到,数据块就占用了1块 779263, 数据块消耗了4K的空间。
Inode: 2230199 Type: regular Mode: 0644 Flags: 0x80000
Generation: 2862717981 Version: 0x00000000:00000001
User: 0 Group: 0 Size: 4194304
File ACL: 8923093 Directory ACL: 0
Links: 1 Blockcount: 16
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x5883a284:9dfc1d60 -- Sun Jan 22 02:03:48 2017
atime: 0x5883a284:9dfc1d60 -- Sun Jan 22 02:03:48 2017
mtime: 0x5883a284:9dfc1d60 -- Sun Jan 22 02:03:48 2017
crtime: 0x5883a284:9dfc1d60 -- Sun Jan 22 02:03:48 2017
Size of extra inode fields: 28
Extended attributes stored in inode body:
cephos.spill_out = "30 00 " (2)
EXTENTS:
(1023):779263
(END)