前言
eventscript是CTDB中一个比较重要的组件,节点健康状态的检查,虚拟IP的接管等都离不开这些脚本,本文初步介绍下这些脚本的执行情况。 暂时不介绍每个脚本的职责和调用时机,只是介绍CTDB如何讲这些脚本集成在CTDB daemon中。
eventscript的周期性检查
正常运行期间,ctdb运行所有脚本的monitor检查
root@controller02:~# ctdb scriptstatus
17 scripts were executed last monitor cycle
00.ctdb Status:OK Duration:0.011 Fri May 5 14:45:13 2017
01.reclock Status:OK Duration:0.049 Fri May 5 14:45:13 2017
10.interface Status:OK Duration:0.051 Fri May 5 14:45:14 2017
11.routing Status:OK Duration:0.011 Fri May 5 14:45:14 2017
11.natgw Status:OK Duration:0.011 Fri May 5 14:45:14 2017
13.per_ip_routing Status:OK Duration:0.014 Fri May 5 14:45:14 2017
20.multipathd Status:DISABLED
31.clamd Status:DISABLED
40.fs_use Status:DISABLED
40.vsftpd Status:OK Duration:0.007 Fri May 5 14:45:14 2017
41.httpd Status:OK Duration:0.008 Fri May 5 14:45:14 2017
50.samba Status:OK Duration:0.079 Fri May 5 14:45:14 2017
60.nfs Status:OK Duration:0.018 Fri May 5 14:45:14 2017
60.ganesha Status:DISABLED
62.cnfs Status:OK Duration:0.014 Fri May 5 14:45:14 2017
70.iscsi Status:OK Duration:0.009 Fri May 5 14:45:14 2017
91.lvs Status:OK Duration:0.010 Fri May 5 14:45:14 2017
ctdb 支持插件式的检查,用户可以定义很多eventscript,ctdb daemon会周期性地执行eventscript中定义的检查。
那ctdb daemon是如何周期性地执行这些检查呢,执行那些检查呢?
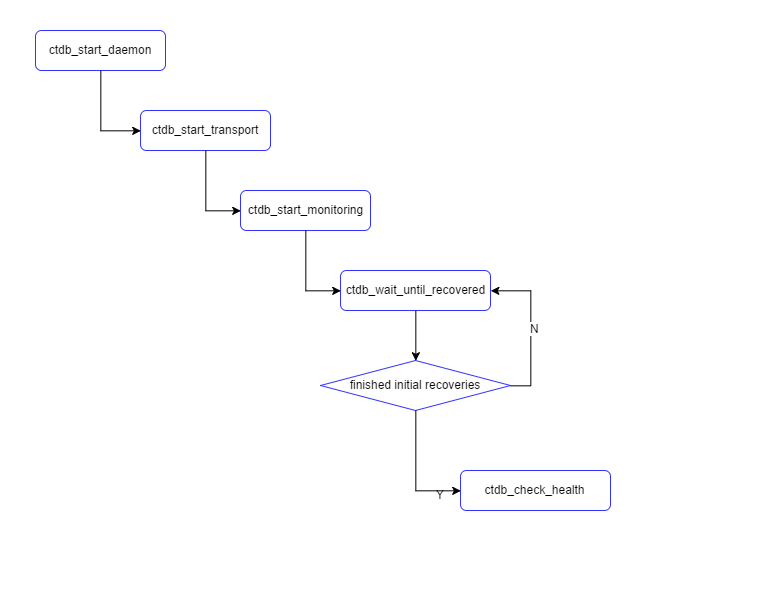
ctdb主进程通过如下代码途径,最终会调用ctdb_check_health,而ctdb_check_health是一个定时任务,周期性地执行。
启动的时候,ctdb_wait_until_recovered函数会检查,recovery是否已经完成,如果完成则进入ctdb_check_health的定时任务,否则继续注册ctdb_wait_until_recovered定时任务,进行下一轮检查。
static void ctdb_check_health(struct event_context *ev, struct timed_event *te,
struct timeval t, void *private_data)
{
struct ctdb_context *ctdb = talloc_get_type(private_data, struct ctdb_context);
int ret = 0;
if (ctdb->recovery_mode != CTDB_RECOVERY_NORMAL ||
(ctdb->monitor->monitoring_mode == CTDB_MONITORING_DISABLED && ctdb->done_startup)) {
event_add_timed(ctdb->ev, ctdb->monitor->monitor_context,
timeval_current_ofs(ctdb->monitor->next_interval, 0),
ctdb_check_health, ctdb);
return;
}
if (!ctdb->done_startup) {
/*第一次执行时,done_startup为false,后续正常运行,不会走入该分支*/
ret = ctdb_event_script_callback(ctdb,
ctdb->monitor->monitor_context, ctdb_startup_callback,
ctdb, false,
CTDB_EVENT_STARTUP, "%s", "");
} else {
/*这个分支是正常运行期间总是执行的分支*/
int i;
int skip_monitoring = 0;
/*如果ctdb cluster正在恢复中,则跳过本轮的检查*/
if (ctdb->recovery_mode != CTDB_RECOVERY_NORMAL) {
skip_monitoring = 1;
DEBUG(DEBUG_ERR,("Skip monitoring during recovery\n"));
}
for (i=1; i<=NUM_DB_PRIORITIES; i++) {
if (ctdb->freeze_handles[i] != NULL) {
DEBUG(DEBUG_ERR,("Skip monitoring since databases are frozen\n"));
skip_monitoring = 1;
break;
}
}
if (skip_monitoring != 0) {
event_add_timed(ctdb->ev, ctdb->monitor->monitor_context,
timeval_current_ofs(ctdb->monitor->next_interval, 0),
ctdb_check_health, ctdb);
return;
} else {
/*这一句是全函数之眼,正常情况下,通过该函数执行各个eventscript的monitor事件*/
ret = ctdb_event_script_callback(ctdb,
ctdb->monitor->monitor_context, ctdb_health_callback,
ctdb, false,
CTDB_EVENT_MONITOR, "%s", "");
}
}
if (ret != 0) {
DEBUG(DEBUG_ERR,("Unable to launch monitor event script\n"));
ctdb->monitor->next_interval = 5;
event_add_timed(ctdb->ev, ctdb->monitor->monitor_context,
timeval_current_ofs(5, 0),
ctdb_check_health, ctdb);
}
}
正常运行过程中,检查的周期是15秒:
root@controller02:/var/log/ctdb# ctdb listvars |grep MonitorInterval
MonitorInterval = 15
通过ctdb的log查看确实也是15秒检查一次
2017/05/05 07:09:01.809874 [472432]: server/eventscript.c:762 Starting eventscript monitor
2017/05/05 07:09:01.983388 [472432]: server/eventscript.c:485 Eventscript monitor finished with state 0
2017/05/05 07:09:16.984169 [472432]: server/eventscript.c:762 Starting eventscript monitor
2017/05/05 07:09:17.218704 [472432]: server/eventscript.c:485 Eventscript monitor finished with state 0
2017/05/05 07:09:32.220844 [472432]: server/eventscript.c:762 Starting eventscript monitor
2017/05/05 07:09:32.426108 [472432]: server/eventscript.c:485 Eventscript monitor finished with state 0
2017/05/05 07:09:47.431600 [472432]: server/eventscript.c:762 Starting eventscript monitor
2017/05/05 07:09:47.734734 [472432]: server/eventscript.c:485 Eventscript monitor finished with state 0
2017/05/05 07:10:02.735392 [472432]: server/eventscript.c:762 Starting eventscript monitor
2017/05/05 07:10:02.964065 [472432]: server/eventscript.c:485 Eventscript monitor finished with state 0
ctdb_event_script_callback
脚本需要支持的事件
这个函数是非常重要的一个函数,执行eventscript ,同时还注册有回调函数,当执行event脚本结束后,执行回调函数。
这里面有个问题要考虑清楚,第一个问题就是eventscript支持的事件很多。我们可以从check_options函数看出eventscript支持的事件。有些事件还需要其他的参数,有些事件不需要其他的参数,check_options函数会检查相应的参数是否齐备。
static bool check_options(enum ctdb_eventscript_call call, const char *options)
{
switch (call) {
/* These all take no arguments. */
case CTDB_EVENT_INIT:
case CTDB_EVENT_SETUP:
case CTDB_EVENT_STARTUP:
case CTDB_EVENT_START_RECOVERY:
case CTDB_EVENT_RECOVERED:
case CTDB_EVENT_STOPPED:
case CTDB_EVENT_MONITOR:
case CTDB_EVENT_STATUS:
case CTDB_EVENT_SHUTDOWN:
case CTDB_EVENT_RELOAD:
case CTDB_EVENT_IPREALLOCATED:
return count_words(options) == 0;
case CTDB_EVENT_TAKE_IP: /* interface, IP address, netmask bits. */
case CTDB_EVENT_RELEASE_IP:
return count_words(options) == 3;
case CTDB_EVENT_UPDATE_IP: /* old interface, new interface, IP address, netmask bits. */
return count_words(options) == 4;
default:
DEBUG(DEBUG_ERR,(__location__ "Unknown ctdb_eventscript_call %u\n", call));
return false;
}
}
虽然支持这么多的时间,但是并不是每一个脚本每一个事件都要支持,很多脚本其实就是对某种时间的处理就是skip。
*)
ctdb_standard_event_handler "$@"
;;
这个ctdb_standard_event_handler函数定义在functions脚本:
ctdb_standard_event_handler ()
{
case "$1" in
status)
ctdb_checkstatus
exit
;;
setstatus)
shift
ctdb_setstatus "$@"
exit
;;
esac
}
ctdb_checkstatus ()
{
if [ -r "$ctdb_status_dir/$script_name/unhealthy" ] ; then
log_status_cat "unhealthy" "$ctdb_status_dir/$script_name/unhealthy"
return 1
elif [ -r "$ctdb_status_dir/$script_name/banned" ] ; then
log_status_cat "banned" "$ctdb_status_dir/$script_name/banned"
return 2
else
return 0
fi
}
ctdb_setstatus ()
{
d="$ctdb_status_dir/$script_name"
case "$1" in
unhealthy|banned)
mkdir -p "$d"
cat "$2" >"$d/$1"
;;
*)
for i in "banned" "unhealthy" ; do
rm -f "$d/$i"
done
;;
esac
}
支持status和setstatus两种事件,基本是往 status dir中touch 对应的状态文件。对于我们的ctdb而言,状态目录位于:
root@controller02:/var/lib/ctdb/state# ll
total 32
drwxr-xr-x 8 root root 4096 May 4 08:03 ./
drwxrwxrwx 6 root root 4096 May 4 08:03 ../
drwxr-xr-x 2 root root 4096 May 4 08:03 ctdb/
drwxr-xr-x 3 root root 4096 May 4 08:03 gpfs/
drwxr-xr-x 2 root root 4096 May 4 08:03 nfs/
drwxr-xr-x 2 root root 4096 May 4 08:03 per_ip_routing/
drwxr-xr-x 2 root root 4096 May 5 17:05 samba/
drwxr-xr-x 2 root root 4096 May 4 08:03 tickles/
其他事件我们暂时不讲,想先获得感性认识的,可以阅读代码中的config/event.d/README。
运行流程
下面介绍下ctdb_event_script_callback函数的运行流程。因为事件是CTDB_EVENT_MONITOR,因此,相当于执行
00.ctdb 10.interface 11.routing 20.multipathd 40.fs_use 41.httpd 60.ganesha 62.cnfs 91.lvs
01.reclock 11.natgw 13.per_ip_routing 31.clamd 40.vsftpd 50.samba 60.nfs 70.iscs
这些脚本都会执行,即 00.ctdb monitor / 10.interface monitor …,但是有两个问题
是否所有的脚本文件都会执行
答案是否定的,因为有些文件并没有执行权限,因此并不会执行,ctdb在ctdb_get_script_list函数中遍历 /etc/ctdb/event.d下的所有文件,如果文件没有可执行权限,就会跳过该文件。
static bool check_executable(const char *dir, const char *name)
{
char *full;
struct stat st;
full = talloc_asprintf(NULL, "%s/%s", dir, name);
if (!full)
return false;
if (stat(full, &st) != 0) {
DEBUG(DEBUG_ERR,("Could not stat event script %s: %s\n",
full, strerror(errno)));
talloc_free(full);
return false;
}
if (!(st.st_mode & S_IXUSR)) {
/*如果脚本没有可执行权限,则打印*/
DEBUG(DEBUG_DEBUG,("Event script %s is not executable. Ignoring this event script\n", full));
errno = ENOEXEC;
talloc_free(full);
return false;
}
talloc_free(full);
return true;
}
我们通过ctdb setdebug DEBUG,可以看到,有类似的打印输出:
2017/05/06 17:50:03.076735 [519718]: Event script /etc/ctdb/events.d/31.clamd is not executable. Ignoring this event script
2017/05/06 17:50:03.076760 [519718]: Event script /etc/ctdb/events.d/60.ganesha is not executable. Ignoring this event script
2017/05/06 17:50:03.076786 [519718]: Event script /etc/ctdb/events.d/40.fs_use is not executable. Ignoring this event script
2017/05/06 17:50:03.076840 [519718]: Event script /etc/ctdb/events.d/20.multipathd is not executable. Ignoring this event script
串行执行 or 并行执行
目录下的多个eventscript是串行执行还是并行执行? 以及如何执行。
答案是串行执行。下面我们进入
static int ctdb_event_script_callback_v(struct ctdb_context *ctdb,
const void *mem_ctx,
void (*callback)(struct ctdb_context *, int, void *),
void *private_data,
bool from_user,
enum ctdb_eventscript_call call,
const char *fmt, va_list ap)
{
struct ctdb_event_script_state *state;
state = talloc(ctdb->event_script_ctx, struct ctdb_event_script_state);
CTDB_NO_MEMORY(ctdb, state);
/* The callback isn't done if the context is freed. */
state->callback = talloc(mem_ctx, struct event_script_callback);
CTDB_NO_MEMORY(ctdb, state->callback);
talloc_set_destructor(state->callback, remove_callback);
state->callback->state = state;
state->callback->fn = callback;
state->callback->private_data = private_data;
state->ctdb = ctdb;
state->from_user = from_user;
state->call = call;
state->options = talloc_vasprintf(state, fmt, ap);
state->timeout = timeval_set(ctdb->tunable.script_timeout, 0);
state->scripts = NULL;
if (state->options == NULL) {
DEBUG(DEBUG_ERR, (__location__ " could not allocate state->options\n"));
talloc_free(state);
return -1;
}
if (!check_options(state->call, state->options)) {
DEBUG(DEBUG_ERR, ("Bad eventscript options '%s' for %s\n",
ctdb_eventscript_call_names[state->call], state->options));
talloc_free(state);
return -1;
}
if (ctdb->recovery_mode != CTDB_RECOVERY_NORMAL) {
/* we guarantee that only some specifically allowed event scripts are run while in recovery */
const enum ctdb_eventscript_call allowed_calls[] = {
CTDB_EVENT_INIT,
CTDB_EVENT_SETUP,
CTDB_EVENT_START_RECOVERY,
CTDB_EVENT_SHUTDOWN,
CTDB_EVENT_RELEASE_IP,
CTDB_EVENT_STOPPED
};
int i;
for (i=0;i<ARRAY_SIZE(allowed_calls);i++) {
if (call == allowed_calls[i]) break;
}
/*集群在恢复状态,不允许执行某些事件,直接报错返回*/
if (i == ARRAY_SIZE(allowed_calls)) {
DEBUG(DEBUG_ERR,("Refusing to run event scripts call '%s' while in recovery\n", ctdb_eventscript_call_names[call]));
talloc_free(state);
return -1;
}
}
/* Kill off any running monitor events to run this event. */
if (ctdb->current_monitor) {
struct ctdb_event_script_state *ms = talloc_get_type(ctdb->current_monitor, struct ctdb_event_script_state);
/* cancel it */
if (ms->callback != NULL) {
ms->callback->fn(ctdb, -ECANCELED, ms->callback->private_data);
talloc_free(ms->callback);
}
/* Discard script status so we don't save to last_status */
talloc_free(ctdb->current_monitor->scripts);
ctdb->current_monitor->scripts = NULL;
talloc_free(ctdb->current_monitor);
ctdb->current_monitor = NULL;
}
DEBUG(DEBUG_INFO,(__location__ " Starting eventscript %s %s\n",
ctdb_eventscript_call_names[state->call],
state->options));
/* This is not a child of state, since we save it in destructor. */
state->scripts = ctdb_get_script_list(ctdb, ctdb);
每个evectscript支持的事件,并不是在任何时候都能运行,比如ctdb cluster 恢复过程中,只能运行某些个事件,因此会有检查,如果有不合法的事件要求执行,会报错:
DEBUG(DEBUG_ERR,("Refusing to run event scripts call '%s' while in recovery\n", ctdb_eventscript_call_names[call]));
talloc_free(state);
return -1;
接下来就要遍历目录下的eventscript,逐个执行了:
/* This is not a child of state, since we save it in destructor. */
state->scripts = ctdb_get_script_list(ctdb, ctdb);
if (state->scripts == NULL) {
talloc_free(state);
return -1;
}
/*current = 0 表示当前正在执行第一个脚本*/
state->current = 0;
state->child = 0;
if (!from_user && (call == CTDB_EVENT_MONITOR || call == CTDB_EVENT_STATUS)) {
ctdb->current_monitor = state;
}
talloc_set_destructor(state, event_script_destructor);
/* Nothing to do? */
if (state->scripts->num_scripts == 0) {
talloc_free(state);
return 0;
}
/*fork创建出来子进程,子进程来执行eventscript
*父子进程的通信也非常有意思,后面会介绍*/
state->scripts->scripts[0].status = fork_child_for_script(ctdb, state);
if (state->scripts->scripts[0].status != 0) {
/* Callback is called from destructor, with fail result. */
talloc_free(state);
return 0;
}
if (!timeval_is_zero(&state->timeout)) {
event_add_timed(ctdb->ev, state, timeval_current_ofs(state->timeout.tv_sec, state->timeout.tv_usec), ctdb_event_script_timeout, state);
} else {
DEBUG(DEBUG_ERR, (__location__ " eventscript %s %s called with no timeout\n",
ctdb_eventscript_call_names[state->call],
state->options));
}
return 0;
}
这里面的精华是父子进程的通信,和如何串行发起下一个脚本的执行,直至最终完成所有脚本。
代码中这一行用的是:state->scripts->scripts[0].status ,从我的角度看,0改成state->current 会更妙一些,会更容易帮助读者理解源码。我们继续分析fork_child_for_script。
state->scripts->scripts[0].status = fork_child_for_script(ctdb, state);
fork_child_for_script 顾名思义就是创建子进程来执行某一个script,用子进程来执行的好处是,父进程不会阻塞,父进程只需要安心地等待子进程传过来的消息即可。
static int fork_child_for_script(struct ctdb_context *ctdb,
struct ctdb_event_script_state *state)
{
int r;
struct tevent_fd *fde;
struct ctdb_script_wire *current = get_current_script(state);
current->start = timeval_current();
/*创建管道,子进程负责写入,父进程负责读取
*管道的作用是,子进程执行完毕后,将返回值写入管道
*父进程只需要从管道中读取,就可以获得子进程的执行返回值*/
r = pipe(state->fd);
if (r != 0) {
DEBUG(DEBUG_ERR, (__location__ " pipe failed for child eventscript process\n"));
return -errno;
}
if (!ctdb_fork_with_logging(state, ctdb, current->name, log_event_script_output,
state, &state->child)) {
r = -errno;
close(state->fd[0]);
close(state->fd[1]);
return r;
}
/* If we are the child, do the work. */
if (state->child == 0) {
int rt;
debug_extra = talloc_asprintf(NULL, "eventscript-%s-%s:",
current->name,
ctdb_eventscript_call_names[state->call]);
/*子进程关闭读取端*/
close(state->fd[0]);
set_close_on_exec(state->fd[1]);
rt = child_run_script(ctdb, state->from_user, state->call, state->options, current);
/* We must be able to write PIPEBUF bytes at least; if this
somehow fails, the read above will be short. */
/*子进程将执行结果的返回值 rt写入管道,告知父进程*/
write(state->fd[1], &rt, sizeof(rt));
close(state->fd[1]);
_exit(rt);
}
close(state->fd[1]);
set_close_on_exec(state->fd[0]);
DEBUG(DEBUG_DEBUG, (__location__ " Created PIPE FD:%d to child eventscript process\n", state->fd[0]));
/* Set ourselves up to be called when that's done. */
/*父进程会添加监控文件描述符,当子进程写入管道时,父进程就会收到,并执行预设的函数
*即ctdb_event_script_handler*/
fde = event_add_fd(ctdb->ev, state, state->fd[0], EVENT_FD_READ,
ctdb_event_script_handler, state);
tevent_fd_set_auto_close(fde);
return 0;
}
函数首先是创建了管道,父进程负责读取,子进程负责写入,各关闭一端。当子进程执行完毕后,会往管道中写入结果,而父进程会注册监控事件,收到子进程的消息后,执行预设的ctdb_event_script_handler函数。
我们一起走入ctdb_event_script_handler函数一探究竟:
/* called when child is finished */
static void ctdb_event_script_handler(struct event_context *ev, struct fd_event *fde, uint16_t flags, void *p)
{
struct ctdb_event_script_state *state =
talloc_get_type(p, struct ctdb_event_script_state);
struct ctdb_script_wire *current = get_current_script(state);
struct ctdb_context *ctdb = state->ctdb;
int r, status;
if (ctdb == NULL) {
DEBUG(DEBUG_ERR,("Eventscript finished but ctdb is NULL\n"));
return;
}
/*从管道中读取返回值,写入curren->status*/
r = read(state->fd[0], ¤t->status, sizeof(current->status));
if (r < 0) {
current->status = -errno;
} else if (r != sizeof(current->status)) {
current->status = -EIO;
}
current->finished = timeval_current();
/* valgrind gets overloaded if we run next script as it's still doing
* post-execution analysis, so kill finished child here. */
if (ctdb->valgrinding) {
kill(state->child, SIGKILL);
}
status = script_status(state->scripts);
/* Aborted or finished all scripts? We're done. */
/*如果放弃,或者说当前执行的脚本,已经是最后一个了,那么打印执行完毕所有脚本,并返回*/
if (status != 0 || state->current+1 == state->scripts->num_scripts) {
DEBUG(DEBUG_INFO,(__location__ " Eventscript %s %s finished with state %d\n",
ctdb_eventscript_call_names[state->call], state->options, status));
ctdb->event_script_timeouts = 0;
talloc_free(state);
return;
}
/* Forget about that old fd. */
talloc_free(fde);
/* Next script! */
/*上一个脚本已经执行完毕,执行下一个*/
state->current++;
current++;
current->status = fork_child_for_script(ctdb, state);
if (current->status != 0) {
/* This calls the callback. */
talloc_free(state);
}
}
注意,执行下一个脚本,执行的也是fork_child_for_scirpt,那么这个函数到底如何确定还行哪一个函数呢?玄机就在state 参数内。state中有一个变量叫做current,记录本轮应该执行第几个脚本。我们再次回到
struct ctdb_script_wire {
/*脚本的名字*/
char name[MAX_SCRIPT_NAME+1];
/*执行的开始时间和结束时间*/
struct timeval start;
struct timeval finished;
/*该脚本的执行返回值*/
int32_t status;
char output[MAX_SCRIPT_OUTPUT+1];
};
static
struct ctdb_script_wire *get_current_script(struct ctdb_event_script_state *state)
{
return &state->scripts->scripts[state->current];
}
static int fork_child_for_script(struct ctdb_context *ctdb,
struct ctdb_event_script_state *state)
{
int r;
struct tevent_fd *fde;
struct ctdb_script_wire *current = get_current_script(state);
通过current的值,该函数能找到该执行哪个函数。