前言
本文解决Where is my data 之对象存储部分,主要集中在S3对象存储。
where is my s3 data
简略地回答,可以说,用户的s3 data存放在 .rgw.buckets这个pool中,可是,pool中的数据长这个样:
default.11383165.1_kern.log
....
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_53
default.11383165.1_821
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_260
default.11383165.1_5
default.11383165.1_572
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_618
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_153
default.11383165.1_217
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_537
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_357
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_565
default.11383165.1_441
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_223
如何和bucket对应,如何和bucket中的用户对象文件对应?
整体上传对象
整体上传对象的时候,分成两种情况,区分的维度就是:
"rgw_max_chunk_size": "524288"
这个值是RadosGW下发到RADOS集群的单个IO的大小,同时也决定了应用对象分成多个RADOS对象时首对象(head_obj)的大小。
- 对象大小分块大小,即小于512KB
- 对象大小大于分块大小,即大于512KB
注意,如果大于rgw_max_chunk_size的对象文件,后续部分会根据如下参数切成多个RADOS对象:
"rgw_obj_stripe_size": "4194304"
也就说,小于512K的对象文件在底层RADOS 只有一个对象,大于512KB的对象文件,会分成多个对象存储,其中第一个对象叫做首对象,大小为rgw_max_chunk_size,其他的对象按照rgw_obj_stripe_size切成不同的object 存入rados。
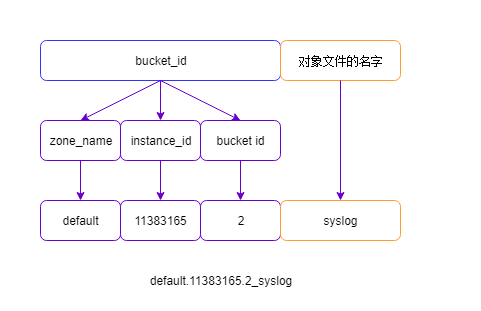
小于rgw_max_chunk_size的对象文件
这种情况就比较简单了,即将bucket_id 和 对象文件的名字用下划线拼接,作为pool中底层对象的名字。
root@44:~# s3cmd pub /var/log/syslog s3://bean_book/syslog
ERROR: Invalid command: u'pub'
root@44:~# s3cmd put /var/log/syslog s3://bean_book/syslog
/var/log/syslog -> s3://bean_book/syslog [1 of 1]
60600 of 60600 100% in 0s 8.56 MB/s done
root@44:~# rados -p .rgw.buckets ls |grep syslog
default.11383165.2_syslog
root@44:/# rados -p .rgw.buckets stat default.11383165.2_syslog
.rgw.buckets/default.11383165.2_syslog mtime 2018-05-27 14:51:14.000000, size 60600
大于rgw_max_chunk_size对象文件
对于大于rgw_max_chunk_size的对象文件,会分成多个底层RADOS对象存放。
root@44:~# s3cmd put VirtualStor\ Scaler-v6.3-319~201805240311~cda7fd7.iso s3://bean_book/scaler.iso
上传完毕之后,我们可以从.rgw.buckets桶里面找到如下对象:
default.11383165.2_scaler.iso
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_208
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_221
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_76
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_293
用户上传对象文件的时候,被分解成
- 大小等于rgw_max_chunk_size的首对象 head_obj (512KB)
- 多个大小等于条带大小的中间对象
- 一个小于或者等于条带大小的尾对象
对于head_obj的命名组成,和上面一样,我就不重复绘图了,对于中间的对象和最后的尾对象,命名组成如下:
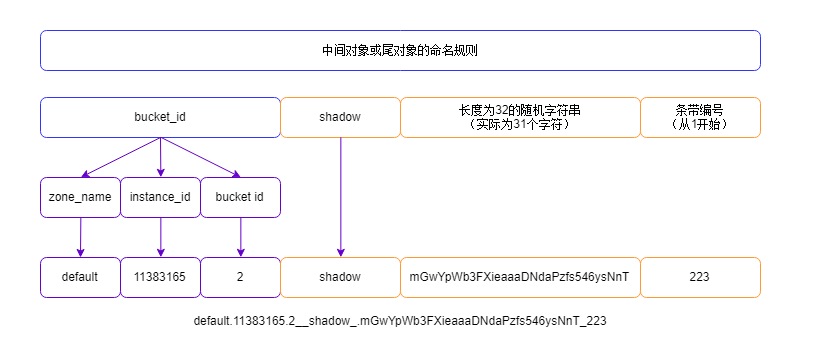
这里面有个问题,因为对象名字中有随机字符,当然只有一个大于4M的对象文件的时候,比如我就上传了一2G+的大文件,所有的bucket内的带shadow的文件都属于这个scaler.iso 对象。
但是我们想想,如果bucket中很多这种2G+的大对象文件,我们如何区分
root@44:/var/log/ceph# rados -p .rgw.buckets ls |grep shadow |grep "_1$"
default.11383165.2__shadow_.3vU63olQg1ovOpVdWQxJsx2o28N3TFl_1
default.11383165.2__shadow_.iDlJATXiRQBiT9xxSX5qS_Rb8iFdHam_1
default.11383165.2__shadow_.ipsp4zhQCPa1ckNNQZaJeLRSq3miyhR_1
default.11383165.2__shadow_.JKq4eXO5IJ6BMANVmLluwcUVHH7wzW9_1
default.11383165.2__shadow_.C7e7w4gQLapZ_KK3c2_2pKcz-yIobaN_1
default.11383165.2__shadow_.mGwYpWb3FXieaaaDNdaPzfs546ysNnT_1
default.11383165.2__shadow_.OvUkm8069EUeyXHneWhd4JOiVPev3gI_1
default.11383165.2__shadow_.zNsCV2xYKlym7uLDkR7cV0SF3edH0t3_1
换句话说,head_obj可以和对象文件关联起来,但是这些中间对象和尾对象,如何和head_obj关联起来呢?
head_obj不一般,它需要维护对象文件元数据信息和manifest信息:
root@44:~# rados -p .rgw.buckets listxattr default.11383165.2_scaler.iso
user.rgw.acl
user.rgw.content_type
user.rgw.etag
user.rgw.idtag
user.rgw.manifest
user.rgw.x-amz-date
其中对于寻找数据比较重要的数据结构为:
rados -p .rgw.buckets getxattr default.11383165.2_scaler.iso user.rgw.manifest > /root/scaler.iso.manifest
root@44:~# ceph-dencoder type RGWObjManifest import /root/scaler.iso.manifest decode dump_json
{
"objs": [],
"obj_size": 2842374144, <-----------------对象文件大小
"explicit_objs": "false",
"head_obj": {
"bucket": {
"name": "bean_book",
"pool": ".rgw.buckets",
"data_extra_pool": ".rgw.buckets.extra",
"index_pool": ".rgw.buckets.index",
"marker": "default.11383165.2",
"bucket_id": "default.11383165.2"
},
"key": "",
"ns": "",
"object": "scaler.iso", <---------------------对象名
"instance": ""
},
"head_size": 524288,
"max_head_size": 524288,
"prefix": ".mGwYpWb3FXieaaaDNdaPzfs546ysNnT_", <------------------中间对象和尾对象的随机前缀
"tail_bucket": {
"name": "bean_book",
"pool": ".rgw.buckets",
"data_extra_pool": ".rgw.buckets.extra",
"index_pool": ".rgw.buckets.index",
"marker": "default.11383165.2",
"bucket_id": "default.11383165.2"
},
"rules": [
{
"key": 0,
"val": {
"start_part_num": 0,
"start_ofs": 524288,
"part_size": 0,
"stripe_max_size": 4194304,
"override_prefix": ""
}
}
]
}
有了head size 以及strip size这些,还有前缀,就可以很轻松的组成中间对象和尾对象的名字,进而读取对象文件的不同部分了。
寻找数据结束了之后,我们可以关注下其他的元数据信息:
root@44:~# rados -p .rgw.buckets getxattr default.11383165.2_scaler.iso user.rgw.etag -
9df9be75a165539894ef584cd27cc39f
root@44:~# md5sum VirtualStor\ Scaler-v6.3-319~201805240311~cda7fd7.iso
9df9be75a165539894ef584cd27cc39f VirtualStor Scaler-v6.3-319~201805240311~cda7fd7.iso
对于非分片上传的对象文件而言,etag就是MD5,几乎在对象文件 head_obj的扩展属性中。
对象文件的ACL信息,也记录在head_obj的扩展属性中:
root@44:~# rados -p .rgw.buckets getxattr default.11383165.2_scaler.iso user.rgw.acl > scaler.iso.acl
root@44:~# ceph-dencoder type RGWAccessControlPolicy import scaler.iso.acl decode dump_json
{
"acl": {
"acl_user_map": [
{
"user": "bean_li",
"acl": 15
}
],
"acl_group_map": [],
"grant_map": [
{
"id": "bean_li",
"grant": {
"type": {
"type": 0
},
"id": "bean_li",
"email": "",
"permission": {
"flags": 15
},
"name": "bean_li",
"group": 0
}
}
]
},
"owner": {
"id": "bean_li",
"display_name": "bean_li"
}
}
除了这些默认的扩展属性,用户指定的metadata也是存放在此处。
分片上传 multipart upload
分片上传的对象,数据如何存放?
root@44:~# cp VirtualStor\ Scaler-v6.3-319~201805240311~cda7fd7.iso /var/share/ezfs/shareroot/NAS/scaler_iso
root@44:~#
root@44:~# s3cmd mb s3://iso
Bucket 's3://iso/' created
使用分片上传,每10M一个分片:
上传上去的对象有如下的命名风格:
default.14434697.1_scaler_iso
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.187_2
default.14434697.1__multipart_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.129_2
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.134_2
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.22_1
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.83_2
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.136_2
head_obj不说了,还是老的命名风格,和完整上传的区别是,size 为0
root@45:/var/log/radosgw# rados -p .rgw.buckets stat default.14434697.1_scaler_iso
.rgw.buckets/default.14434697.1_scaler_iso mtime 2018-05-27 18:48:32.000000, size 0
注意上面名字中的2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH,最容易让你困扰的是2~,这个2~是upload_id的前缀。
#define MULTIPART_UPLOAD_ID_PREFIX_LEGACY "2/"
#define MULTIPART_UPLOAD_ID_PREFIX "2~" // must contain a unique char that may not come up in gen_rand_alpha()
命名规则如下:
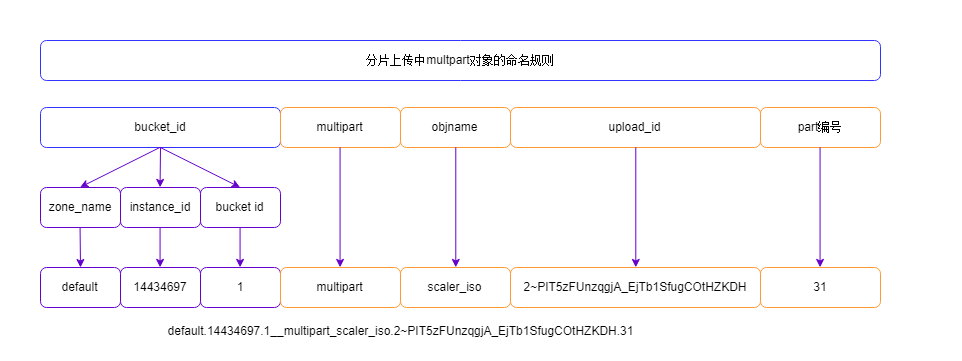
需要注意的是,RADOS中multipart对象就是普通的rgw_obj_stripe_size ,即4M大小:
root@45:/var/log/radosgw# rados -p .rgw.buckets stat default.14434697.1__multipart_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31
.rgw.buckets/default.14434697.1__multipart_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31 mtime 2018-05-27 18:48:10.000000, size 4194304
但是注意,应用程序分片,是用户可以指定的,比如我们的RRS,10M分片:
obsync.py
-----------------
MULTIPART_THRESH = 10485760
mpu = self.bucket.initiate_multipart_upload(obj.name, metadata=meta_to_dict(obj.meta))
try:
remaining = obj.size
part_num = 0
part_size = MULTIPART_THRESH
while remaining > 0:
offset = part_num * part_size
length = min(remaining, part_size)
ioctx = src.get_obj_ioctx(obj, offset, length)
mpu.upload_part_from_file(ioctx, part_num + 1)
remaining -= length
part_num += 1
mpu.complete_upload()
except Exception as e:
mpu.cancel_upload()
raise e
很明显,单个multipart 对象不足以存放10M大小,因此,一般对应分片还有对应的shadow对象:
root@45:/var/log/radosgw# rados -p .rgw.buckets ls |grep "2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31"
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31_1
default.14434697.1__multipart_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31
default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31_2
root@45:/var/log/radosgw# rados -p .rgw.buckets stat default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31_1
.rgw.buckets/default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31_1 mtime 2018-05-27 18:48:10.000000, size 4194304
root@45:/var/log/radosgw# rados -p .rgw.buckets stat default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31_2
.rgw.buckets/default.14434697.1__shadow_scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH.31_2 mtime 2018-05-27 18:48:10.000000, size 2097152
毫无意外,两个shadow 1个4M,另一个2M,加上分片的multipart 对象,共10M。
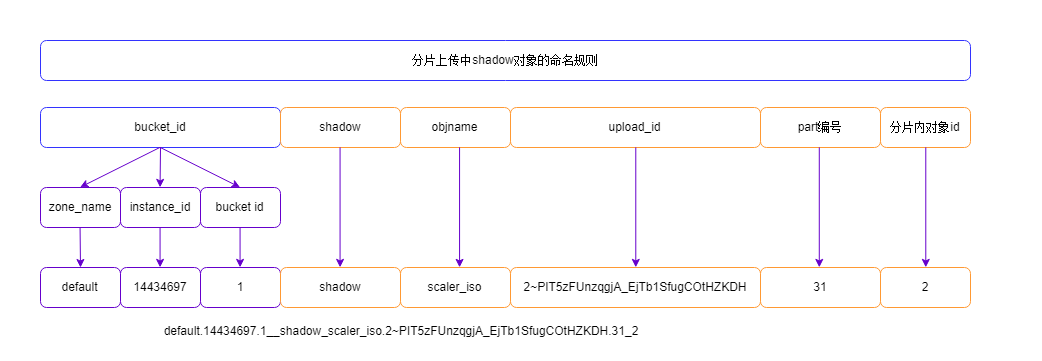
同样的问题是,用户读对象的时候,根据上传 时候的情况,决定了数据对象的名字,那么如何区分是分片上传的对象还是完整上传的对象呢?
root@45:~# rados -p .rgw.buckets getxattr default.14434697.1_scaler_iso user.rgw.manifest > scaler_iso_multipart.manifest
root@45:~# ceph-dencoder type RGWObjManifest import /root/scaler_iso_multipart.manifest decode dump_json
{
"objs": [],
"obj_size": 2842374144,
"explicit_objs": "false",
"head_obj": {
"bucket": {
"name": "iso",
"pool": ".rgw.buckets",
"data_extra_pool": ".rgw.buckets.extra",
"index_pool": ".rgw.buckets.index",
"marker": "default.14434697.1",
"bucket_id": "default.14434697.1"
},
"key": "",
"ns": "",
"object": "scaler_iso",
"instance": ""
},
"head_size": 0,
"max_head_size": 0,
"prefix": "scaler_iso.2~PIT5zFUnzqgjA_EjTb1SfugCOtHZKDH",
"tail_bucket": {
"name": "iso",
"pool": ".rgw.buckets",
"data_extra_pool": ".rgw.buckets.extra",
"index_pool": ".rgw.buckets.index",
"marker": "default.14434697.1",
"bucket_id": "default.14434697.1"
},
"rules": [
{
"key": 0,
"val": {
"start_part_num": 1,
"start_ofs": 0,
"part_size": 10485760,
"stripe_max_size": 4194304,
"override_prefix": ""
}
},
{
"key": 2841640960,
"val": {
"start_part_num": 272,
"start_ofs": 2841640960,
"part_size": 733184,
"stripe_max_size": 4194304,
"override_prefix": ""
}
}
]
}