引言
SSTable文件是落在磁盘上的真正文件,leveldb存储路径中的.sst 类型的文件都是SSTable文件。 本文介绍该文件的格式,以及leveldb如何一条记录一条记录的增加到SSTable文件。
首先要注意,SSTable文件里面存放的是大量的key-value,因为leveldb就是一个key-value DB。我们都买过字典,如果把字典的每一个字当成key,对字的解释当成value,字典就是一个key-value DB。
在收录几千上万个字的字典中,如何快速寻找到茴香的茴字?
字典第一个思想是有序,按照一定的顺序收录,如果无序,杂乱无章地收录key-value就会给检索带来麻烦。
字典的第二个思想是目录,本质是索引,茴读作Hui,因此,在字典中有如下的格式
A ...............................................................页码
B ...............................................................页码
C ...............................................................页码
D ...............................................................页码
E ...............................................................页码
F ...............................................................页码
H
|____ a ...............................................................页码
|____ .. ...............................................................页码
|____ u
|____ a ...............................................................页码
|____ .. ...............................................................页码
|____ i ...............................................................页码
...
这两种思想在leveldb中都有体现,但是leveldb的挑战要大于组织一个字典。首先字典的是死的,一旦字典组织好,字典不会发生变动,既不会增加新的内容,也不会删除某一个字,leveldb则不同,leveldb是动态变化的,你无法预测用户会插入多少笔key-value的记录,用户可能修改某条key-value对,也可能删除某条记录。
另外一个难点是字可以穷尽,但是key-value中的key无法穷举。
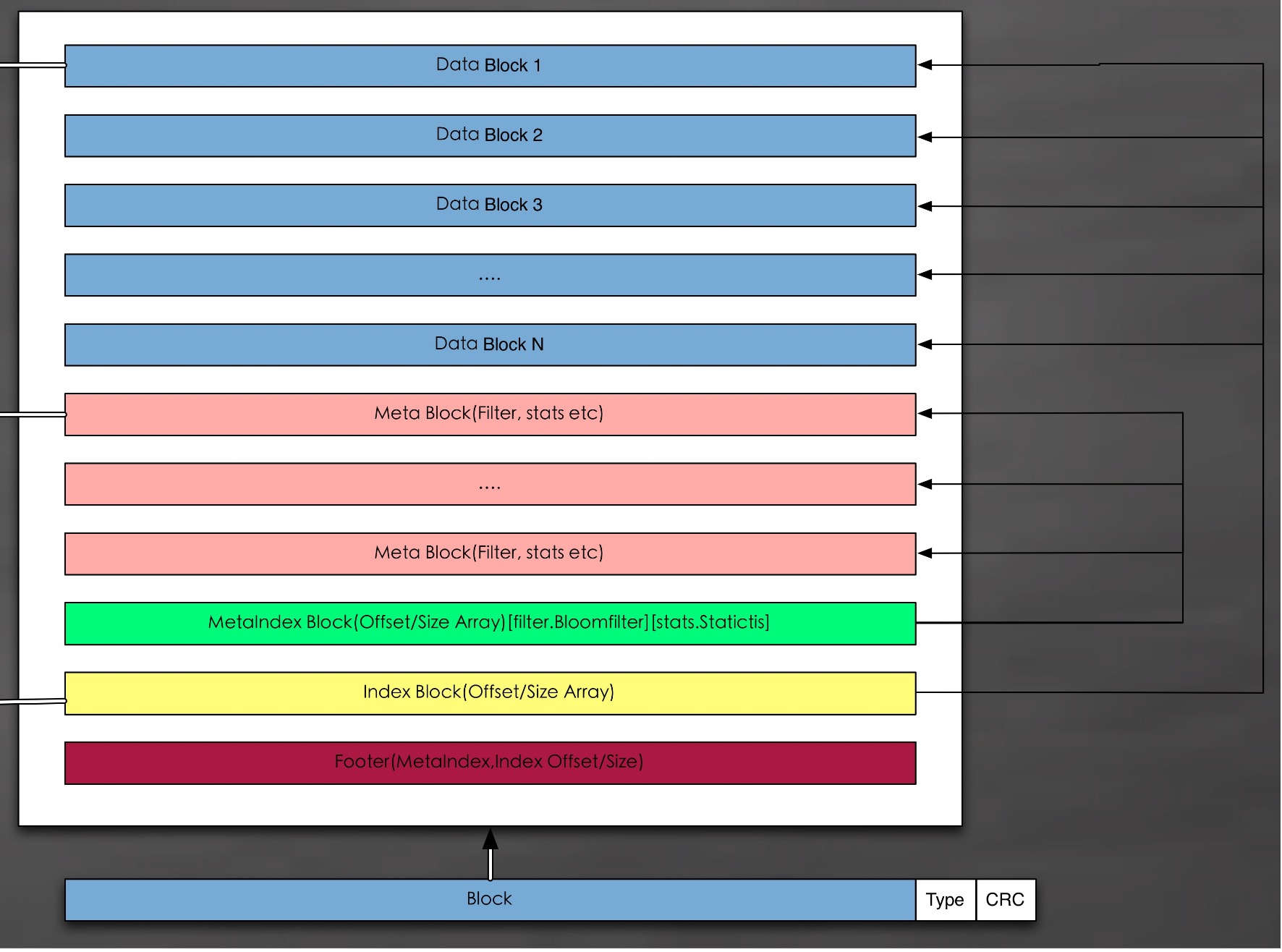
SSTable的layout
在doc/table_format.txt中如右下图:
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1]
...
[meta block K]
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
如下图所示:

首先SSTtable文件不是固定长度的,从上图中也可以看出,文件的内容要能够自解释,就需要有在固定位置有一定数据结构,顺藤摸瓜,理顺文件的内容。
对于leveldb而言,Footer是线头,从Footer开始就可以找到该文件的其他组成部分如index block和metaindex block,进而解释整个文件的内容。
Footer的长度是固定的,因此对于SSTable文件的最后 sizeof(Footer)字节就是存放的Footer信息。 Footer固定48B,如下图所示:
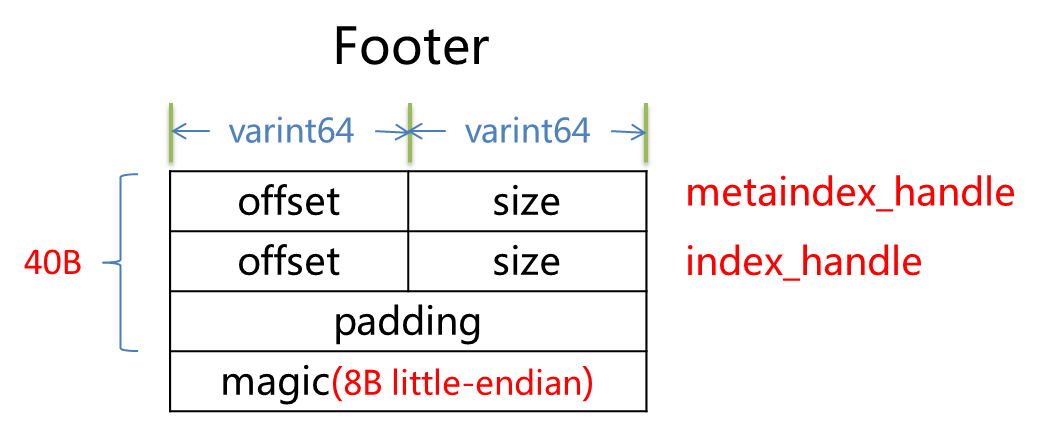
metaindex_handle: char[p]; // Block handle for metaindex
index_handle: char[q]; // Block handle for index
padding: char[40-p-q]; // zeroed bytes to make fixed length
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // == 0xdb4775248b80fb57 (little-endian)
其中最后的magic number是固定的长度的8字节:
static const uint64_t kTableMagicNumber = 0xdb4775248b80fb57ull;
为了文件的自解释,内部必须要有指针指向文件的其他位置来表示某个section的开始和结束位置。负责记录这个的变量叫做BlockHandle,他有两个成员变量offset_ 和 size_,分别记录的某个数据块的起始位置和长度。
class BlockHandle {
private:
uint64_t offset_;
uint64_t size_;
};
一个uint64整数经过varint64编码后最大占用10个字节,一个BlockHandle包含两个uint64类型(size和offset),则一个BlockHandle最多占用20个字节,即BLockHandle::kMaxEncodedLength=20。metaindex_handle和index_handle最大占用字节为40个字节。magic number占用8个字节,是个固定数值,用于读取时校验是否跟填充时相同,不相同的话就表示此文件不是一个SSTable文件(bad magic number)。padding用于补齐为40字节。
sstable文件中footer中可以解码出在文件的结尾处距离footer最近的index block的BlockHandle,以及metaindex block的BlockHandle,从而确定这两个组成部分在文件中的位置。
事实上,在table/table_build.cc中的Status TableBuilder::Finish()函数,我们可以看出,当生成sstable文件的时候,各个组成部分的写入顺序:
Status TableBuilder::Finish() {
Rep* r = rep_;
Flush(); /*写入尚未Flush的Block块*/
assert(!r->closed);
r->closed = true;
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// 写入filter_block块,即图中的meta block
if (ok() && r->filter_block != NULL) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
// 写入metaindex block
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != NULL) {
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
// 写入index block
if (ok()) {
if (r->pending_index_entry) {
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
// 写入footer, footer为固定长度,在文件的最尾部
if (ok()) {
Footer footer;
//将metaindex block在文件中的位置信息记录在footer
footer.set_metaindex_handle(metaindex_block_handle);
//将index block在sstabke文件中的位置信息记录在footer
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
return r->status;
}
从Finish函数也可以看出,各个部分在文件中的位置即是上图所绘制的那样。
index block, metaindex block , filter block(图中的meta block),甚至最终的data block,这些block都是干啥用的,数据又是怎么组织的呢?
- Data Blocks: 存储一系列有序的key-value
- Meta Block:存储key-value对应的filter(默认为bloom filter)
- metaindex block: 指向Meta Block的索引
- Index BLocks: 指向Data Blocks的索引
- Footer : 指向索引的索引
它们之间的关系如下图所示,后面会详细介绍这些部分的关系和存在的作用。
Data Block
最容易理解的应该是Data Block,存放的就是一系列有序的key-value,为了节省存储空间,Data block做了一些改进。
初次阅读代码,或者看示意图,很容易产生的误解是 Data Block是定长的,这种理解是错误的,实际上data block是变长的。
"block_size" is not a "size", it is a threshold. Data is never split
across blocks. A single block contains one or more key/value pairs.
leveldb starts a new block only when the total size of all key/values in
the current block exceed the threshold.
只不过它总是在写满options.block_size的时候开始Flush,追加写入到sstable file,如table/table_build.cc中的
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
...
r->data_block.Add(key, value);
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
而这个options.block_size默认为4KB。
注意,很多key可能有重复的字节,比如“hellokitty”和”helloworld“是两个相邻的key,由于key中有公共的部分“hello”,因此,如果将公共的部分提取,可以有效的节省存储空间。
处于这种考虑,LevelDb采用了前缀压缩(prefix-compressed),由于LevelDb中key是按序排列的,这可以显著的减少空间占用。另外,每间隔16个keys(目前版本中options_->block_restart_interval默认为16),LevelDb就取消使用前缀压缩,而是存储整个key(我们把存储整个key的点叫做重启点)。

向sstable添加一个key-value,函数的入口点是:
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
assert(!r->closed);
if (!ok()) return;
if (r->num_entries > 0) {
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
/*此处我们先忽略index block的部分*/
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
/*此处我们先忽略filter block的部分*/
if (r->filter_block != NULL) {
r->filter_block->AddKey(key);
}
r->last_key.assign(key.data(), key.size());
r->num_entries++;
/* 向data block中添加一组key-value pair */
r->data_block.Add(key, value);
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
我们先忽略index block和filter block的部分,集中精力查看data block如何新增key-value对:
void BlockBuilder::Add(const Slice& key, const Slice& value) {
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() // No values yet?
|| options_->comparator->Compare(key, last_key_piece) > 0);
size_t shared = 0;
if (counter_ < options_->block_restart_interval) {
// See how much sharing to do with previous string
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
} else {
// Restart compression
/*新的重启点,记录下位置*/
restarts_.push_back(buffer_.size());
counter_ = 0;
}
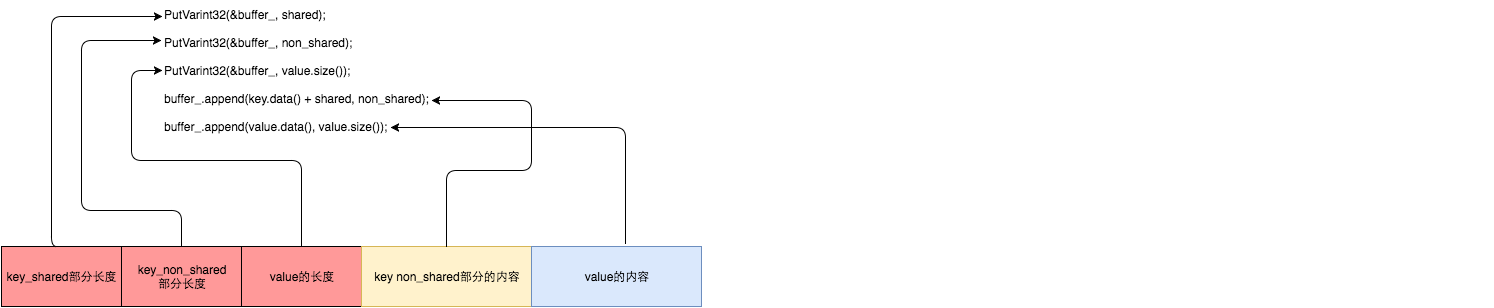
const size_t non_shared = key.size() - shared;
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
对于data block中的每一个记录,其格式如下:
当当前data_block中的内容足够多,预计大于预设的门限值的时候,就开始flush,所谓data block的Flush就是将所有的重启点指针记录下来,并且记录重启点的个数:
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}
至此,介绍完了SSTable文件中的data block。
注意,一个SSTable中存在着多个data block,尽管他们之间是有序的,可是你查找的key到底位于哪个block上?典型的sstable文件大小为2M,可以设置的更大,每个sstable 文件中data block 的个数可能上百,如何在这上百个data block中寻找你要的key?
显然依次查找效率太低,这时候 index block就起到作用了。下篇继续介绍。