前言
前面讲了SSTable文件,这种文件是leveldb的最终形态,在该文件中,key-value是有序的,它位于磁盘上。很明显客户输入的key-value对的顺序是不可预知的,是无序,因此SSTable肯定不是直接对应用户的put key-value操作。
直接应对客户put操作的数据结构是MemTable,它是一个存在在内存中的数据结构,内部也是有序的,使用SkipList来组织用户输入的key-value对。(为了防范异常掉电,所以引入了log文件)。
这里面就存在一个问题了,用户的输入的数据暂时记录在MemTable,而最终落在磁盘上的是SSTable文件。那问题就来了:
- 怎么将内存中的SkipList组织的MemTable中的数据dump到SSTable file,
- 什么时机做这个dump 操作。
这就牵扯到LevelDB中很重要的一个概念,Compaction
LevelDB中,Compaction分成两种:
- minor compaction
- major compaction
就如同Linux操作系统中的page fault分成minor和major一样。本文介绍minor compaction。Minor Compaction牵扯到讲MemTable中的key-value对 dump到SSTable 文件。在合适的时机,将Immutable MemTable dump到磁盘,形成SSTable。
无论是哪一种Compaction,入口点都是:
DBImpl::MaybeScheduleCompaction()
Compaction 整体流程
Compaction操作入口实际由DBImpl::MaybeScheduleCompaction控制,追踪该函数的调用场景,就可以知道,触发Compaction的时机。 我们首先介绍Minor Compaction的触发时机:
以下几个条件同时满足时,才会触发Minor Compaction:
- 在调用put/delete API时,检查DBImpl::MakeRoomForWrite, 发现memtable的使用空间超过4M了;
- 当前的immtable已经被dump出去成sstable. 也就是immtable=NULL 在上面的两个条件同时满足的情况下,会阻塞写线程,把memtable移到immtable。然后新起一个memtable,让写操作写到这个memtable里。最后将imm放到后台线程去做compaction.
(触发Compaction的时机,我打算用另外一篇来详细讲述,此处按下不表。)
void DBImpl::MaybeScheduleCompaction() {
mutex_.AssertHeld();
if (bg_compaction_scheduled_) {
// Already scheduled
} else if (shutting_down_.Acquire_Load()) {
// DB is being deleted; no more background compactions
} else if (!bg_error_.ok()) {
// Already got an error; no more changes
} else if (imm_ == NULL &&
manual_compaction_ == NULL &&
!versions_->NeedsCompaction()) {
/*防止无限递归,会判断需不需要再次Compaction,如果不需要就返回了*/
// No work to be done
} else {
bg_compaction_scheduled_ = true;
env_->Schedule(&DBImpl::BGWork, this);
}
}
void DBImpl::BGWork(void* db) {
reinterpret_cast<DBImpl*>(db)->BackgroundCall();
}
void DBImpl::BackgroundCall() {
MutexLock l(&mutex_);
assert(bg_compaction_scheduled_);
if (shutting_down_.Acquire_Load()) {
// No more background work when shutting down.
} else if (!bg_error_.ok()) {
// No more background work after a background error.
} else {
/*函数之眼,关键部分即BackgroundCompaction*/
BackgroundCompaction();
}
bg_compaction_scheduled_ = false;
// Previous compaction may have produced too many files in a level,
// so reschedule another compaction if needed.
MaybeScheduleCompaction();
bg_cv_.SignalAll();
}
整体流程如下所示:

从表面看,这是一个无限递归啊,从MaybeScheduleCompaction进入,但是后面调用的函数再次调用了MaybeScheduleCompaction函数。
不会递归,在void DBImpl::MaybeScheduleCompaction()中有如下判断:
void DBImpl::MaybeScheduleCompaction()
{
else if (imm_ == NULL &&
manual_compaction_ == NULL &&
!versions_->NeedsCompaction()) {
/*防止无限递归,会判断需不需要再次Compaction,如果不需要就返回了*/
// No work to be done
}
}
注意上面的的条件:
- imm_ == NULL表示没有Immutable MemTable需要dump成SST
- manual_compaction_ == NULL 表示不是手动调用DBImpl::CompactRange,人工触发
- versions_->NeedsCompaction 来 判断是是否需要进一步发起Compaction
看BackGroundCall函数中的注释:
// Previous compaction may have produced too many files in a level,
// so reschedule another compaction if needed.
第一轮的Compaction可能会产生出很多files,需要再次发起一轮Compaction,需不需要就靠versions_->NeedsCompaction函数来判断。
现在我们进入真正Compaction的函数: BackgroundCompaction
BackgroundCompaction 之 Minor Compaction
BackGroundCompaction函数很长,是个很长的故事,我们不贪多,直讲Minor Compaction,即如何讲Immutable Memtable dump成SSTable 文件:
void DBImpl::BackgroundCompaction() {
mutex_.AssertHeld();
if (imm_ != NULL) {
CompactMemTable();
return;
}
...
}
CompactMemTable这个函数顾名思义啊,就是将内存中的MemTable dump到磁盘上,形成SSTable文件,但是切莫欢喜太早,该函数并不简单:
void DBImpl::CompactMemTable() {
mutex_.AssertHeld();
assert(imm_ != NULL);
// Save the contents of the memtable as a new Table
VersionEdit edit;
Version* base = versions_->current();
base->Ref();
Status s = WriteLevel0Table(imm_, &edit, base);
base->Unref();
if (s.ok() && shutting_down_.Acquire_Load()) {
s = Status::IOError("Deleting DB during memtable compaction");
}
// Replace immutable memtable with the generated Table
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
s = versions_->LogAndApply(&edit, &mutex_);
}
if (s.ok()) {
// Commit to the new state
imm_->Unref();
imm_ = NULL;
has_imm_.Release_Store(NULL);
DeleteObsoleteFiles();
} else {
RecordBackgroundError(s);
}
}
minor compaction的调用流程图如下:

WriteLevel0Table
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit,
Version* base) {
mutex_.AssertHeld();
const uint64_t start_micros = env_->NowMicros();
FileMetaData meta;
meta.number = versions_->NewFileNumber();
pending_outputs_.insert(meta.number);
Iterator* iter = mem->NewIterator();
Log(options_.info_log, "Level-0 table #%llu: started",
(unsigned long long) meta.number);
Status s;
{
mutex_.Unlock();
s = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
mutex_.Lock();
}
Log(options_.info_log, "Level-0 table #%llu: %lld bytes %s",
(unsigned long long) meta.number,
(unsigned long long) meta.file_size,
s.ToString().c_str());
delete iter;
pending_outputs_.erase(meta.number);
// Note that if file_size is zero, the file has been deleted and
// should not be added to the manifest.
int level = 0;
if (s.ok() && meta.file_size > 0) {
const Slice min_user_key = meta.smallest.user_key();
const Slice max_user_key = meta.largest.user_key();
if (base != NULL) {
level = base->PickLevelForMemTableOutput(min_user_key, max_user_key);
}
edit->AddFile(level, meta.number, meta.file_size,
meta.smallest, meta.largest);
}
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros;
stats.bytes_written = meta.file_size;
stats_[level].Add(stats);
return s;
}
这个函数主要有三个部分,如上面流程图所示,最重要的是BuildTable来讲Immutale MemTable中的内容写入到SSTable。 SSTable的命名是有规范的:
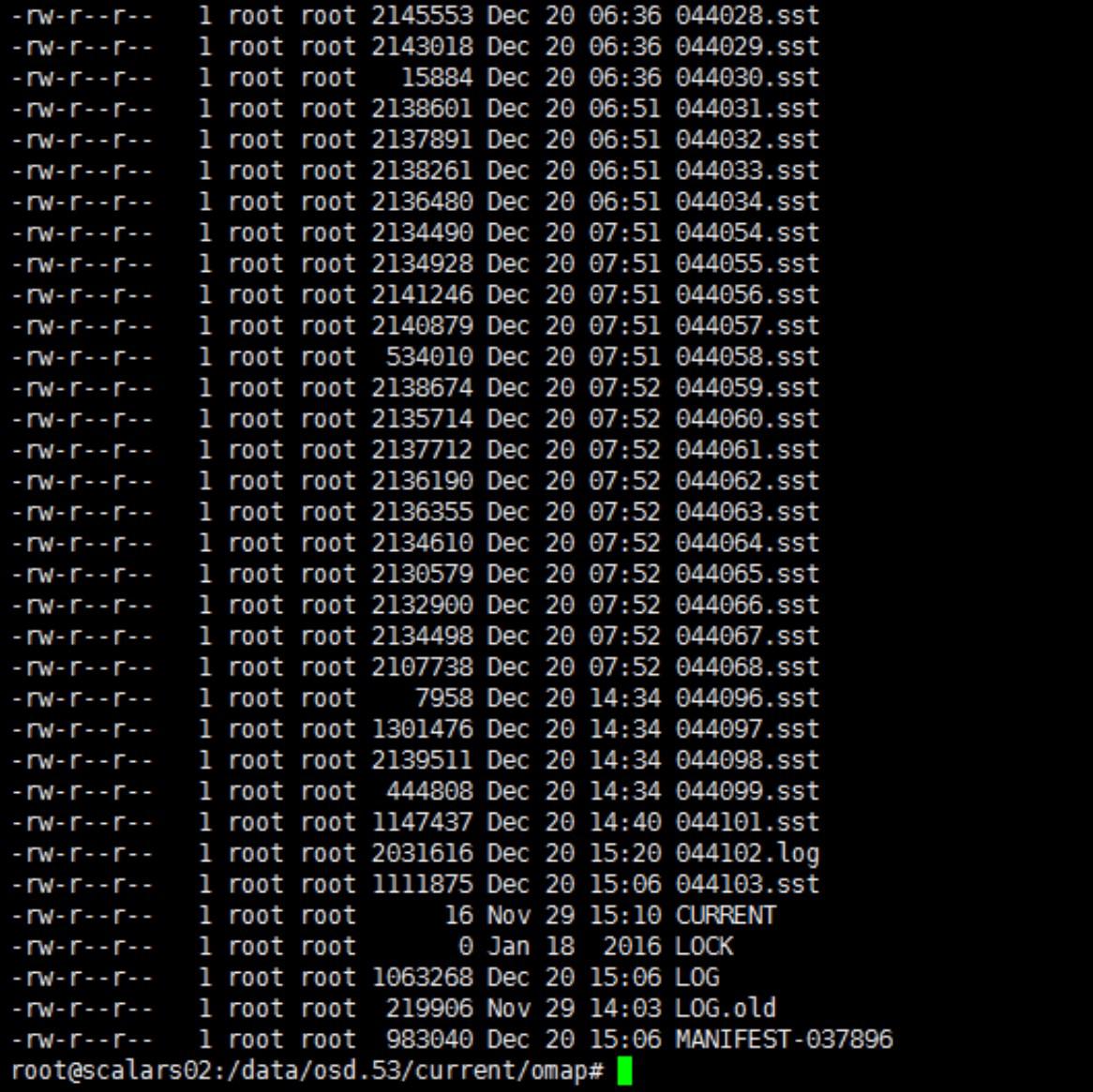
这个数字是有VersionSet分配的:
meta.number = versions_->NewFileNumber();
class VersionSet {
public:
VersionSet(const std::string& dbname,
const Options* options,
TableCache* table_cache,
const InternalKeyComparator*);
~VersionSet();
...
// Allocate and return a new file number
uint64_t NewFileNumber() { return next_file_number_++; }
...
}
BuildTable函数实现位于db/db_build.cc中,该函数产生了SSTable文件。
Status BuildTable(const std::string& dbname,
Env* env,
const Options& options,
TableCache* table_cache,
Iterator* iter,
FileMetaData* meta) {
Status s;
meta->file_size = 0;
iter->SeekToFirst();
std::string fname = TableFileName(dbname, meta->number);
if (iter->Valid()) {
WritableFile* file;
s = env->NewWritableFile(fname, &file);
if (!s.ok()) {
return s;
}
TableBuilder* builder = new TableBuilder(options, file);
meta->smallest.DecodeFrom(iter->key());
/*遍历MemTable的跳表,按照key的大小,有序地插入SSTable*/
for (; iter->Valid(); iter->Next()) {
Slice key = iter->key();
meta->largest.DecodeFrom(key);
builder->Add(key, iter->value());
}
// Finish and check for builder errors
/*所有的key value pair插入后,调用Finish,按照SSTable中讲的那样,加上metaindex block, index block和footer*/
if (s.ok()) {
s = builder->Finish();
if (s.ok()) {
meta->file_size = builder->FileSize();
assert(meta->file_size > 0);
}
} else {
builder->Abandon();
}
delete builder;
// Finish and check for file errors
/*写入文件,并且sync*/
if (s.ok()) {
s = file->Sync();
}
if (s.ok()) {
s = file->Close();
}
delete file;
file = NULL;
if (s.ok()) {
// Verify that the table is usable
/*验证文件可用*/
Iterator* it = table_cache->NewIterator(ReadOptions(),
meta->number,
meta->file_size);
s = it->status();
delete it;
}
}
// Check for input iterator errors
if (!iter->status().ok()) {
s = iter->status();
}
if (s.ok() && meta->file_size > 0) {
// Keep it
} else {
env->DeleteFile(fname);
}
return s;
}
至此,我们终于看到了磁盘上的SSTable文件是从哪里来的。接下来的任务还是很重的,要理解第二步计算level。
新产生出来的sstable 并不一定总是处于level 0, 尽管大多数情况下,处于level 0。新创建的出来的sstable文件应该位于那一层呢? 由PickLevelForMemTableOutput 函数来计算:
从策略上要尽量将新compact的文件推至高level,毕竟在level 0 需要控制文件过多,compaction IO和查找都比较耗费,另一方面也不能推至过高level,一定程度上控制查找的次数,而且若某些范围的key更新比较频繁,后续往高层compaction IO消耗也很大。 所以PickLevelForMemTableOutput就是个权衡折中。
如果新生成的sstable和Level 0的sstable有交叠,那么新产生的sstable就直接加入level 0,否则根据一定的策略,向上推到Level1 甚至是Level 2,但是最高推到Level2,这里有一个控制参数:kMaxMemCompactLevel。
// Maximum level to which a new compacted memtable is pushed if it
// does not create overlap. We try to push to level 2 to avoid the
// relatively expensive level 0=>1 compactions and to avoid some
// expensive manifest file operations. We do not push all the way to
// the largest level since that can generate a lot of wasted disk
// space if the same key space is being repeatedly overwritten.
static const int kMaxMemCompactLevel = 2;
int Version::PickLevelForMemTableOutput(
const Slice& smallest_user_key,
const Slice& largest_user_key) {
int level = 0;
/*如果和Level 0中的SSTable文件由重叠,直接返回 level = 0 */
if (!OverlapInLevel(0, &smallest_user_key, &largest_user_key)) {
// Push to next level if there is no overlap in next level,
// and the #bytes overlapping in the level after that are limited.
InternalKey start(smallest_user_key, kMaxSequenceNumber, kValueTypeForSeek);
InternalKey limit(largest_user_key, 0, static_cast<ValueType>(0));
std::vector<FileMetaData*> overlaps;
/*while 循环寻找合适的level层级,最大level为2,不能更大*/
while (level < config::kMaxMemCompactLevel) {
if (OverlapInLevel(level + 1, &smallest_user_key, &largest_user_key)) {
break;
}
if (level + 2 < config::kNumLevels) {
// Check that file does not overlap too many grandparent bytes.
GetOverlappingInputs(level + 2, &start, &limit, &overlaps);
const int64_t sum = TotalFileSize(overlaps);
if (sum > MaxGrandParentOverlapBytes(vset_->options_)) {
break;
}
}
level++;
}
}
return level;
}
整体的流程如下:

为什么可以轻松的判断和不同Level的文件有没有重叠,原因有两点:
- SSTable中的key-pair是有序的,给我一个最小的key和一个最大的key,就足以描述该文件中key的范围
- 数据结构 FileMetaData,描述了各个文件的名字,最小key 最大key,文件的大小等信息。
class Version {
...
// List of files per level
std::vector<FileMetaData*> files_[config::kNumLevels];
...
}