前言
上一节讲了LogAndApply的一部分:
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
Finalize(v);
我们结下来讲剩下的部分,因为剩下的部分和MANIFEST文件的内容有关系,所以单拎出来讲。
Ceph的mon会记录一些信息到LevelDB,我们曾经遇到过ceph-mon无法启动,原因是MANIFEST文件损坏:

如果MANIFEST文件损坏,或者干脆删除掉,leveldb能否恢复? 答案是肯定的。
import leveldb
ret = leveldb.RepairDB('/data/mon.iecvq/store.db')
MANIFEST损坏,为什么可以修复,修复原理是什么?
这都是本文要解决的问题。
VersionEdit and MANIFEST
VersionEdit和MANIFEST文件到底是什么关系?
VersionEdit会保存在MANIFEST文件中。
private:
friend class VersionSet;
typedef std::set< std::pair<int, uint64_t> > DeletedFileSet;
std::string comparator_;
uint64_t log_number_;
uint64_t prev_log_number_;
uint64_t next_file_number_;
SequenceNumber last_sequence_;
bool has_comparator_;
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
std::vector< std::pair<int, InternalKey> > compact_pointers_;
DeletedFileSet deleted_files_;
std::vector< std::pair<int, FileMetaData> > new_files_;
VersionEdit有上面的成员,LevelDB会在合适的时机将VerisonEdit的内容序列化到MANIFEST文件:
enum Tag {
kComparator = 1,
kLogNumber = 2,
kNextFileNumber = 3,
kLastSequence = 4,
kCompactPointer = 5,
kDeletedFile = 6,
kNewFile = 7,
// 8 was used for large value refs
kPrevLogNumber = 9
};
每一个VersionEdit,会首先EncodeTo,然后将内容作为一笔记录添加到MANIFEST文件。注意MANIFEST文件生成和log文件的生成是一样的。
在LogAndApply中,当生成新的Version之后,会调用如下内容,将VersionEdit的内容,即两个版本的差异记录在MANIFEST文件中:
std::string record;
/*先调用VersionEdit的 EncodeTo方法,序列化成字符串*/
edit->EncodeTo(&record);
/*注意,descriptor_log_是log文件*/
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());
}
注意,本质上说,MANIFEST文件是log类型的文件,即leveldb之log中提到的那种格式。
OK,我们接下来看下VersionEdit如何通过EncodeTo函数序列化:
void VersionEdit::EncodeTo(std::string* dst) const {
/*将比较器的标识和名称放入序列化字符串中*/
if (has_comparator_) {
PutVarint32(dst, kComparator);
PutLengthPrefixedSlice(dst, comparator_);
}
/*将日志文件编号的标识和名称放入序列化字符串中*/
if (has_log_number_) {
PutVarint32(dst, kLogNumber);
PutVarint64(dst, log_number_);
}
/*将前一个日志的标识和名称放入序列化字符串中*/
if (has_prev_log_number_) {
PutVarint32(dst, kPrevLogNumber);
PutVarint64(dst, prev_log_number_);
}
/* 将下一个文件的标识和名称放入序列化字符串中 */
if (has_next_file_number_) {
PutVarint32(dst, kNextFileNumber);
PutVarint64(dst, next_file_number_);
}
/*上一个序列号的标识和名称放入序列化字符串中*/
if (has_last_sequence_) {
PutVarint32(dst, kLastSequence);
PutVarint64(dst, last_sequence_);
}
/*将每个压缩点的标识,层次和InternalKey放入序列化字符串*/
for (size_t i = 0; i < compact_pointers_.size(); i++) {
PutVarint32(dst, kCompactPointer);
PutVarint32(dst, compact_pointers_[i].first); // level
PutLengthPrefixedSlice(dst, compact_pointers_[i].second.Encode());
}
/*删除文件部分*/
for (DeletedFileSet::const_iterator iter = deleted_files_.begin();
iter != deleted_files_.end();
++iter) {
PutVarint32(dst, kDeletedFile);
PutVarint32(dst, iter->first); // level
PutVarint64(dst, iter->second); // file number
}
/*新增文件部分*/
for (size_t i = 0; i < new_files_.size(); i++) {
const FileMetaData& f = new_files_[i].second;
PutVarint32(dst, kNewFile);
PutVarint32(dst, new_files_[i].first); // level
PutVarint64(dst, f.number);
PutVarint64(dst, f.file_size);
PutLengthPrefixedSlice(dst, f.smallest.Encode());
PutLengthPrefixedSlice(dst, f.largest.Encode());
}
}
上述流程入下图所示:
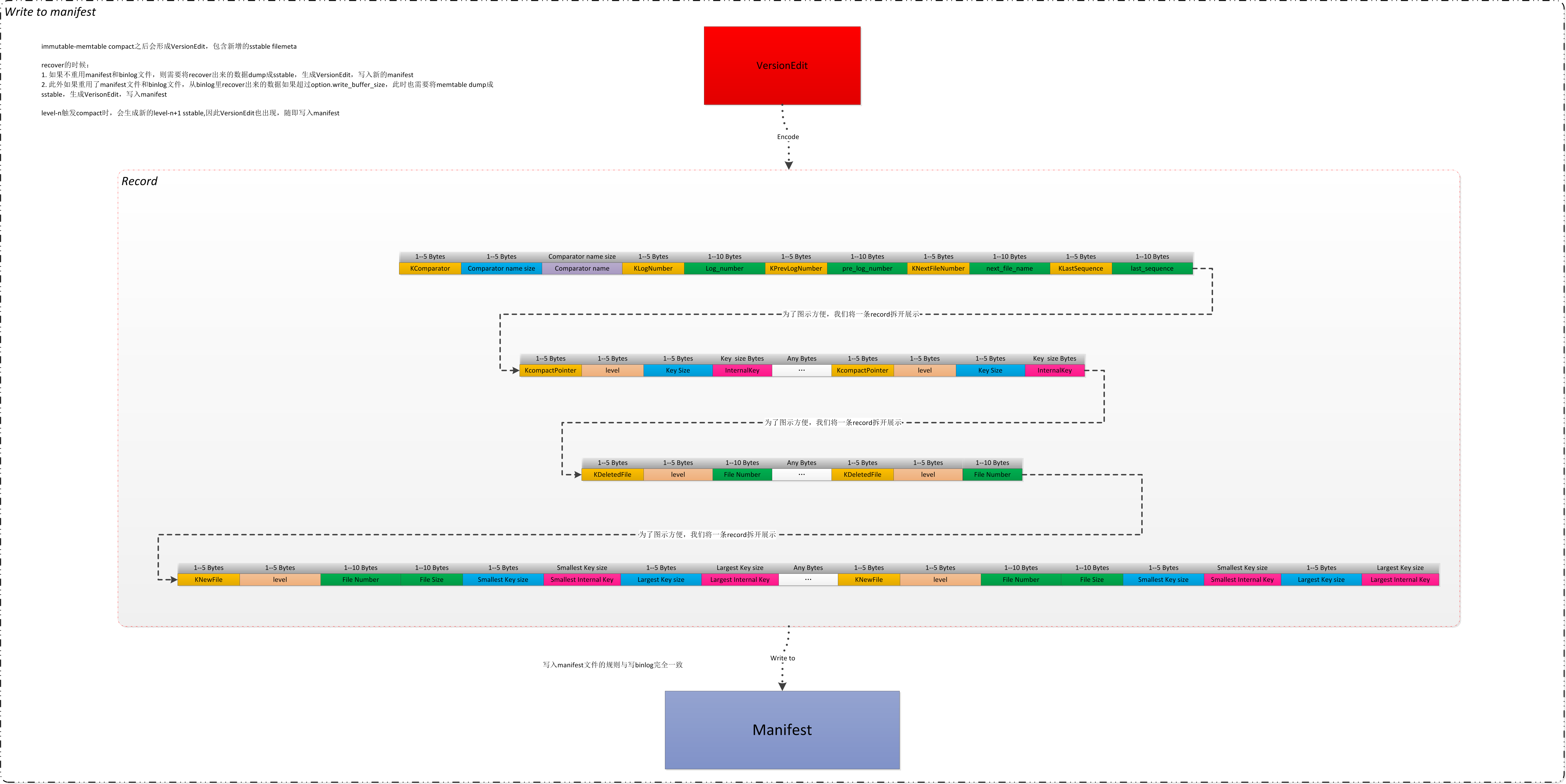
当正常运行期间,每当调用LogAndApply的时候,都会将VersionEdit作为一笔记录,追加写入到MANIFEST文件。
注意,VersionEdit可以序列化,存进MANIFEST文件,同样道理,MANIFEST中可以将VersionEdit一个一个的重放出来。这个重放的目的,是为了得到当前的Version 以及VersionSet。
一般来讲,当打开的DB的时候,需要获得这种信息,而这种信息的获得,靠的就是所有VersionEdit 按照次序一一回放,生成当前的Version。
Status VersionSet::Recover(bool *save_manifest) {
struct LogReporter : public log::Reader::Reporter {
Status* status;
virtual void Corruption(size_t bytes, const Status& s) {
if (this->status->ok()) *this->status = s;
}
};
// Read "CURRENT" file, which contains a pointer to the current manifest file
std::string current;
Status s = ReadFileToString(env_, CurrentFileName(dbname_), ¤t);
if (!s.ok()) {
return s;
}
if (current.empty() || current[current.size()-1] != '\n') {
return Status::Corruption("CURRENT file does not end with newline");
}
current.resize(current.size() - 1);
/*CURRENT文件记录着MANIFEST的文件名字,名字为MANIFEST-number */
std::string dscname = dbname_ + "/" + current;
SequentialFile* file;
s = env_->NewSequentialFile(dscname, &file);
if (!s.ok()) {
return s;
}
bool have_log_number = false;
bool have_prev_log_number = false;
bool have_next_file = false;
bool have_last_sequence = false;
uint64_t next_file = 0;
uint64_t last_sequence = 0;
uint64_t log_number = 0;
uint64_t prev_log_number = 0;
Builder builder(this, current_);
{
LogReporter reporter;
reporter.status = &s;
log::Reader reader(file, &reporter, true/*checksum*/, 0/*initial_offset*/);
Slice record;
std::string scratch;
/*文件中一条记录一条记录的读出,并DecodeFrom,生成VersionEdit */
while (reader.ReadRecord(&record, &scratch) && s.ok()) {
VersionEdit edit;
s = edit.DecodeFrom(record);
if (s.ok()) {
if (edit.has_comparator_ &&
edit.comparator_ != icmp_.user_comparator()->Name()) {
s = Status::InvalidArgument(
edit.comparator_ + " does not match existing comparator ",
icmp_.user_comparator()->Name());
}
}
if (s.ok()) {
/*按照次序,讲Verison的变化量层层回放,最重会得到最终版本的Version*/
builder.Apply(&edit);
}
if (edit.has_log_number_) {
log_number = edit.log_number_;
have_log_number = true;
}
if (edit.has_prev_log_number_) {
prev_log_number = edit.prev_log_number_;
have_prev_log_number = true;
}
if (edit.has_next_file_number_) {
next_file = edit.next_file_number_;
have_next_file = true;
}
if (edit.has_last_sequence_) {
last_sequence = edit.last_sequence_;
have_last_sequence = true;
}
}
}
delete file;
file = NULL;
if (s.ok()) {
if (!have_next_file) {
s = Status::Corruption("no meta-nextfile entry in descriptor");
} else if (!have_log_number) {
s = Status::Corruption("no meta-lognumber entry in descriptor");
} else if (!have_last_sequence) {
s = Status::Corruption("no last-sequence-number entry in descriptor");
}
if (!have_prev_log_number) {
prev_log_number = 0;
}
MarkFileNumberUsed(prev_log_number);
MarkFileNumberUsed(log_number);
}
if (s.ok()) {
Version* v = new Version(this);
/*通过回放所有的VersionEdit,得到最终版本的Version,存入v*/
builder.SaveTo(v);
// Install recovered version
Finalize(v);
/* AppendVersion将版本v放入VersionSet集合,同时设置curret_等于v */
AppendVersion(v);
manifest_file_number_ = next_file;
next_file_number_ = next_file + 1;
last_sequence_ = last_sequence;
log_number_ = log_number;
prev_log_number_ = prev_log_number;
// See if we can reuse the existing MANIFEST file.
if (ReuseManifest(dscname, current)) {
// No need to save new manifest
} else {
*save_manifest = true;
}
}
return s;
}
首先CURRENT文件中记录的内容为对应MANIFEST文件的名字,比如MANIFEST-037896,根据这个名字可以找到正确的MANIFEST文件。因为MANIFEST文件是log文件,因此可以一条记录一条记录的读出来。
读出来的内容是VersionEdit 通过EncodeTo序列化过的内容,因此,可以反序列化,得到VersionEdit:
Status VersionEdit::DecodeFrom(const Slice& src) {
Clear();
Slice input = src;
const char* msg = NULL;
uint32_t tag;
// Temporary storage for parsing
int level;
uint64_t number;
FileMetaData f;
Slice str;
InternalKey key;
while (msg == NULL && GetVarint32(&input, &tag)) {
switch (tag) {
case kComparator:
if (GetLengthPrefixedSlice(&input, &str)) {
comparator_ = str.ToString();
has_comparator_ = true;
} else {
msg = "comparator name";
}
break;
case kLogNumber:
if (GetVarint64(&input, &log_number_)) {
has_log_number_ = true;
} else {
msg = "log number";
}
break;
case kPrevLogNumber:
if (GetVarint64(&input, &prev_log_number_)) {
has_prev_log_number_ = true;
} else {
msg = "previous log number";
}
break;
case kNextFileNumber:
if (GetVarint64(&input, &next_file_number_)) {
has_next_file_number_ = true;
} else {
msg = "next file number";
}
break;
case kLastSequence:
if (GetVarint64(&input, &last_sequence_)) {
has_last_sequence_ = true;
} else {
msg = "last sequence number";
}
break;
case kCompactPointer:
if (GetLevel(&input, &level) &&
GetInternalKey(&input, &key)) {
compact_pointers_.push_back(std::make_pair(level, key));
} else {
msg = "compaction pointer";
}
break;
case kDeletedFile:
if (GetLevel(&input, &level) &&
GetVarint64(&input, &number)) {
deleted_files_.insert(std::make_pair(level, number));
} else {
msg = "deleted file";
}
break;
case kNewFile:
if (GetLevel(&input, &level) &&
GetVarint64(&input, &f.number) &&
GetVarint64(&input, &f.file_size) &&
GetInternalKey(&input, &f.smallest) &&
GetInternalKey(&input, &f.largest)) {
new_files_.push_back(std::make_pair(level, f));
} else {
msg = "new-file entry";
}
break;
default:
msg = "unknown tag";
break;
}
}
if (msg == NULL && !input.empty()) {
msg = "invalid tag";
}
Status result;
if (msg != NULL) {
result = Status::Corruption("VersionEdit", msg);
}
return result;
}
这个DecodeFrom没啥好说的,就是EncodeTo的反过程。
我们看下MANIFEST Decode之后得到的VersionEdit:
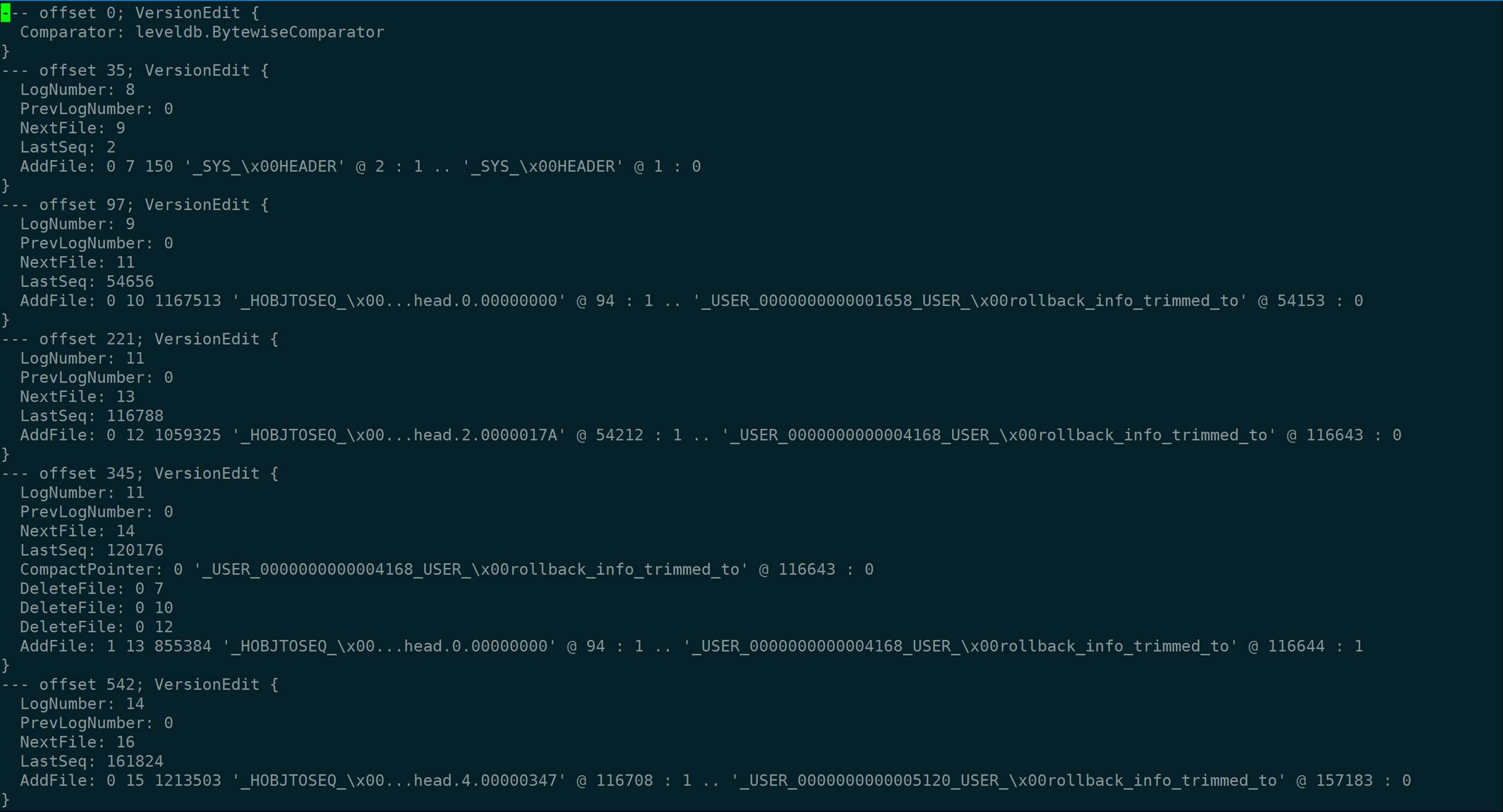
VersionSet::Recover函数中,回放完毕,生成了一个最终版的Verison v,Finalize之后,调用了AppendVersion,这个函数很有意思,事实上,LogAndApply讲VersionEdit写入MANIFEST文件之后,也调用了AppendVersion,如下所示:
// Unlock during expensive MANIFEST log write
{
mu->Unlock();
// Write new record to MANIFEST log
if (s.ok()) {
std::string record;
/*将当前VersionEdit Encode,作为记录,写入MANIFEST*/
edit->EncodeTo(&record);
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
/*调用Sync持久化*/
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());
}
}
// If we just created a new descriptor file, install it by writing a
// new CURRENT file that points to it.
if (s.ok() && !new_manifest_file.empty()) {
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
// Install the new version
if (s.ok()) {
/* 新的版本已经生成(通过current_和VersionEdit), VersionEdit也已经写入MANIFEST,
* 此时可以将v设置成current_, 同时将最新的version v链入VersionSet的双向链表*/
AppendVersion(v);
log_number_ = edit->log_number_;
prev_log_number_ = edit->prev_log_number_;
} else {
delete v;
if (!new_manifest_file.empty()) {
delete descriptor_log_;
delete descriptor_file_;
descriptor_log_ = NULL;
descriptor_file_ = NULL;
env_->DeleteFile(new_manifest_file);
}
}
return s;
AppendVersion的实现如下所示:
void VersionSet::AppendVersion(Version* v) {
// Make "v" current
assert(v->refs_ == 0);
assert(v != current_);
if (current_ != NULL) {
current_->Unref();
}
current_ = v;
v->Ref();
// Append to linked list
v->prev_ = dummy_versions_.prev_;
v->next_ = &dummy_versions_;
v->prev_->next_ = v;
v->next_->prev_ = v;
}
所以current_版本的更替时机一定要注意到,LogAndApply生成新版本之后,同时将VersionEdit记录到MANIFEST文件之后。
MANIFEST丢失或者损坏,leveldb如何恢复
如果只有MANIFEST文件损坏,或者干脆误删除,leveldb是可以恢复的。这是结论,事实上这两种实验我都已经做过了。
使用python-leveldb,通过如下手段可以修复Leveldb
import leveldb
ret = leveldb.RepairDB('/data/mon.iecvq/store.db')
为什么MANIFEST损坏或者丢失之后,依然可以恢复出来?LevelDB如何做到。
对于LevelDB而言,修复过程如下:
- 首先处理log,这些还未来得及写入的记录,写入新的.sst文件
- 扫描所有的sst文件,生成元数据信息:包括number filesize, 最小key,最大key
- 根据这些元数据信息,将生成新的MANIFEST文件。
第三步如何生成新的MANIFEST? 因为sstable文件是分level的,但是很不幸,我们无法从名字上判断出来文件属于哪个level。第三步处理的原则是,既然我分不出来,我就认为所有的sstale文件都属于level 0,因为level 0是允许重叠的,因此并没有违法基本的准则。
当修复之后,第一次Open LevelDB的时候,很明显level 0 的文件可能远远超过4个文件,因此会Compaction。 又因为所有的文件都在Level 0 这次Compaction无疑是非常沉重的。它会扫描所有的文件,归并排序,产生出level 1文件,进而产生出其他level的文件。
从上面的处理流程看,如果只有MANIFEST文件丢失,其他文件没有损坏,LevelDB是不会丢失数据的,原因是,LevelDB既然已经无法将所有的数据分到不同的Level,但是数据毕竟没有丢,根据文件的number,完全可以判断出文件的新旧,从而确定不同sstable文件中的重复数据,which是最新的。经过一次比较耗时的归并排序,就可以生成最新的levelDB。
上述的方法,从功能的角度看,是正确的,但是效率上不敢恭维。Riak曾经测试过78000个sstable 文件,490G的数据,大家都位于Level 0,归并排序需要花费6 weeks,6周啊,这个耗时让人发疯的。
Riak 1.3 版本做了优化,改变了目录结构,对于google 最初版本的LevelDB,所有的文件都在一个目录下,但是Riak 1.3版本引入了子目录, 将不同level的sst 文件放入不同的子目录:
sst_0
sst_1
...
sst_6
有了这个,重新生成MANIFEST自然就很简单了,同样的78000 sstable文件,Repair过程耗时是分钟级别的。
MANIFEST 文件的增长和重新生成
存在一个问题不知道大家有没有意识到,随着时间的流逝,发生Compact的机会越来越多,Version跃升的次数越多,自然VersionEdit出现的次数越来越多,而每一个VersionEdit都会记录到MANIFEST,这必然会造成MANIFEST文件不断变大。
ceph社区早就发现了这个问题, 有一个很bug是这么描述的:
BUG #5175 leveldb: LOG and MANIFEST file grow without bound (LOG being _text_ log !)
Description
leveldb has two files that seem to grow without bound and are only cleared on db open.
The first is the LOG file which is a textual debug log that leveldb creates. It's opened when the db is opened
and is never closed or cycled (and leveldb doesn't have any method to make it cycle other than close/reopen).
To make matter worse, if this file is on XFS, it's subject to XFS pre-allocation (so each time the file size
reaches the currently on-disk allocated size, the allocated size doubles, and so you get used disk space of 2M/
4M/.../256M/512M giving big jumps in used disk space as reported by 'du -sh')
The second file is the MANIFEST file which grows a little at each compaction and is also only
trimmed on db open. For long running (i.e. weeks/month), those can actually grow quite a bit
(especially LOG). Note that the same issue exists on OSD as well but they seem to receive a whole lot less
updates than mon so it shows less.
MANIFEST文件和LOG文件一样,只要DB不关闭,这个文件一直在增长。我查看了我一个线上环境,MANIFEST文件已经膨胀到了205MB。
试试上,随着时间的流逝,早期的版本是没有意义的,我们没必要还原所有的版本的情况,我们只需要还原还活着的版本的信息。MANIFEST只有一个机会变小,抛弃早期过时的VersionEdit,给当前的VersionSet来个快照,然后从新的起点开始累加VerisonEdit。这个机会就是重新开启DB。
LevelDB的早期,只要Open DB必然会重新生成MANIFEST,哪怕MANIFEST文件大小比较小,这会给打开DB带来较大的延迟。
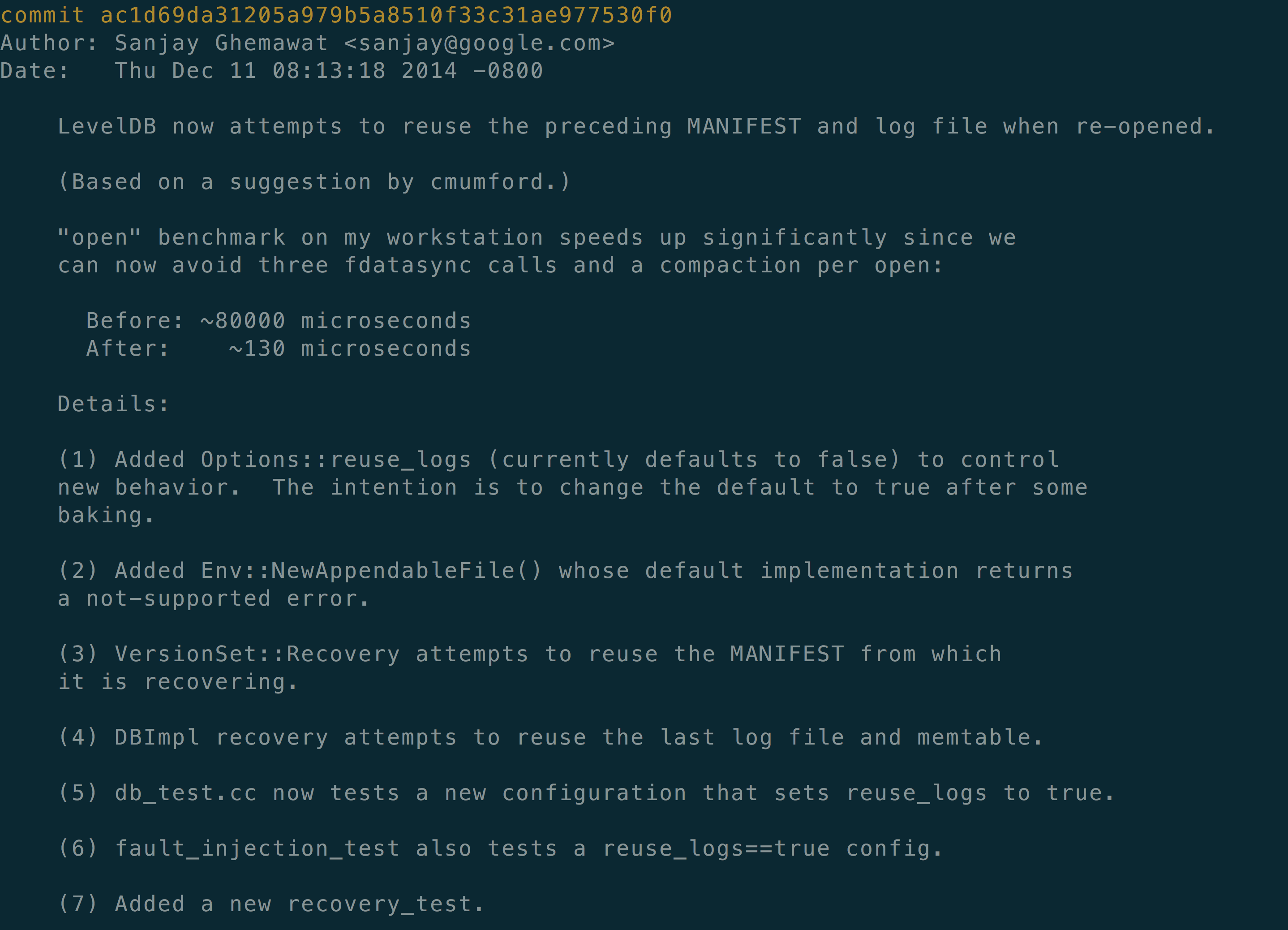
这个commit将Open DB的延迟从80毫秒降低到了0.13ms,效果非常明显,即优化之后,并不是每一次的Open都会带来 MANIFEST的重新生成。
在VersionSet::Recover函数中,会判断是否延用老的MANIFEST文件,判断逻辑如下:

bool VersionSet::ReuseManifest(const std::string& dscname,
const std::string& dscbase) {
if (!options_->reuse_logs) {
return false;
}
FileType manifest_type;
uint64_t manifest_number;
uint64_t manifest_size;
/*如果老的MANIFEST文件太大了,就不在延用,return false
*延用还是不延用的关键在如下语句:
descriptor_log_ = new log::Writer(descriptor_file_, manifest_size);
* 如果dscriptor_log_ 为NULL,当情况有变,发生了版本的跃升,有VersionEdit需要写入的MANIFEST的时候,
* 会首先判断descriptor_log_是否为NULL,如果为NULL,表示不要在延用老的MANIFEST了,要另起炉灶
* 所谓另起炉灶,即起一个空的MANIFEST,先要记下版本的Snapshot,然后将VersionEdit追加写入
*/
if (!ParseFileName(dscbase, &manifest_number, &manifest_type) ||
manifest_type != kDescriptorFile ||
!env_->GetFileSize(dscname, &manifest_size).ok() ||
// Make new compacted MANIFEST if old one is too big
manifest_size >= TargetFileSize(options_)) {
return false;
}
assert(descriptor_file_ == NULL);
assert(descriptor_log_ == NULL);
Status r = env_->NewAppendableFile(dscname, &descriptor_file_);
if (!r.ok()) {
Log(options_->info_log, "Reuse MANIFEST: %s\n", r.ToString().c_str());
assert(descriptor_file_ == NULL);
return false;
}
Log(options_->info_log, "Reusing MANIFEST %s\n", dscname.c_str());
descriptor_log_ = new log::Writer(descriptor_file_, manifest_size);
manifest_file_number_ = manifest_number;
return true;
}
这部分逻辑要和LogAndApply对照看:延用老的MANIFEST,那么就会执行如下的语句:
descriptor_log_ = new log::Writer(descriptor_file_, manifest_size);
manifest_file_number_ = manifest_number;
这个语句的结果是,当version发生变化,出现新的VersionEdit的时候,并不会新创建MANIFEST文件,正相反,会追加写入VersionEdit。
但是如果MANIFEST文件已经太大了,我们没必要保留全部的历史VersionEdit,我们完全可以以当前版本为基准,打一个SnapShot,后续的变化,以该SnapShot为基准,不停追加新的VersionEdit。
我们看下LogAndApply中的相关部分:
/* descriptor_log_ == NULL 对应的是不延用老的MANIFEST文件 */
if (descriptor_log_ == NULL) {
// No reason to unlock *mu here since we only hit this path in the
// first call to LogAndApply (when opening the database).
assert(descriptor_file_ == NULL);
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
edit->SetNextFile(next_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
descriptor_log_ = new log::Writer(descriptor_file_);
/*当前的版本情况打个快照,作为新MANIFEST的新起点8/
s = WriteSnapshot(descriptor_log_);
}
}
// Unlock during expensive MANIFEST log write
{
mu->Unlock();
// Write new record to MANIFEST log
if (s.ok()) {
std::string record;
edit->EncodeTo(&record);
s = descriptor_log_->AddRecord(record);
if (s.ok()) {
s = descriptor_file_->Sync();
}
if (!s.ok()) {
Log(options_->info_log, "MANIFEST write: %s\n", s.ToString().c_str());
}
}
// If we just created a new descriptor file, install it by writing a
// new CURRENT file that points to it.
if (s.ok() && !new_manifest_file.empty()) {
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
如果不延用老的MANIFEST文件,会生成一个空的MANIFEST文件,同时调用WriteSnapShot将当前版本情况作为起点记录到MANIFEST文件。
这种情况下,MANIFEST文件的大小会大大减少,就像自我介绍,完全可以自己出生起开始介绍起,完全不必从盘古开天辟地介绍起。
可惜的是,只要DB不关闭,MANIFEST文件就没有机会整理。因此对于ceph-mon这种daemon进程,MANIFEST文件的大小会一直增长,除非重启ceph-mon才有机会整理。